V2EX - 技术 |
- [弱弱的问一句] :做嵌入式开发的 V 友多吗? 搞 Hisilicon 海思方案 IPCAM、DVR、NVR、XVR 产品开发的人呢
- 是否有必要买一台 4000+ NAS
- 美团外卖的程序员都不验证服务器时间吗?
- 项目的前期架构是否要反复的揣摩一套体系?
- 部署静态网站+备案+自动 https,哪个平台最友好?不想一堆配置、管理服务器
- Go sync.Pool 浅析
- ubuntu 用 smb 挂载 truenas 的文件夹,挂载完之后文件夹上面有一个小锁的标志,只有管理员能写入和修改文件,这是咋回事。我在 truenas 里面已经分配了任何人都可以写入的权限了,并且 Mac os 测试可以正常读写
- 我们需要什么样的帮助,由“前端收徒”想到的
- github 上面的项目, star 后,可以打标签/tag 么?否则,大家怎么找到自己关注的项目?
- TieJS: 一个基于 TypeScript 的个人级 Node.js 框架
- 给同事讲 Python 的高级用法, 有没有提纲什么的...
- redis 读从节点
- 为什么 gevent 没有封装 epoll 呢,看只实现了 poll 和 select
- 在广州海珠区做安卓的兄 Dei,最近想换一份工作的看这里
- Python 的 gil 到底解决了什么具体的问题?
- pandas 有那种根据开头匹配合并的函数吗?
- 今天有多少用户的 263 企业邮箱崩了的
- 大专学习计算机毕业了
- Arthas 3.5.1 发布:神级特性!内存搜索对象
- 闲鱼图片视频上传接口
- 如何为游戏排行榜设计对应的数据库
- 同一个包在 dependencies 和 peerDependencies 中的版本不一致
- 怎么感觉看代码好难呀
- 求个把富文本转成 word 的办法
- windows 自带微软拼音输入法 热键占用问题 Ctrl+.
- 手机 APP 大面积闪退系统无限重启,魅族这是已经放弃治疗了?
- 大家遇到过配置 dns 解析超过 48 小时还没生效的情况么?
- 各位有没有买过护眼的显示器?买过能发一下购买链接吗?
- 除了 Amazon Transcribe (AWS), 有无其他能对法语德语音频进行转写的软件或者云服务?
- 命令行界面中显示下拉框有什么简单易用的库
- 看到 @005008 帮助了很多前端初学者,我也希望帮助更多的 Java 初学者
- chia-bls 签名 go 实现
- document 的 DOMContentLoaded 事件什么时候 readyState === 'complete' ?
| [弱弱的问一句] :做嵌入式开发的 V 友多吗? 搞 Hisilicon 海思方案 IPCAM、DVR、NVR、XVR 产品开发的人呢 Posted: 18 May 2021 04:20 AM PDT 本人在安防行业混迹多年,曾经做过 ffdshow 、xvid 、ffmpeg,Live555 streamserver,DShow,D3D,OpenCV 等等方面的应用开发,使用过 Grain-Media(GM8120,8180)、Maxim(Mobilygen MG3500)、Amberalla(A2,A5S33 、A5S55)、TI DM365 、DM368,Hisilicon Hi3518A 、Hi3516C 等芯片平台,主要开发过 IPCAM(网络摄像机)和 DVR(硬盘录像机)的产品。 刚来 V2 两个月而已,没找到设备端开发的版块,是我来错地方了吗? 还请各位大佬给指条明路 |
| Posted: 18 May 2021 04:12 AM PDT 最近看有活动下单了一台 NAS,想想又没啥用,就拒签了,现在又有点可惜,强迫症犯了 |
| Posted: 18 May 2021 04:06 AM PDT 今天有活动,听说可以直接改手机时间提前领取。。。 无法想像一家万亿市值的上市公司会有这么低端漏洞。。。
|
| Posted: 18 May 2021 04:02 AM PDT 技术栈 springBoot + openfeign + springcloudAlibaba + nacos
1 年的 Java 看法 想问一下,大家公司的架构体系和 fix bug 流程 new features 流程 发布流程是怎么样? #1 对于前期的架构和人员不足或者能力不足该怎么做平衡? #2 现实当中为了需求是否要牺牲一些基础架设? 感谢各位百忙之中回答我的问题 |
