V2EX - 技术 |
- 想深入钻研一门语言 请大家出出主意
- RBAC 整合数据权限的设计
- 关于工作中复杂接口设计和治理
- 求分享,有没有你们认为在终端环境中能提升效率的命令或者操作
- 有比树莓派更稳定的开发板或者小型服务器吗?
- 请教在 shell 里启动的两个 Python 进程之间要如何共享一个对象?
- 不太懂安卓开发,想问下现在国产安卓 App 的一部分工作就是跟国产安卓系统斗智斗勇吗
- puppeteer 加载网页失败
- 关于垃圾佬 diy 家用 NAS 的一点思考
- 有没有小型主机支持 Windows/ Linux 双系统?
- 能在静态 HTML 文件添加登录界面吗?
- 1G 的 Nginx 日志如何过滤去包含某个路径的记录行
- 很想知道你们在使用 k8s 时怎么解决 k8s.gcr.io 这个域名访问不了的问题的?
- 团队开发中如何看待或者与成员沟通代码质量等问题
- requests 用 post 获取数据,当数值发生变化时打印记录
- 在 ThreadPoolExecutor 里使用 subprocess 算多线程还是多进程
- 关于 apiserver 中的 apiextensionsServer,如何脱离 k8s 单独运行?
- 这种场景是否能把 etcd/consul 当做“分布式数据库”?
- 自建 harbor 证书问题
- 移动端 H5 调试你们用什么方式方法?
- Google 中文检索结果里发现了一个新的排名很高的垃圾站
- Pycharm 突然卡爆求救,之前用的还很好,现在随便动一动就卡死
- 富文本生成的 htmlstring 在展示端进行图片 loading 预占位的一种实现方案
| Posted: 22 Dec 2021 07:56 AM PST 需要满足以下五条要求 1 支持多范式编程,表达能力强大 2 充分隐藏计算机体系结构的细节,特别是内存管理等等的细节 3 生态丰富,有大量的工具和库 4 语法设计现代,代码较为简洁,开发效率高 5 具有先进的 完善的工具链支持 比如 编译器 IDE 调试工具 运行监测工具之类 目前备选 python java C# js php groovy ruby swift perl kotlin scala 请大家帮我做做排除法 或者分析一下 n 这些语言不符合上面哪些要 如果没十全十美的 或许可以矬子里拔将军 最后我能选出一个 |
| Posted: 22 Dec 2021 07:49 AM PST 在项目实际开发中我们不光要控制一个用户能访问哪些资源,还需要控制用户只能访问资源中的某部分数据。 有什么好的想法可以在下方留言。 |
| Posted: 22 Dec 2021 07:44 AM PST 有一个 service 层的下单业务接口,承载了各种业务下单功能,为了达到抽象和复用的目的,入参对象比较复杂,包含一些基本类型属性和一些对象属性,对象属性中又包含对象属性。 目前项目中使用 swagger 生成接口注释文档,因为不同的业务场景对同一个字段的必传,非必传要求是不一样的,所以不能简单的通过 @ApiModelProperty(required = true)来表达,人肉对接口,而且无法把内容沉淀, 请教各位大佬有没有好的方法 1.以某种方式或者借助某个工具能够在接口文档上体现这种场景校验的不同,让调用方能够看的懂 2.对于复杂业务接口抽象的应该如何把握尺度,既能兼顾抽象又能控制复杂度 |
