V2EX - 技术 |
- 想请大家帮忙跑一下这个 PHP 文件,看看我们设备差距有多少
- 如何快速向文件中写入 1 亿个 ip?
- 在 serverless computing 下,有哪些方向可以给程序员提供服务?这样范式下有什么痛点?
- Qbittorrent 性能参数校准
- 请教 MySQL8 建表使用 FEDERATED 引擎连接 MySQL5 的数据库表,提示 1492,Bad handshake...
- 怎么理解操作系统的 Peterson 算法的特殊情况
- udemy 上的课无法截图,是怎么做到的?
- 发现一个远程桌面串流神器,还可以当远程桌面。好流畅!延迟好低!但是有一点小问题
- 被 golang 坑了一下午, win 平台无法正常调用外部程序看这里。
- SQL Style
- paddlehub 使用 pyzmq 作为 GPU 服务后台是有什么独特的作用吗?
- 如何实现多线程计算组合数
- ASP.NET Core 通过 antiForgery.GetAndStoreTokens 生成的 CSRF Token 会被存储在服务器上吗?还是随机生成,仅校验是否和请求头相同?对所有 API 请求 verify 并 rotate
- Python 绘图的时候像这个图里面的两个竖线之间的双箭头是怎么加的?
- 生产环境 Redis 连接,长时间无响应被服务器断开问题
- 关于博客图片存储方案问题,直接保存在博客所在服务器、用第三方对象存储还是单独买一个便宜的服务器自己部署 OSS 服务?
- 有没有什么 APP 能将骑行的所有轨迹汇集到一张地图上?
- DataGrip 里使用脚本生成数据库
- LotusDB 设计与实现—1 基本概念
- Java 有什么非业务性的工作吗?
- 有没有类似 txt2re 的网站
- 算法工程师的开发环境都是什么样的?
- 请教大佬: mongo4.2 多个事务修改 document 报 WriteConflict
- ASP.NET Core 的 Cookie Authentication 使用的是什么密钥加密存在 Cookies 用户数据?安全性怎么样?
- enchilada 如何看电池健康度
- CPU 指令重排是 cache 同步太慢的表征么?
- cs 架构的程序,数据库连接串都是如何加密的?
- 如何把一段简单的代码变复杂?
- 电信 1000M 跑满的上网科学是如何做到的?
- 请教大佬: mongo4.2 多个事务修改 document 报 WriteConflict
- 不知道大家有没有遇到这种渲染 bug
- 国产安卓系统是不是都不内置 FCM?
- 如何编写代码才能实现这种关联
- Vue 3 的服务端与异步数据获取
- 腾讯公共 ntp 升级了
- 做了一个干货 Top 文章榜,求星
| 想请大家帮忙跑一下这个 PHP 文件,看看我们设备差距有多少 Posted: 09 Apr 2022 11:48 AM PDT 我最近一直在看二手区,想更新 PC 主机 刚好有个 V 友说写一亿个 IP 到文件中花费时间 我刚好在学习 PHP ,就用 PHP 写了一个 下载地址: http://175.178.215.195/ip.php 电脑装了 PHP 的 V 友有空可以帮跑一下,看看时间是多少,这样我可以比较直观地看出我电脑和其他设备的差距 我的总耗时大概是 6000 ms |
| Posted: 09 Apr 2022 11:28 AM PDT 背景:需要向一个文件中写入 1 亿个 ip ,最快的方法是什么?机器配置是 mac book,双核 cpu,8GB 内存。 我用 java 实现了一个多线程的写入,发现速度慢的要死(写入时间 5 分钟以上)。有没有人推荐一下速度写入大文件的方法,或者其他语言快速写入大文件的方案。 |
| 在 serverless computing 下,有哪些方向可以给程序员提供服务?这样范式下有什么痛点? Posted: 09 Apr 2022 11:03 AM PDT 在 serverless computing 下,有哪些方向可以给程序员提供服务?这样范式下有什么痛点?根据伯克利大学的预测未来十年,在 serverless computing 一定是未来,如果这样的话,随着技术的变更,一定也产生大量的开发需求,大家预测会有什什么样的需求产生呢? |
| Posted: 09 Apr 2022 10:53 AM PDT 随手糊了一篇文档。 |