| 部署静态网站+备案+自动 https,哪个平台最友好?不想一堆配置、管理服务器 Posted: 18 May 2021 03:58 AM PDT 谢谢。 谢谢大锅们 |
| Posted: 18 May 2021 03:58 AM PDT hi, 大家好,我是 haohongfan 。 sync.Pool 应该是 Go 里面明星级别的数据结构,有很多优秀的文章都在介绍这个结构,本篇文章简单剖析下 sync.Pool 。不过说实话 sync.Pool 并不是我们日常开发中使用频率很高的的并发原语。 尽管用的频率很低,但是不可否认的是 sync.Pool 确实是 Go 的杀手锏,合理使用 sync.Pool 会让我们的程序性能飙升。本篇文章会从使用方式,源码剖析,运用场景等方面,让你对 sync.Pool 有一个清晰的认知。 使用方式sync.Pool 使用很简单,但是想用对却很麻烦,因为你有可能看到网上一堆错误的示例,各位同学在搜索 sync.Pool 的使用例子时,要特别注意。 sync.Pool 是一个内存池。通常内存池是用来防止内存泄露的(例如 C/C++)。sync.Pool 这个内存池却不是干这个的,带 GC 功能的语言都存在垃圾回收 STW 问题,需要回收的内存块越多,STW 持续时间就越长。如果能让 new 出来的变量,一直不被回收,得到重复利用,是不是就减轻了 GC 的压力。 正确的使用示例(下面的 demo 选自 gin ) 一定要注意的是:是先 Get 获取内存空间,基于这个内存做相关的处理,然后再将这个内存还回( Put )到 sync.Pool 。 Pool 结构源码图解简单点可以总结成下面的流程: Sync.Pool 梳理Pool 的内容会清理?清理会造成数据丢失吗?sync.Pool 会在每个 GC 周期内定期清理 sync.Pool 内的数据。定时清理数据并不会造成数据丢失。 要分几个方面来说这个问题。
runtime.GOMAXPROCS 与 pool 之间的关系?runtime.GOMAXPROCS(0) 是获取当前最大的 p 的数量。sync.Pool 的 poolLocal 数量受 p 的数量影响,会开辟 runtime.GOMAXPROCS(0) 个 poolLocal 。某些场景下我们会使用 runtime.GOMAXPROCS ( N) 来改变 p 的数量,会使 sync.Pool 的 pool.poolLocal 释放重新开辟新的空间。 为什么要开辟 runtime.GOMAXPROCS 个 local ? pool.local 是个 poolLocal 结构,这个结构体是 private + shared 链表组成,在多 goroutine 的 Get/Put 下是有数据竞争的,如果只有一个 local 就需要加锁来操作。每个 p 的 local 就能减少加锁造成的数据竞争问题。 New() 的作用?假如没有 New 会出现什么情况?从上面的 pool.Get 流程图可以看出来,从 sync.Pool 获取一个内存会尝试从当前 private,shared,其他的 p 的 shared 获取或者 victim 获取,如果实在获取不到时,才会调用 New 函数来获取。也就是 New() 函数才是真正开辟内存空间的。New() 开辟出来的的内存空间使用完毕后,调用 pool.Put 函数放入到 sync.Pool 中被重复利用。 如果 New 函数没有被初始化会怎样呢?很明显,sync.Pool 就废掉了,因为没有了初始化内存的地方了。 先 Put,再 Get 会出现什么情况?一定要注意,下面这个例子的用法是错误的 如果你直接跑这个例子,能得到你想像的结果,但是在某些情况下就不是这个结果了。 在 Pool.Get 注释里面有这么一句话:"Callers should not assume any relation between values passed to Put and the values returned by Get.",告诉我们不能把值 Pool.Put 到 sync.Pool 中,再使用 Pool.Get 取出来,因为 sync.Pool 不是 map 或者 slice,放入的值是有可能拿不到的,sync.Pool 的数据结构就不支持做这个事情。 前面说使用 sync.Pool 容易被错误示例误导,就是上面这个写法。为什么 Put 的值 再 Get 会出现问题?