| Posted: 22 Dec 2021 07:42 AM PST 比如 |
| Posted: 22 Dec 2021 07:34 AM PST 主要是放在家里当个 nas 以及跑一些自动化脚本, 之前配了一台树莓派, 但是不稳定, 隔一段时间就挂 |
| 请教在 shell 里启动的两个 Python 进程之间要如何共享一个对象? Posted: 22 Dec 2021 06:57 AM PST 请教各位一个问题: 在 shell 里起两个 python 任务,这两个 python 进程之间是否有什么办法可以共享一个对象( OrderedDict 之类的),一个进程只读,一个进程只写? 我目前采用的方案是用 pickle.dumps 将这个对象(比如 OrderedDict )序列化成 bytes 类型,然后放到 SharedMemory 里,通过一个 name 来实现共享,但是感觉序列化这一步有点慢,求教有没有更快的方法。 并非不想用 multiprocessing ,一方面 python 的多线程有点蛋疼,另一方面涉及到深度学习库和 GPU 运算,担心 multiprocessing 搞不定…… |
| 不太懂安卓开发,想问下现在国产安卓 App 的一部分工作就是跟国产安卓系统斗智斗勇吗 Posted: 22 Dec 2021 06:34 AM PST 没有鄙视 /引战 /嘲讽的意思, 就是看见 MIUI13 快发布了, 想起来手里当备机的 K40 ,买之前一直幻想对国产流氓们的强力打击, 然而现在时不时的还是会提示 某宝某多某音 后台耗电高什么的, 感觉永远不会像 iOS 一样一劳永逸(这个自己理解吧), 是不是 Android 底层就决定了永远需要用魔法去打败魔法? |
| Posted: 22 Dec 2021 06:22 AM PST 我这块在第一次打开页面的时候 还有一个问题,这个是我这个方法的结构,我上面 |
| Posted: 22 Dec 2021 05:38 AM PST 垃圾佬 19 年初捡了一台 C 款,入了 diyNAS 的坑。装了 4 块 3T 日立盘,由于 PT 和小姐姐入驻的原因,空间目前已捉襟见肘,于是起了再组装一个多盘 nas 的想法。 基于过去两年多的使用体验,一点思考: 1.硬盘热插拔是否刚需 这一点对于垃圾佬来说并不是刚需,毕竟换硬盘的频率很低,真的要换关机就行了,并不会影响体验。 2.是否一定要小体积 小体积的话对机箱和主板要求就会比较高,itx 主板相比于 matx 主板贵且接口少,对应的机箱也比较贵。垃圾佬并不太讲究颜值,随便买个 200 以内 matx 机箱还有的挑。 3.关于功耗 目前在用的 nas ,插满 4 盘功耗大概是 50w ,板 U ( J3455 )功耗大概 10W ,每个硬盘 10W 左右(用功耗仪测过,每拔一个硬盘功耗降低 10W 哈哈),功耗大头实际竟然是在硬盘上。所以私以为也不必执着筛选低功耗的 cpu ,手头上有什么存货或者一些性价比较高的二手货都可以拿来用(当然也不要大材小用),nas 日常低负载的情况下功耗不会差太多。 不知道大家对于 diyNAS 有什么想法 |