| 请教 MySQL8 建表使用 FEDERATED 引擎连接 MySQL5 的数据库表,提示 1492,Bad handshake... Posted: 09 Apr 2022 10:25 AM PDT CONNECTION 的账户密码 IP ,库表路径反复核对过多次,不会错, |
| Posted: 09 Apr 2022 10:18 AM PDT
当进程 0 执行了 enter_region(0);,但还没有执行 leave_region 时。此时进程 1 去执行 enter_region(1);,会发现:
|
| Posted: 09 Apr 2022 09:26 AM PDT 试了好多种方法,snipaste ,windows 截屏键,还有 OBS 录频,都是一片黑色,好神奇 |
| 发现一个远程桌面串流神器,还可以当远程桌面。好流畅!延迟好低!但是有一点小问题 Posted: 09 Apr 2022 09:03 AM PDT 今天无意间刷到一个远程串流软件,parsec 。原理类似 steam link ,可以远程串流电脑画面,比一般的远程软件流畅很多很多,因为非常流畅。所以很多人拿来远程办公。在线剪辑这些的,于是我就试了一下。 Linux 客户端官方只做了 ubuntu 的兼容,而我用的是 manjaroKDE + Mac 。装的这个 yay -S parsec-bin 现在的问题是,Linux 可以连 Mac ,但是 Mac 不能连 manjaro ,因为 Linux 没有 host 这个模式(没有相关设置选项), mac 是 bugsur + amd 的显卡。manjaroKDE 是 gtx1070 显卡 |
| 被 golang 坑了一下午, win 平台无法正常调用外部程序看这里。 Posted: 09 Apr 2022 08:54 AM PDT 很简单的调用: 报错: ??? 啥玩意 ??? 本着出了问题先找自身原因的 感觉是转义出了问题,谷歌了半天,除了复制粘贴就没别的了。 米田共里淘金终于发现了一片文章:Go 在 windows 上调用本地进程传参时的一个天坑 MD ,最终 tm 还是 go 的问题,一直不敢往那想,属实被喷怕了。 摘抄一下:
反正我看不懂,看人家的解释:
改了一下代码: 解决。 学习 go 一段时间,觉得它的开发者很矛盾,比如三元运算符,很多人都想要它,但官方却以语法统一、可能会导致阅读困难之类的理由推脱。 但 不比你 if 要整洁易读? 对多字节的处理也很费劲,我到现在不知道怎样查找某个中文的位置,IndexRune 报错,也没谷歌到答案 是不是有人要说,爱用用,不用滚呢? |
| Posted: 09 Apr 2022 08:31 AM PDT 读《SQL for Data Analysis》,作者推荐的 SQL style ,觉得还挺有借鉴意义的。 "There is no single universally accepted SQL style, but you may find the SQL Style Guide and the Modern SQL Style Guide useful." |
| paddlehub 使用 pyzmq 作为 GPU 服务后台是有什么独特的作用吗? Posted: 09 Apr 2022 07:57 AM PDT 在学习 paddlehub 的服务部署,其中使用 gpu 实现服务时使用的是 ZMQ+FLask( https://github.com/PaddlePaddle/PaddleHub/issues/1726),这样处理是可以更好地以队列形式处理信息吗? 因为没用过消息队列,zmq 有可能被 kill 吗,是否应该加监听保证服务及时重启? |
| Posted: 09 Apr 2022 07:49 AM PDT 现在我想计算 80 里面取 20 个数的所有组合可能, 这个数据量比较大, 计算比较耗时, 享用多线程计算应该会快, 但是不知到多线程怎么写这个程序 https://stackoverflow.com/questions/9430568/generating-combinations-in-c 计算方法参考的这个链接 |
| Posted: 09 Apr 2022 07:29 AM PDT ASP.NET Core 通过 antiForgery.GetAndStoreTokens 生成的 CSRF Token 会被存储下来吗?还是随机生成,仅校验是否和请求头相同?对所有 API 请求 verify 并 rotate CSRF Token 对性能影响多大? |