只 Get 不 Put 会内存泄露吗?使用其他的池,如连接池,如果取连接使用后不放回连接池,就会出现连接池泄露,是不是 sync.Pool 也有这个问题呢? 通过上面的流程图,可以看出来 Pool.Get 的时候会尝试从当前 private,shared,其他的 p 的 shared 获取或者 victim 获取,如果实在获取不到时,才会调用 New 函数来获取,New 出来的内容本身还是受系统 GC 来控制的。所以如果我们提供的 New 实现不存在内存泄露的话,那么 sync.Pool 是不会内存泄露的。当 New 出来的变量如果不再被使用,就会被系统 GC 给回收掉。 如果不 Put 回 sync.Pool,会造成 Get 的时候每次都调用的 New 来从堆栈申请空间,达不到减轻 GC 压力。 使用场景上面说到 sync.Pool 业务开发中不是一个常用结构,我们业务开发中没必要假想某块代码会有强烈的性能问题,一上来就用 sync.Pool 硬怼。sync.Pool 主要是为了解决 Go GC 压力过大问题的,所以一般情况下,当线上高并发业务出现 GC 问题需要被优化时,才需要用 sync.Pool 出场。 使用注意点
参考链接
sync.Pool 的剖析到这里基本就写完了,想跟我交流的可以在评论区留言。 sync.Pool 完整流程图获取链接:链接: https://pan.baidu.com/s/1T5e8qCzp8JcTgARZFjGQoQ 密码: ngea 其他模块流程图,请关注公众号 HHFCodeRv 回复 1 获取。 学习资料分享,关注公众号回复指令:
|
| Posted: 18 May 2021 03:23 AM PDT ubuntu 用 smb 挂载 truenas 的文件夹,挂载完之后文件夹上面有一个小锁的标志,只有管理员能写入和修改文件,这是咋回事。我在 truenas 里面已经分配了任何人都可以写入的权限了,mac os 测试也可以读写 用的是这个命令:mount -t cifs -o username=admin,password=2333 //192.168.2.22/mnt/test /home/test3 |
| Posted: 18 May 2021 03:06 AM PDT 看了前端收徒的帖子挺有感触的是,大多数的指导和培训都只是帮助初学者入门,但大部分的有经验的从业者也是需要一些帮助,我们经常会抱怨公司的某个 legacy 项目烂如💩山,那💩山是怎么来的?有很多朋友面对这个情况励志重构,但限于眼界和经验,重构出的结果在几次需求的变更之后又成为了变成了新的山峰。 我接触过很多初级的开发者,他们可能都会使用库和框架,都能实现功能,但问题是他们代码可能运行不了两周就得重写,我也面试过一些前端的 leader,确实有丰富的经验,了解过从上古到现代的各种框架,如数家珍,但真让他去做一个项目,都无法完成基本的建模,数据和状态甚至都无法分辨。 作为开发,其实大量的时间都是面对业务,新技术只是改善了开发的体验,但并没有提升项目的质量,和开发人员的素养。