| Posted: 22 Dec 2021 05:14 AM PST 平时用 Linux 搭建 NAS 和跑一些自动化脚本, 偶尔切换到 Windows 玩会游戏, 比如 LOL 或者一些小型单机游戏, 不需要很高配置 |
| Posted: 22 Dec 2021 03:50 AM PST 最近在玩黑群晖,按照 https://wp.gxnas.com/7023.html 自己弄了个导航页,但感觉随便一个人都能访问,而且 TMM 无需登录就能随便搞,后来搜索到一篇文 https://blog.csdn.net/ColoutfulT/article/details/103698497 有说如何添加登录界面,但本人小白不懂文中代码添加到哪里,直接在 html 文件添加也不起作用,经朋友提醒说 PHP 代码不能在 html 里面运行,望各位大佬指点指点,我只是想在进入导航页前需要登录而已。 |
| Posted: 22 Dec 2021 02:24 AM PST 这里由于一直没有做 nginx 日志切割,结果文件滚到 1G 多,不过压缩后也就 40 多 M ,不知道有没有办法可以过滤出其中包含某个路径的记录行,应该不会太多 |
| 很想知道你们在使用 k8s 时怎么解决 k8s.gcr.io 这个域名访问不了的问题的? Posted: 22 Dec 2021 02:14 AM PST 阿里云的 google_containers 是官方维护的还是个人维护的呢? 虽然可以用如上的阿里云,但是发现好像包不是很全,比如 kube-state-metrics 包,貌似就没有,没法装了? |
| Posted: 22 Dec 2021 02:13 AM PST 最近公司新起了个项目,主管让我带新人做做,新人之前做 php ,没有接触过 go 。 我将之前的项目代码以及文档都分享给了他,并给他简单将讲解了项目的架构以及流程。 我给他起好了模板给他开发,结果第二天发现他直接把代码结构直接咔嚓一顿给改了(我起的 代码架构我们已经沿用的两个项目了,其他人也都这么搞的)。然后我就给他说了一下,然后他就给我一顿争论, 还提了他的这个思想是上家主管说的...我那叫一个气的。不过还好本人脾气还算好,我直接又给他理了一下我们的代码架构, 让他重新照着开发一遍,1 是为了方便我们团队合作开发,2 是等你有了一定的基础和经验你再去构思自己的结构布局,哪有没 学会走就要去跑的呀。 今天又去看了下他复写的代码,我是真不知道该怎么跟他说了 真不知道跟怎么跟他说了...是不是我太钻牛角尖了? |