| Python 绘图的时候像这个图里面的两个竖线之间的双箭头是怎么加的? Posted: 09 Apr 2022 06:44 AM PDT 就是这两个竖线之间,一个双箭头,然后右边有个数字表示距离
文字我知道可以用 这个双箭头是有什么函数么 |
| Posted: 09 Apr 2022 06:00 AM PDT 上个月线上生产环境有几个接口出现异常响应,查看生产日志后发现,如下错误 线上 Redis 客户端使用的是 一般情况下服务端断开连接都会发送 既然这里知道是 Redis 连接长时间无活动后被断开导致的 bug ,那怎么解决? 博主一开始以为重试可以解决,但是发现事情没有想象的简单。上代码 上面代码的意思是第一次查询 Redis 发生异常后,每隔 200 毫秒在查 3 次。当实际运行时,发现这里会提示三次 到这里这个问题的我的解决思路其实就是怎么在 Redis 连接发生异常后,怎么创建一条新的连接进行代替。 不多说直接上代码: 在用当前 Redis 连接获取数据发生异常超过 配合 到此生产环境这里
|
| 关于博客图片存储方案问题,直接保存在博客所在服务器、用第三方对象存储还是单独买一个便宜的服务器自己部署 OSS 服务? Posted: 09 Apr 2022 04:43 AM PDT 如题,之前是 gitee ,后来用不了了,只能考虑用其他方案 |
| Posted: 09 Apr 2022 02:47 AM PDT 有没有什么 APP 能将骑行的所有轨迹汇集到一张地图上? 我想要的是把自己所骑行过的路线,汇集在一张地图上。 |
| Posted: 09 Apr 2022 02:19 AM PDT 我现在在用 DataGrip,自己写一个 js 脚本文件,为数据库里所有表重成一个 Model 类.能运行,但用起来不太爽,主要是没有语法提示.甚至找不到一个帮助文档介绍一下 DataGrip 脚本引擎能提供的对象模型,只是照着例子琢磨,有没有高手介绍一下,是否有详细的文档,或者更好的做法? |
| Posted: 09 Apr 2022 02:11 AM PDT
LotusDB 是一个基于 LSM Tree 进行设计,并结合 B+ 树优势的单机 KV 存储引擎,读写性能稳定、快速。 在传统的 LSM Tree 架构中,增删数据均是追加有序写入到 SST 文件中,相同的 key 对应的数据可能存在多份,需要通过复杂的 compaction 策略来进行空间回收,这同时带来了空间放大和写放大问题。 LSM Tree 在磁盘上维护多级 SSTable 文件,在数据读取时,需要逐层扫描文件来查找指定的数据,最坏情况下需要扫描每一层的 SSTable ,读性能不稳定。 和 LSM Tree 相对应的,另一种常见的数据存储模型是 B+ Tree ,B+ 树由于有着很好的适配磁盘页的特性,在数据库存储引擎中广泛应用,例如最为人熟知的 Mysql 的 InnoDB 引擎。 B+ Tree 将数据维护在树最底层叶子节点中,读性能比较稳定,但是数据的插入和更新均是随机 IO 进行写入,导致 B+ Tree 的写性能相对较低。 我们知道,LSM 存储模型诞生于 HDD (机械硬盘) 时代,HDD 的随机和顺序读写速度差别巨大,所以 LSM 的设计最大限度的发挥了顺序 IO 的优势,所有的数据先到内存 buffer 里缓存,然后批量有序写入到文件中。但是随着存储硬件的更新迭代,磁盘的随机和顺序读写差别变小了,在一些介质中,顺序和随机读写甚至没有太大的差别。 LSM Tree 针对顺序 IO 的一些设计就会显得过于复杂,导致整个系统难以实现和控制(如果你熟悉 rocksdb 的话,就会深有体会)。 自行设计一个系统的底层存储引擎,比掌握一个复杂的项目要更加容易,出现了相关的问题也更容易定位和解决,这也是为什么 cockroach 采用自研的 Pebble 存储引擎替代 rocksdb ,而 LotusDB 就是一个这样可以轻易学习和掌握的存储引擎,因为它简洁、直观且高效。 LotusDB 的整体架构图如下: LotusDB 仍然保留了 LSM Tree 中的写流程,因为这能够最大限度的保证写入数据的持久性以及写吞吐,所以在磁盘上维护了 WAL 日志,新写入的数据先追加到 WAL 中保证数据不丢失,然后再写入到内存中。 内存中维护了多个跳表结构,最新的跳表叫做 active memtable ,一个 memtable 写满之后,会变为 immutable memtable ,即不可变的 memtable ,其不能接收新的写入,并且等待被后台线程 flush 到磁盘中。 