我们真正需要的是抽象的能力,比如 SICP 中提到的的,构造过程抽象,构造数据现象,模块化、对象和状态,元语言抽象,这是我们编程思考的基础。 前端的开发可能是这方面确实最大的一个群体,很多人没想到过一设计好一个 view model,能够让项目的维护性稳定有多大的提升。很多人都在讨论 react hooks 如此好用,但从没考虑过如何使用它剥离业务。很多人没有数据分层的概念,以至于无法在维护的时候理清逻辑等等。 我们如何能改善这些,我觉得我们不止是需要培训,我们需要在做具体业务的时候有人能够指导,所以 code review 应该是不错的方式。 有想法做一个这方面的业务实践,本人做过大厂的架构,也在创业公司和外企做过 leader,还是有一些实践,但我觉得如果有经验的开发者都能去做这样的事情我们面对的💩山也回越来越少。 |
| github 上面的项目, star 后,可以打标签/tag 么?否则,大家怎么找到自己关注的项目? Posted: 18 May 2021 03:02 AM PDT 经常看到好的项目,就 star 一下。可是发现,有好多个项目,一段时间不看,再回来,发现忘记名字了。 大家有没有好办法解决这个问题?或者,github 的已 stars 项目搜索,有啥特别的技巧? 谢谢! |
| TieJS: 一个基于 TypeScript 的个人级 Node.js 框架 Posted: 18 May 2021 02:56 AM PDT 这个一个我个人开发 Node.js 框架,一个基于 TypeScript 的 Node.js 框架,底层基于 Koa 和 TypeDI,核心特性是使用依赖注入组织应用代码。 项目地址: https://github.com/forsigner/tie 为什么开发 TieJS,我刚开始用了两年多 Egg.js ,但是由于其对 TypeScript 支持过于弱(还有其他原因略过),放弃 Egg.js 了,尝试使用了一个月 NestJS,由于其概念过于多、使用繁琐等原因也放弃了,所以开发了 TieJS,前后大概开发和维护了一年多时间。 我自己是 TypeScript 和 GraphQL,并且相比 Express,我更喜欢 Koa 的中间件系统,所以开发了 TieJS,核心特性是使用依赖注入组织应用代码,还有一个就是内置 GraphQL 的支持。 Tie 意为绳子,在 TieJS 中,最核心的单元是一个个 Injectable 的模块,通过依赖注入这根绳子,你可以有序地组织一个复杂的项目。也放弃了 NestJS 引入 Node 社区所有复杂的概念。 一些特性TypeScript, 全面拥抱 TypeScript 依赖注入,易于编写可维护、可测试的代码 基于 Koa,易于可以复用 Koa 中间件生态 开箱即用,零配置开始项目 插件体系, 易于扩展 核心技术TieJS 使用下面这些开源技术:
这个框架因为个人原因,特性更新的比较慢,欢迎有兴趣的人一起维护和开发,如果有人有兴趣,我会把代码库转移到一个 Github 组织,并且开放开发权限,可以加我微信:ziyi-314,当然加微信普通交流也可以 哈哈 |
| 给同事讲 Python 的高级用法, 有没有提纲什么的... Posted: 18 May 2021 02:17 AM PDT 有经验的同事,譬如 Java 背景的或者刚毕业的. 只讲接地气的实用的高级用法. 奇技淫巧不要. 大佬们集思广益 谢谢啦....... 只需要列提纲即可或者大佬们想到某一个点也可以. |
| Posted: 18 May 2021 02:10 AM PDT 小白问一下各位大神,大家公司的项目中对于 redis 集群,会配置读写分离,对于读请求分配到从节点吗 |
| 为什么 gevent 没有封装 epoll 呢,看只实现了 poll 和 select Posted: 18 May 2021 02:03 AM PDT 之前用 select 实现的总是有文件描述符限制,改了 ulimi 改打了做并发测试的时候还是会出现。 使用系统的 epoll 行么,会不会有阻塞 |
| Posted: 18 May 2021 01:51 AM PDT 职位:安卓工程师 薪资:15-30K 坐标:广州市海珠区唯品同创汇
意向者简历可发送至: qutaotao@qq.com |
| Posted: 18 May 2021 01:46 AM PDT 如题,用了这么多年 py,Gil 按理说应该很熟悉了,但是今天被问到 Gil 具体锁了哪些东西的时候却被问住了。毕竟虽然引入了 gil 机制,但 py 中的线程争用资源由于原子性问题仍然需要用户自行上锁,细究的话很多文章讲的加入 Gil 后避免细粒度锁其实是不对的,因为用户层面并没有实现无锁感知。 具体来说,例如放两个线程同时在各自负责的内存空间操作完全不相干的对象时(比如双线程同时计算质数,各自维护各自的资源),那么按照大多数语言的思路,由于没有资源争用,实际上并不需要加锁(反之,如果有争用则必须加锁,目前 py 中也是这么干的),如果这么考量的话,Gil 所谓的有锁线程才允许解释,又解决了什么问题呢,完全没必要不是么 |
| Posted: 18 May 2021 12:27 AM PDT A C qwer qwer1234 asdf asdf11 zxcv zxcv55 aa aass111 像这样 A 列是 C 列的开头就匹配合并。 找半天没找到合适的。 求大佬指教。 |
| Posted: 18 May 2021 12:11 AM PDT 早上一来的时候说是邮箱不能用,客服电话打不通,后来发现 263.net 官网都打不开了, 好不容易打通电话说是光缆被挖断了,这是穿越了么?看了下贴吧,https://tieba.baidu.com/p/7357573798?pn=3 还有说是世纪互联的机房大火了,北京的小伙伴有啥消息么? |