| requests 用 post 获取数据,当数值发生变化时打印记录 Posted: 22 Dec 2021 01:58 AM PST 我现在用 post 获取到了数值,每 10 秒获取一次这个数值,当增大的时候就打印记录 比如现在是 a=50 ,如果变成了 55 ,那就打印输出增大了 5 ,然后重新赋值 a=55 就一直循环,要实现这个要怎么写? |
| 在 ThreadPoolExecutor 里使用 subprocess 算多线程还是多进程 Posted: 22 Dec 2021 01:46 AM PST 需要用到 subprocess.run()调用 shell 运行 youtube-dl |
| 关于 apiserver 中的 apiextensionsServer,如何脱离 k8s 单独运行? Posted: 22 Dec 2021 01:37 AM PST 刚接触 k8s ,k8s 很好,但是功能太多了,k3s 也是。我只需要 apiserver 中的 extensionServer 。请问现在有已经抽离出来的项目吗?我想要的 apiserver 只需要依赖 etcd 和 认证服务,目前重点看了 k8s 仓库里面的 apiextensions-apiserver 和 sample-apiserver ,运行后发行都需要指定 k8s 的 ip 和 端口,是否意味着都依赖 k8s 呢?源码很不好读懂,希望熟悉这一块的大哥帮忙解答一下。 |
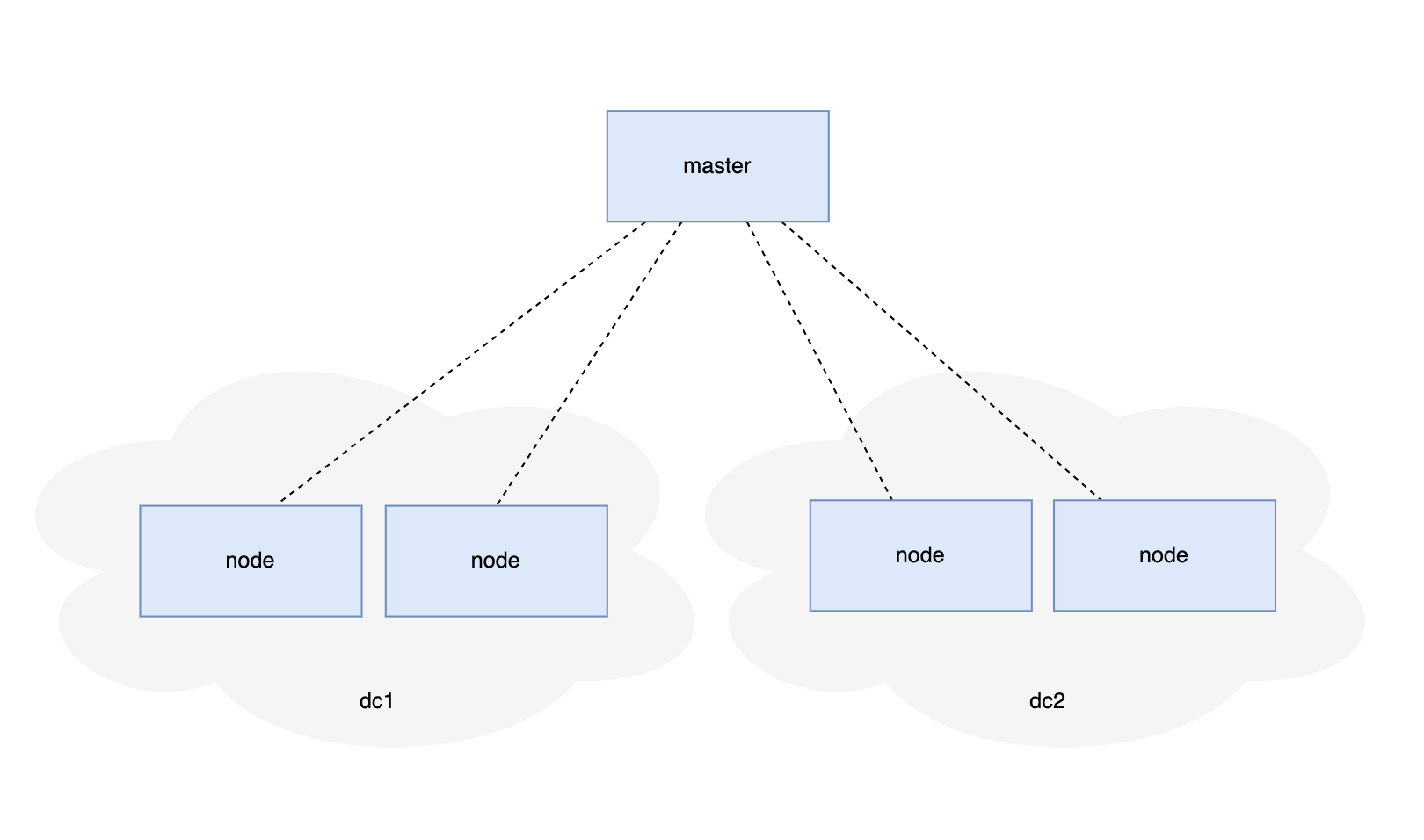
| 这种场景是否能把 etcd/consul 当做“分布式数据库”? Posted: 22 Dec 2021 01:32 AM PST 如图
master 要 和 node 之间保持数据同步,数据可能「单向的」也可能是「双向」的。 业务场景数据量 < 100 万 最初的解决方案:采用 MQ ,master 发布消息,各个 node 订阅消息,做到最终一致性。 如果是反向通信,就 node 发布,master 订阅。 场景:1 、新加入 node 需要同步全量数据,再同步增量数据,达到最终一致性。 2 、node 可能离线一段时间,之后恢复在线,需要一段时间后达到最终一致性。 这个数据同步过程处理起来比较复杂。 so ,能否使用 etcd/consul 等,整个作为一个集群,用 kv 存储来代替最初的方案,满足上面的场景? |
| Posted: 22 Dec 2021 01:05 AM PST 刚刚看到有人问 gcr.io 的镜像问题就想起来以前的没解决的问题。 就是我们自建 harbor 的时候,如果启用了 https,想要用域名访问的时候就要么用证书,要么在 deamon.json 中增加 insecurity 项。 我之前是用 acme 申请的免费证书,直接在 nginx 上配置证书,如果我用命令 而我看比如阿里云他们的镜像源也不需要配置证书就可以直接拉取了,还有我也见过公司合作的厂商也有些的 docker 仓库的域名也不需要特别配置就可以直接拉取,那么他们用的证书是什么样的证书,为啥可以直接通过 docker daemon 的验证,这种证书有免费的吗? 因为我对这块也不熟,查了谷歌跟百度也没有找到答案,所以过来请教一下各位大佬。 |