Flush 的时候,数据索引信息会被存放到 B+ 树中,而 value 会被单独存放到 Value Log 中,value log 的结构类似于 WAL ,数据写入都是采用日志追加,只不过 value log 会有一个阈值,写满之后会打开一个新的 value log ,因此 value log 是存在多个的。 需要注意的是,B+ Tree 应该尽量存储新的存储介质中,例如固态硬盘,因为前面提到过 B+ 树是随机写入,如果使用传统机械硬盘的话,写性能受限制,写放大严重,Flush 可能会是一个瓶颈。 这就是 LotusDB 的整体实现,在这种实现下,我们来看看基本的数据读写流程是什么样的。 写一个 key/value:前面说过了,和 LSM 模型完全一致,先将 key/value 封装成一条日志追加到 WAL 中,然后将 k/v 写入到内存的 active memtable 。 根据 key 读一个 value:先在内存当中的 active memtable 和 immutable memtable 中依次查找,如果找到直接返回。否则说明 value 可能在磁盘中,就从 B+ 树获取 key 的索引信息,索引信息是一个二元组 <fid, offset>,标识 value 位于 value log 中具体哪个文件,以及文件中的位置,然后直接根据这个索引信息到 value log 文件中获取 value 即可。 最后再来总结下 LotusDB 架构的优点,简单归纳大概有如下几点: 1 、写数据流程和传统 LSM 模型完全一致,保证了顺序 IO 的高吞吐,以及数据持久性 2 、读性能相较于原生 LSM 模型更加稳定,读放大降低,因为引入了 B+ 树,得益于 B+ 树稳定的读性能,整体的读取效率会更加可控 3 、完全去除了 LSM Tree 模型中的多级 SSTable ,没有了 SSTable 的维护,并且采用已有的 B+ 树实现( BoltDB ),大大降低了系统的复杂性 4 、Compaction 对存储介质的损耗降低,LotusDB 中只有 value log 存在 Compaction ;原生 LSM 不仅 SSTable 需要 Compaction ,并且如果进行了 kv 分离的话,value log 也同样需要 Compaction 5 、读写流程简洁直观,没有 bloom filter 、block cache 等 LotusDB Github 地址:https://github.com/flower-corp/lotusdb |
| Posted: 09 Apr 2022 01:12 AM PDT 本人一直在做 Java Web 相关的业务开发。由于本人很喜欢 Java 这个语言,所以想着,如果不做业务开发,还能有什么工作是和 Java 相关的。 比如:
我的问题是,国内能找到哪些工作呢,比如 JVM 的开发,哪些公司需要吗,能远程吗,成都有类似工作机会吗(本人在成都,并不想去外地)。 上面那些著名的框架、工具,都是开源项目,并不像商业公司那样(选商业公司是因为还是需要赚钱养家糊口)。 当然,本人还有个想法是,做业务开发似乎有传说中的 35 岁危机(本人 31 ,还没经历到,所以是传言),做这种底层的项目,应该就没有这类问题,这也是一个原因。 |
| Posted: 09 Apr 2022 12:57 AM PDT 有没有类似 txt2re 的网站 txt2re 可根据你提供的字符串,由你自己选择匹配那些字符,且按照什么模式去匹配,然后就可以获得一个表达式。 https://txt2re.com/index3_s_42_43_2.html 网站停止服务了,找了几个都不好用。 |
| Posted: 08 Apr 2022 10:57 PM PDT 各位算法工程师,你们平时在公司内部开发模型,做实验,上线模型的环境是什么样的?方便分享一下经验吗? 我们最近想在内部统一开发环境,这是我们初步的构想:
这套东西看起来很美好,就是组件比较多,比较大的依赖 kubeflow 这个项目,这个项目的成熟度不知如何。 不知道大家有什么最佳实践可以分享吗?公司属于中小规模,没有什么历史负担。已经在使用 k8s ,业务主要是提供各种定制化的 AI 服务 API ,所以对上线速度和开发效率比较看重。 谢谢 |