| Posted: 17 May 2021 11:56 PM PDT 我都不敢去面试 我觉得我技术不行,看到招聘上面信息就离谱 我是学习前端的 自己自学了 flutter 我现在一直迷茫中,有一个月没写代码了,感觉都要忘完了,求求老哥传授点经验 |
| Posted: 17 May 2021 11:20 PM PDT
以前使用
另外,如果想要查找内存里的对象,需要 heapdump 再分析。 Arthas 在最新发布的 3.5.1 版本里,带来神级特性:通过 vmtool 在线教程下面以 首先启动任意 spring boot 应用,比如: 然后用 查找 jvm 里的字符串对象首先, limit 参数
所以上面的命令实际上等值于: 如果设置 查找 spring context以前的在线教程里,我们需要通过 通过 指定返回结果展开层数
获取 srping bean,执行表达式
比如,查找所有的 spring beans 名字: 比如,调用 查找所有的 spring mapping 对象
查找所有的 javax.servlet.Filter在 Arthas 的在线教程里,我们介绍过怎么排查 http 请求 404/401 的问题。使用的是 现在使用 指定 classloader name在多 classloader 情况下,还可以指定 classloader 来查找对象: 指定 classloader hash可以通过 然后用 强制 GC当启用
如果应用配置了 致谢
总结
上面只展示使用
欢迎大家到 Issue 里分享使用经验: https://github.com/alibaba/arthas/issues 我们正在寻找小伙伴,特别是深圳的同学,欢迎大家加入。 |
| Posted: 17 May 2021 10:44 PM PDT 业务需要,如果你有,这边可以提供报酬 |
| Posted: 17 May 2021 10:06 PM PDT 目前计划开发一系列面向小学生的答题类游戏,运行环境为微信 Web 端,用户通过公众号菜单进入游戏,后端通过每个用户在该公众号中的唯一 openid 对其进行标识。预计每个游戏最多会有几千个用户。 对于每个学科,都会有一个专属的答题游戏,各学科的题目数量均有限,各游戏规则相同。 用户在每个游戏中,每一轮都不重复地回答本学科下的所有题目,一旦答错一道题则本轮结束,并计算本轮答对的题目数量,然后开始下一轮。在每个游戏中,以各用户在该游戏中的历史最高分(即答对题目数量最多的那一轮)生成排行榜。这样的话,每个用户在每个游戏中能够拿到的最高分,就是该游戏对应学科的题目数量。 数据库层面,我的设想是需要三张表: 题目表:全是单项选择题,目前想的是保存题目的题干、选项、答案、分类这四个字段即可,之后有新的需求了再调整。 用户表:用户的 openid 是必选项,其余像昵称、头像之类的都可以根据需求决定是否保留。 排行榜表:每个游戏的排行榜,我能想到的必须要有的信息,是用户的 openid 、用户在该游戏中拿到的最高分。 至于用户在每个游戏中拿到的最高分对应的排名,是否也需要保存到表中? 每个游戏最多有几千名用户的话,假设一共有 4 个游戏,是否有必要为每个游戏的排行榜都单独建一张表? |