| Posted: 22 Dec 2021 12:30 AM PST 我一直用 inspect ,不知同胞们也是如此吗? |
| Posted: 21 Dec 2021 11:59 PM PST 图就不贴了,网站叫秀儿,貌似域名还有好几个? 我这刷到的有 xiu2.net 跟 docway.net ,可以加黑名单了 |
| Pycharm 突然卡爆求救,之前用的还很好,现在随便动一动就卡死 Posted: 21 Dec 2021 11:53 PM PST Apple 节点没人回,实在着急再发一次在这边看有没有人能救救的。 M1 版(也就是 ARM 版),之前用的好好的,已经用了大概一个月了。现在突然卡爆了,随便一拖就 100+的 CPU 占用,占用无所谓主要是卡死,尤其出现在选中文字,或者开菜单的时候。 目前最大的嫌疑是,这个叫<infrastructure: awt-appkit>的子系统飙到了 100%左右的占用。但是我完全不懂 Java ,看不出这是什么。有没有 Java 前端给科普下,我看了自己的一个 Windows Pycharm 上这个占用就一直不高。  之前按照坛里的教程改过 JVM 到 metal 版,虽然我其实觉得原装的就不卡。目前已经全部回滚到默认设置,已经清除所有缓存重装、重启过,无果。 试了下 WebStorm ,一样卡爆,一样是这个玩意占用极高。手头没有 JS 项目,直接开了个 Python 项目拉了几下 Python 文件就爆了。 另外我把问题发到 YouTrack 上去了,用的教育 License 会不会权重下降啊。 |
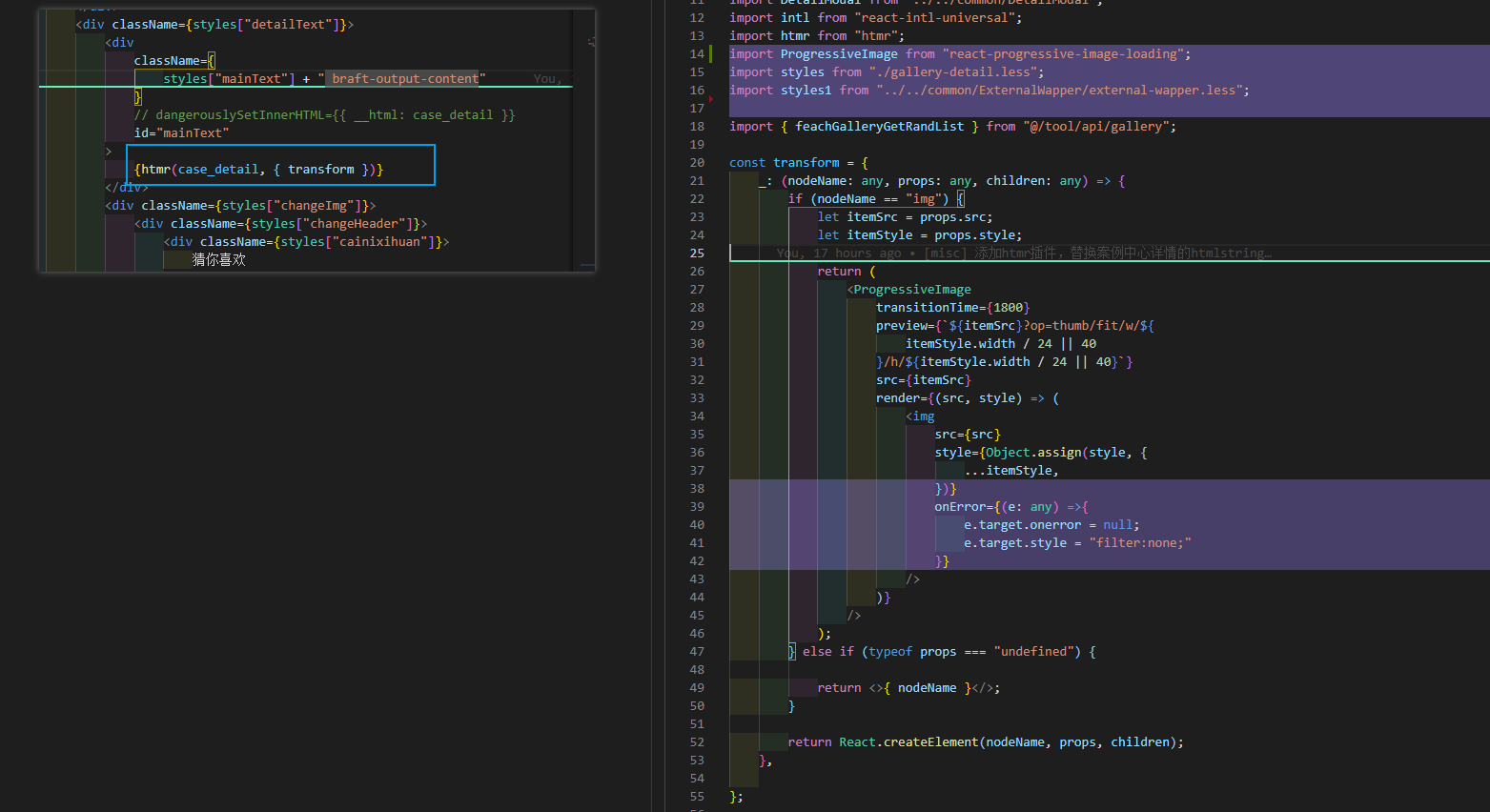
| 富文本生成的 htmlstring 在展示端进行图片 loading 预占位的一种实现方案 Posted: 21 Dec 2021 07:41 PM PST 产品出现的问题: 我最终的解决方案: 插件: (2) react-progressive-image-loading onError={(e: any) =>{ e.target.onerror = null; e.target.style = "filter:none;" }} 题外话总结: (忍住没在探索阶段就摆烂在 V2EX 发帖求助,自己找到了) ——不清楚啥原因触发了被 ban 的逻辑,我源码贴不上来 orz 就放个图了,包含上文提及的额外内容
|
| You are subscribed to email updates from V2EX - 技术. To stop receiving these emails, you may unsubscribe now. | Email delivery powered by Google |
| Google, 1600 Amphitheatre Parkway, Mountain View, CA 94043, United States | |
No comments:
Post a Comment