| 请教大佬: mongo4.2 多个事务修改 document 报 WriteConflict Posted: 08 Apr 2022 08:44 PM PDT ps:我的业务确实要并发修改同一个 document 我看网上有两种解决方案 请问大佬有什么好的建议吗,感谢感谢 |
| ASP.NET Core 的 Cookie Authentication 使用的是什么密钥加密存在 Cookies 用户数据?安全性怎么样? Posted: 08 Apr 2022 06:59 PM PDT https://docs.microsoft.com/en-us/aspnet/core/security/authentication/cookie 单页应用,不想用 Identity 。 |
| Posted: 08 Apr 2022 02:24 PM PDT 感觉 enchilada 的电池不经用了,又找不到哪里看电池健康度,哪位高手介绍一下。 |
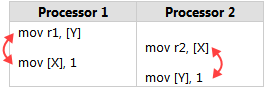
| Posted: 08 Apr 2022 02:08 PM PDT 最近想加深一下对 CPU core 之间的缓存同步,内存模型的理解,读了一些文章。在此之前,我知道除了编译器以外,多核 CPU 也是可以对指令进行重排的,比如下图中两个核心的指令,如果没有重排的话,
实际情况下,CPU 是可以把指令重排成如下顺序,以至于
但标准又说了,在单核的情况下,这种重排是不可能发生的。由此我联想到了 MESI 协议,CPU 在不同核之间,MESI 协议保证了缓存生效 /失效。 请问是否可以这么理解,CPU 某个核心上的指令重排现象(上图 CPU2 上)是否只是因为 MESI 消息太慢导致的的表征?实际上 CPU2 还是按照既定的指令顺序执行,还是说 CPU2 真的就是调换了两个指令的顺序呢? |
| Posted: 08 Apr 2022 12:41 PM PDT 1 cs 架构,数据库连接串要保存在本地,或者放在 web 上。base64 太弱了。aes 或者 des 也很容易破解吧,因为你要告诉程序如何解密吧。rsa 类似,密钥要写在程序里。如何防止数据库访问用户名密码被破解? |
| Posted: 08 Apr 2022 12:34 PM PDT 这问题你应该去问企业级 Java 架构师。 就比如 print 一句 hello world 吧。main 函数里 print 一下?太面向过程,太 low 了。 得封装一个类。叫 Printer. Printer 有个成员方法,叫 print 。 但是!光一个类太 low 了,以后要是有不同的实现怎么办?所以得加一个接口。PrinterInterface 。 但是! interface 是没有实现的,还是要有默认实现才行。所以得加个虚拟类,AbstractPrinter 实现 PrinterInterface ,然后 Printer 继承 AbstractPrinter 。 但是!你有了那么一套,该怎么创建实例呢?直接 new Printer()?太 low 了,那叫实现依赖。肯定不行的,所以要搞一个工厂类,PrinterFactory ,PrinterFactory 用 PrinterInterface 返回实例,这样就隐藏了实现细节了。 但是! PrinterFactory 本身也是实现类啊,太 low 了,所以得有 PrinterFactoryInterface, AbstractPrinterFactory. 而且在 PrinterFactory 里面该怎么写呢?直接 new Printer()? 太 low 了。还是实现依赖。 最后,你要把这一堆玩意在代码里组装起来,也太难看了,各种 new 实现类。太 low ! 好在我们有个高级玩意,叫依赖注入!把程序对象结构全写到配置文件里面。这一套当然是不能自己造轮子的。配置 Spring 吧。搞了那么多 lib ,靠命令行或者 IDE 的项目管理肯定不够啊,得有依赖管理。Maven 啊 Gradle 啊使劲上。 最最后,要 print 的东西怎么传给程序呢?硬编码?命令行传参数?太 low !当然得写在 XML 里头。 光是 XML 当然还不够企业级,再加上 DTD 验证吧。 然后就涉及到了 XML 解析的问题了。代码里直接操起 parser 吗?太 low! 当然要写个 parser 的包装类,interface, abstract class, implementation class, factory class 再来一套。