| 同一个包在 dependencies 和 peerDependencies 中的版本不一致 Posted: 17 May 2021 10:00 PM PDT dependencies 里面是 peerDependencies 里面是 什么原因会导致这种情况呢? npm install 时,会报错,说^7.3.0 找不到,因为已经有了^11.*.*的版本。这让我只能用 --legacy-peer-deps 来避免这个 react-dnd 包的版本问题。 |
| Posted: 17 May 2021 09:48 PM PDT 在看 fail2ban,源代码 感觉好难呀,发现没有 type,看别人的代码,好痛苦, 所以 我找了一个 golang 的 fail2ban ,crowdsec, 看了下,感觉还是很难,经常不知道这个属性是啥,哪里来的? 例子是什么? 在看两天试试 难道会用就行了? |
| Posted: 17 May 2021 08:58 PM PDT 需求是前端会传过来一个 html 的富文本字符串, 我在后台将其转换成 word 文件并且保存到服务器,目前完全没有思路,有做过相似需求的能给点思路吗 |
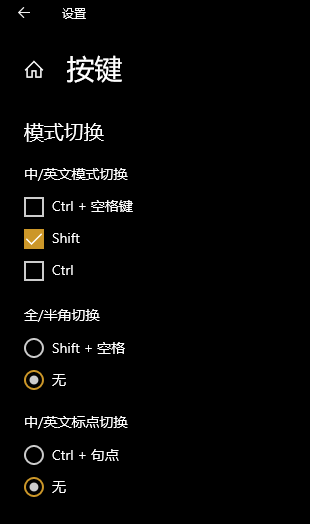
| windows 自带微软拼音输入法 热键占用问题 Ctrl+. Posted: 17 May 2021 07:52 PM PDT 问题:在 edge 浏览器使用 Surfingkeys 插件时, 按 t 打开弹窗查找地址(历史,书签等), 结果列表有多页, 使用插件文档中的快捷键翻页,
经过网上查找 发现是 windows 里安装的微软拼音输入法 占用了 ctrl+. 在设置里关闭了 ctrl+. 切换中英文标点功能, 按键仍被占用 相关链接有哪位大佬知道咋解决吗 (ps: 我查看了插件文档和插件的高级设置默认配置, 未找到能更换快捷键的方法) |
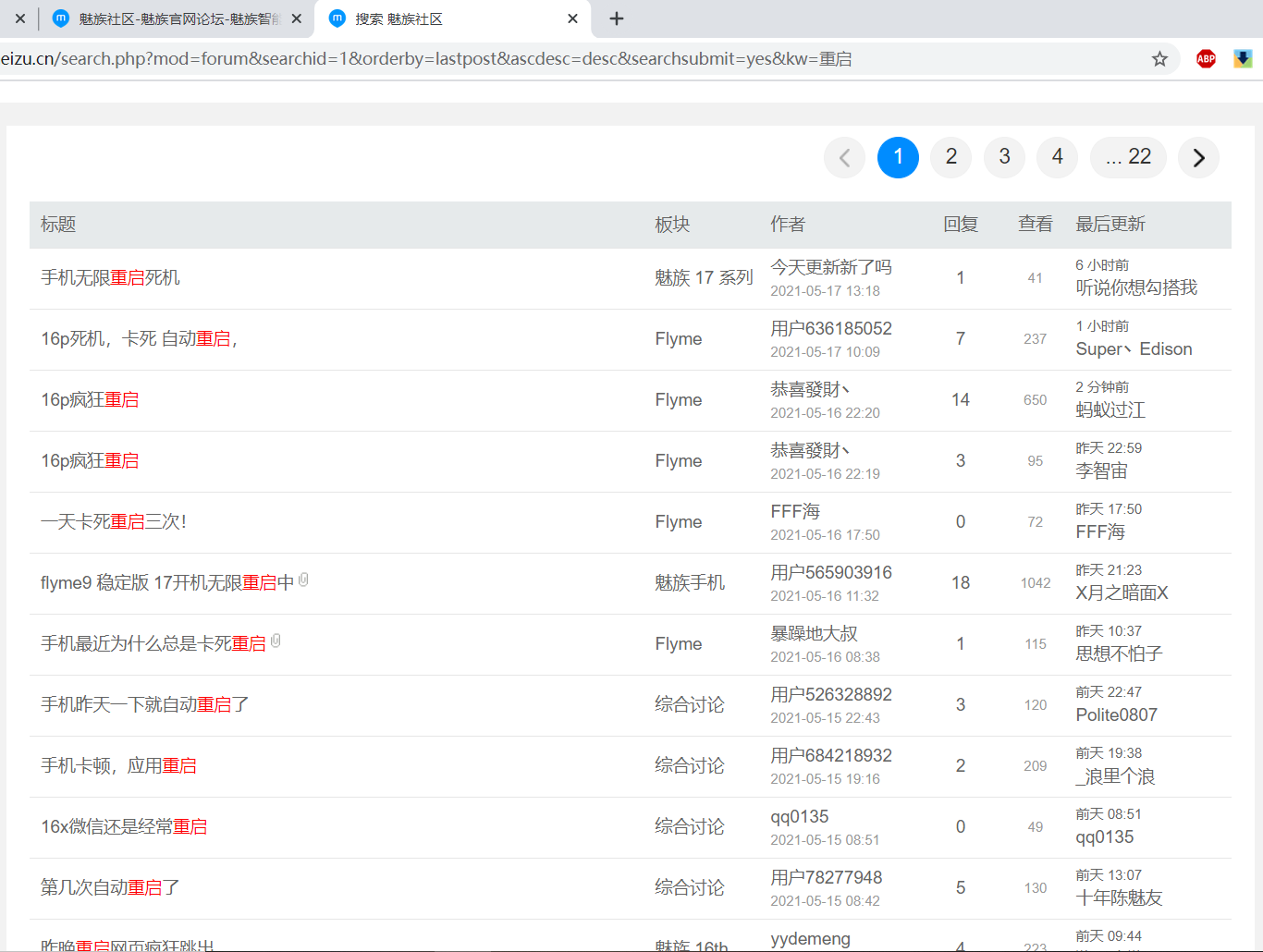
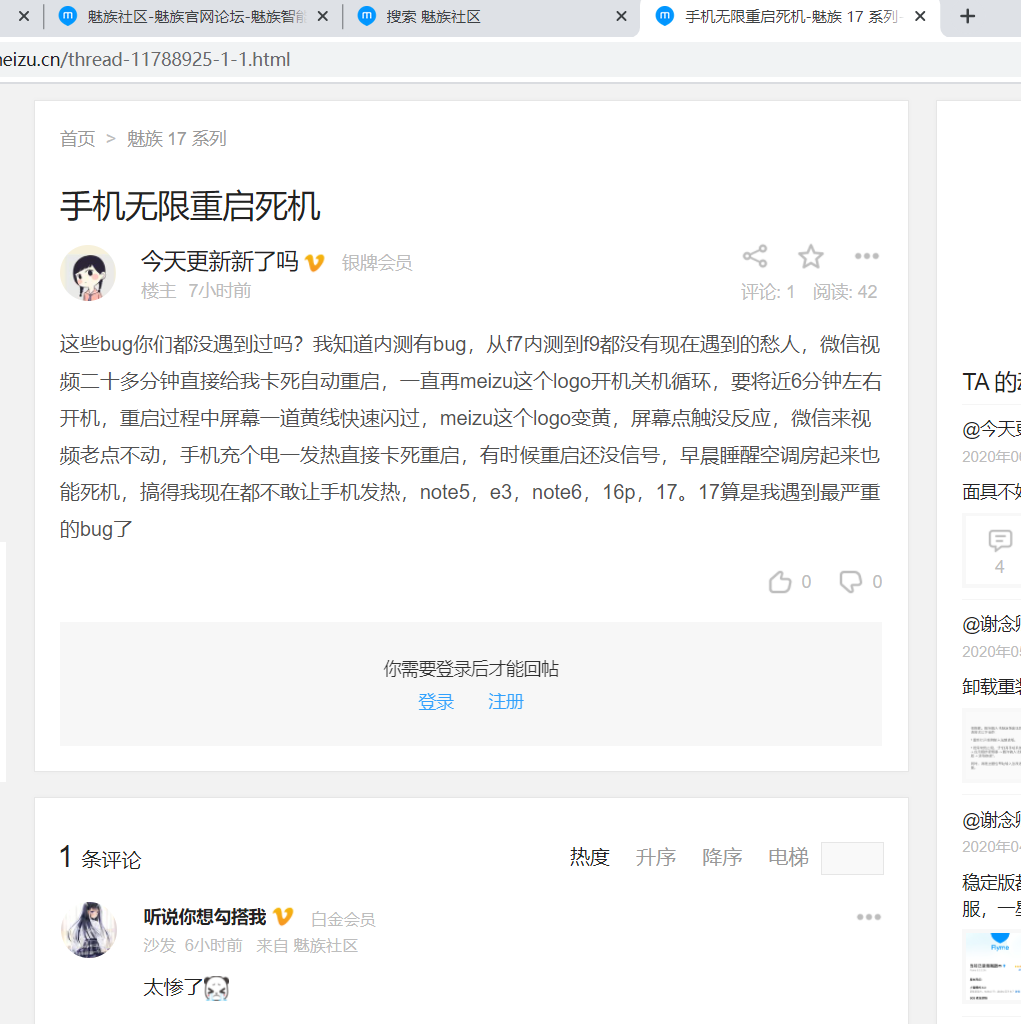
| 手机 APP 大面积闪退系统无限重启,魅族这是已经放弃治疗了? Posted: 17 May 2021 03:18 PM PDT 家里人用的魅族,刚才跟我说是从前天开始手机会频繁重启,一接电话或者微信语音系统就死机然后自动重启,目前手机已变砖,根本没法用…… 听到这个我就到魅族社区去看了下。好家伙,一搜全是这个问题,官方也没给个回复,不知道是不是已经放弃治疗了。
|
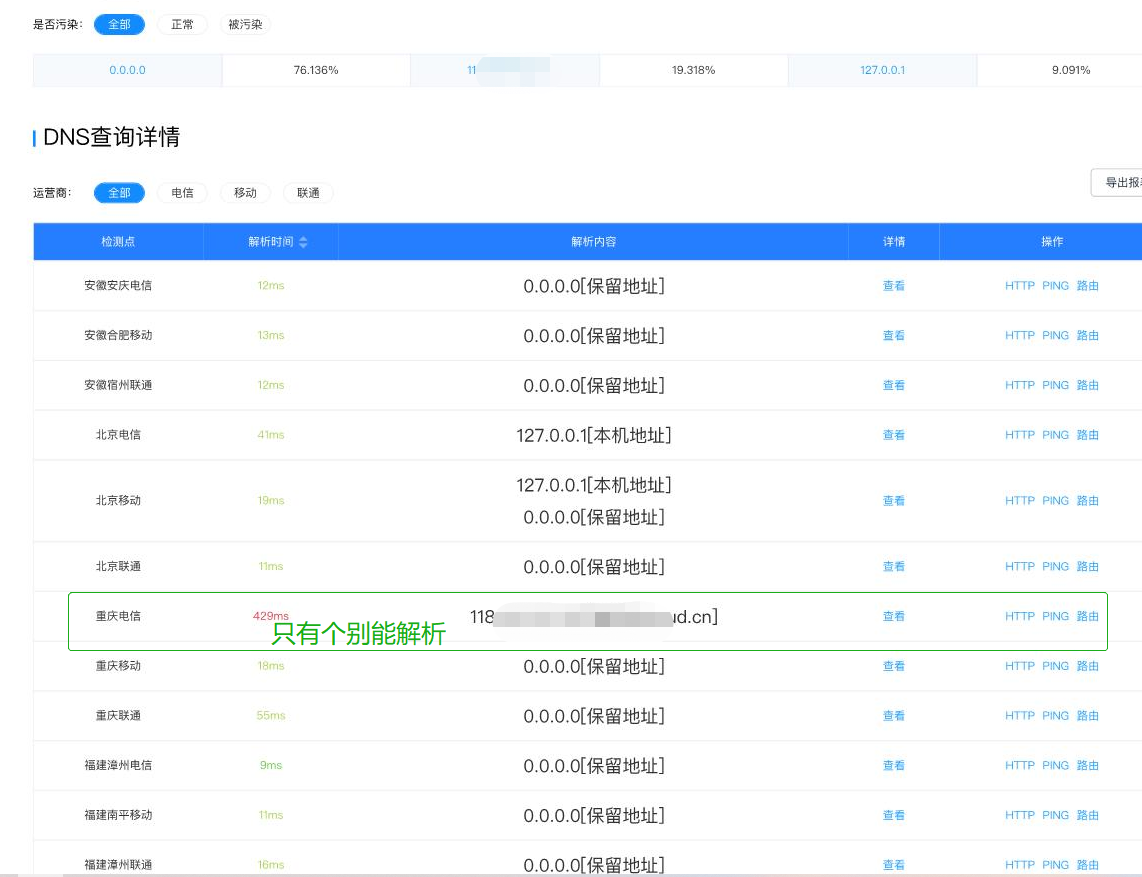