毕竟,不能依赖实现啊,以后我要是换 parser 了怎么办。 所以最后是成品是一堆配置文件,一堆 jar ,compile 出来的程序 200MB 。 IDE 得装上 300 个插件,打开项目硬盘响老半天吃掉 2GB 内存,然后一堆插件弹提示要求升级。 哦对了,在这一切发生之前,还得画 UML 图呢。 三年后项目完工了,部署到客户的服务器上一跑,立马崩溃,一地的 stack trace 。原来客户服务器上用的是 JDK 5 而新项目需要 JDK 6. 然后问客户你们不能升级吗,答案是不行,因为另外一个企业级开发组给做的企业级解决方案只支持 JDK 5 。接着客户把你们的架构师臭骂了一顿,你搞了那么多设计就没有想过可能会换 JDK 吗? |
| Posted: 08 Apr 2022 09:35 AM PDT 为啥可以那么牛,还那么嚣张? 没人管吗? |
| 请教大佬: mongo4.2 多个事务修改 document 报 WriteConflict Posted: 08 Apr 2022 08:09 AM PDT ps:我的业务确实要并发修改同一个 document 我看网上有两种解决方案 1.比如修改 maxTransactionLockRequestTimeoutMillis=36000000 2.应用层限制,比如实现排队系统 请问大佬有什么好的建议吗,感谢感谢 |
| Posted: 08 Apr 2022 08:06 AM PDT 因为暂时没法主动复现,所以不能截图,我尽量描述得清楚一点。。 举一个例子,比如下面是一行代码,"|"表示光标所在的位置。 这时候按一次BackSpace (退格键),就直接变成这样了: 这时候输入任意一个键,比如".",就又会变成这样: 感觉就是实际的内容和 vscode 渲染出来的不一致,紊乱。然后 reload window 一下就又好了。 装了很多插件。。也可能是 neovim 插件的问题,这 bug 偶尔触发所以一时半会也没法排错 |
| Posted: 08 Apr 2022 07:15 AM PDT 第一次玩国产 ROM 。我的联想拯救者 Y700 运行的是联想 ZUI 13 。我可以直接从 ZUI 应用商店安装 Google Play ,然后从 Google Play 安装各种 app ,但是安装的 GMail 、Telegram 等等都只能在后台运行的状态下接收推送通知。是不是国产安卓都不带 FCM ?我看 Google Play Services 也是安装了的。有办法不用在后台跑 app 接收推送通知么? |
| Posted: 08 Apr 2022 06:56 AM PDT 比如有 django model 类 有 Table 类对象 tab ,我们在调用 tab 的 mgr 属性时 |
| Posted: 08 Apr 2022 06:06 AM PDT 最近项目才上线, 打算修一下 SSR 半残的状态. 以下内容是根据实践得出的结论, 不过我还是有点迷糊, 所以分享出来给大家看一下, 如果有错误或者有什么想法可以在下面指正. 内容基于使用 setup script 的情况. 几个基本点:
几个建议:
|
| Posted: 08 Apr 2022 05:01 AM PDT 新域名 ntp.tencent.com 看起来同步效果还是比较好的 |
| Posted: 08 Apr 2022 03:12 AM PDT |
 我理解正常一个进程的程序是这样写的:
我理解正常一个进程的程序是这样写的: 但是现在有这种特殊情况:
但是现在有这种特殊情况: 也就是说没办法当主机,只能当客户端连接别人,不能被连接,很喜欢这个软件,有办法解决吗?或者有没有类似的软件?
也就是说没办法当主机,只能当客户端连接别人,不能被连接,很喜欢这个软件,有办法解决吗?或者有没有类似的软件?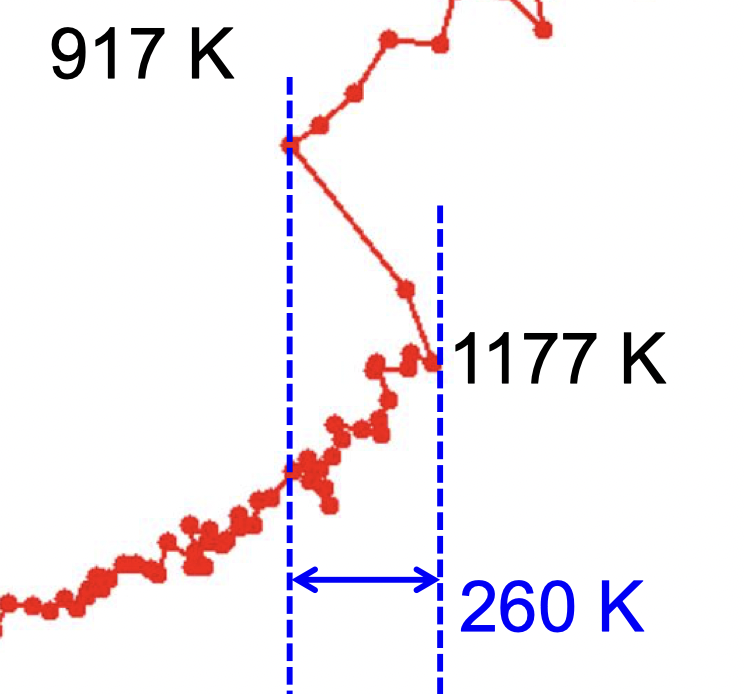




| You are subscribed to email updates from V2EX - 技术. To stop receiving these emails, you may unsubscribe now. | Email delivery powered by Google |
| Google, 1600 Amphitheatre Parkway, Mountain View, CA 94043, United States | |
No comments:
Post a Comment