| 大家遇到过配置 dns 解析超过 48 小时还没生效的情况么? Posted: 17 May 2021 01:54 PM PDT 几个月在腾讯云买了个域名,指向服务器都比较正常,上周发现二级域名不能访问了,带 www 的三级域名还可以访问,于是用这个 dns 检测工具( https://www.boce.com/dns )试了下有问题的二级域名,果然绝大多数都失效了,于是重新在 dnspod 上调整了下解析,超过 48 小时后发现解析成功率还是在 20%左右,请问大家遇到过这种情况么?该怎么解决一下呢? |
| Posted: 17 May 2021 01:10 PM PDT 如题,据说 RLCD 全反射屏 s 是最为护眼的屏幕?不知道有没有此类显示器呢? 明天工作码代码都得面对显示器。除了休息一会,看一看远方,能不能从源头避免一些呢? |
| 除了 Amazon Transcribe (AWS), 有无其他能对法语德语音频进行转写的软件或者云服务? Posted: 17 May 2021 12:13 PM PDT 除了 Amazon Transcribe (AWS), 有无其他能对法语德语音频进行转写的软件或者云服务?
|
| Posted: 17 May 2021 10:18 AM PDT ipython 、bpython 中输入时按<Tab>键可以弹出一个下拉框提供选择项,请问有什么简单、易用、依赖项少的 Python 库可以实现类似效果? 不需要功能多强大,,关键是简单、易用。。 |
| 看到 @005008 帮助了很多前端初学者,我也希望帮助更多的 Java 初学者 Posted: 17 May 2021 10:06 AM PDT 看到 @005008 的帖子 https://v2ex.com/t/777473#reply14 ,觉得非常好,可以帮助更多的初学者进入互联网开发行业。 那么我也尽我的绵薄之力,希望可以为更多的在校大学生或 Java 初学者答疑解惑。 我有 12 年的线下培训经验,也有自己的公司。有时候会比较忙,但我会尽力抽出时间帮助你们。 ------------- 因为精力有限,暂时不会帮助已经工作的同学,请见谅。 这个过程是免费的,不用担心费用问题。当然,你觉得好,请我喝杯咖啡我也会开心😀 vx:fankay |
| Posted: 17 May 2021 09:14 AM PDT |
| document 的 DOMContentLoaded 事件什么时候 readyState === 'complete' ? Posted: 17 May 2021 07:10 AM PDT 在文档最底部插入以下脚本:
|



| You are subscribed to email updates from V2EX - 技术. To stop receiving these emails, you may unsubscribe now. | Email delivery powered by Google |
| Google, 1600 Amphitheatre Parkway, Mountain View, CA 94043, United States | |
No comments:
Post a Comment