V2EX - 技术 |
- 单独部署在客户服务器上的 Java 应用如何防止客户将其再次部署到其他客户的服务器?
- wslg 简单用用感觉还不错
- google play 锁区
- 迫于更新简历,有没有什么 markdown 简历模板?
- VSCode 的这个叫做 Solarized Light 的配色主题很有 Notion 的感觉
- 2021 年了,如何从零入门 Kotlin ?然后能迅速做出一个 Android 应用程序。
- 设计函数时如何界定何时需要捕获异常并自己处理,何时需要抛出异常给调用方?
- 我是如何突围传统行业的?
- 腾讯云 chia 方案
- 7zip 官方 7-Zip 21.02 alpha (2021-05-06)源代码编译...
- Java try catch 代码块中调用层级 catch 的捕捉问题
- [求助] 腾讯轻量云内存占用高。。
- XCode 里下载不到 ios 12 以下的镜像了,排查问题好不方便,到底咋想的?
- 求推荐,有啥简单好用的容器服务吗, docker-compose 一配,文件上传就运行,不用买集群啥的
- 现在的程序员,这么简单的问题都能答错吗?
- 关于 kotlin 安卓开发,网络框架有用 Retrofit+协程的方式实现的吗,真的好用吗
- 一封让我很高兴的邮件
- pymssql 在插入数据库操作时候网络断开应该如何捕获异常?
- 如何解含有多个变量的线性方程组?
- DDD 领域模型的好处到底是什么
- 在 boss 上看到有一些对外的岗位和一些远程的岗位工资很高
- PostgreSQL 和 MySQL 中 schema 的区别
- 请教:阿里云同地域不同可用区的延时情况如何?
- PHPStorm 的 Ctrl + / 的单行注释,只能顶头加嘛?
- 在 Windows 上使用_vscwprintf 处理 UTF-8 编码的字符串时失败,该如何解决?
- 把 oppo push service 移植到氧 os
- 我们学最新的技术和概念,写优雅的代码和注释是为了什么?
- Luna Paint
- 谷歌数据集搜索 https://datasetsearch.research.google.com/
- 找人做一套软件,有目标软件参考
- 吐槽一下 Python 版本的割裂
- win7 sys 驱动如何安装
- 应用启动时的初始化代码放置问题
- 我用 type()动态创建了一个类,怎么生成这个类的 Python 源代码??有现成的工具吗?需求的场景是这样的
| 单独部署在客户服务器上的 Java 应用如何防止客户将其再次部署到其他客户的服务器? Posted: 07 May 2021 05:18 AM PDT 如题,我用 java 做了一个管理系统出售给某个客户并需要部署到客户的服务器,客户方面有懂技术的人员,如何防止他们去将这个应用再次部署到其他服务器上,或者说尽量增加他们移植到其他服务器的成本?以防止他们将其二次出售给其他客户, 从而影响本人的利益.请各位大佬分享一些经验,谢谢. | ||||||||||||||||
| Posted: 07 May 2021 05:17 AM PDT 就跑个 jb 的 ide, 终端直接用 windows terminal,似乎现在用 windows 开发对我来说没有什么障碍了 天天被大家 m1 真香洗脑,早上照例上 apple 官网蹲 m1,看到更新了好多 m1 官翻库存,一激动都下单了 后来网上冲浪看到 wslg 的消息,立马把 insider preview 改成 dev 通道升级系统,升级 wsl 一气呵成 进 ubuntu 安装了 jb 的 ide 试了试,操作比 win 本地稍差一点,可能我电脑配置还不错所以并不会觉得卡。 重点是再也不用忍受一个 git 命令读盘半天的蛋疼体验了,感觉一下子就解决了一机开发+办公+游戏的需求,完全不需要什么 vmware 、mac 、docker 啥的,全部都放在 wsl 里。 这样既有了贴合生产环境的开发环境,还能有接近 windows native 90%的 IDE 使用体验以及极大提升的命令行工具,还买啥 m1,立马取消订单了(省的钱准备拿去买排骨吃 /狗头 | ||||||||||||||||
| Posted: 07 May 2021 05:16 AM PDT 地区被锁在中国区,通过删账号清除数据解决了。万幸 | ||||||||||||||||
| Posted: 07 May 2021 05:09 AM PDT 简历排版太头疼了,有没有模板抄一抄的? 最好直接 Github 上的 🙄 | ||||||||||||||||
| VSCode 的这个叫做 Solarized Light 的配色主题很有 Notion 的感觉 Posted: 07 May 2021 05:04 AM PDT  | ||||||||||||||||
| 2021 年了,如何从零入门 Kotlin ?然后能迅速做出一个 Android 应用程序。 Posted: 07 May 2021 04:52 AM PDT 如标题所示 | ||||||||||||||||
| 设计函数时如何界定何时需要捕获异常并自己处理,何时需要抛出异常给调用方? Posted: 07 May 2021 04:49 AM PDT 比如 A 方法调用 B 方法,什么情况 B 要捕获异常自己处理,什么情况要抛给 A 去处理呢?我理解如果异常的产生和 A 调用传入的参数等无关,是 B 本身的问题,就要 B 自己处理,反之要抛给 A 。不知道理解的对不对? | ||||||||||||||||
| Posted: 07 May 2021 04:43 AM PDT 背景自我介绍下,四年工作经验,头两年全栈开发,后两年专职做前端,目前已达到高级前端工程师水平,经历过三家公司。第一家公司,电商行业,做阿里 入职时的环境这是一家做保险和金融行业的公司,属于传统行业的科技公司,有点外包的性质,当然,也有自己的 前端组 4 个人其中一个归 CTO (做后端) 管,另外两个在广东,我入职的时候,也没有确认,到底要不要带人。我来的时候,就已经在了,后面我领导跟我说,要带下他们,我当时压根就没有带人的想法,也是个坑。 历史项目有很多个,都是基于一套从 GitHub 上弄过来的项目框架
基于以上的原因,向领导提出过重构,没有同意,我认为可能有两个方面的顾虑,
项目人员能力较弱
前后端接口对接,没有相关的文档产品画的原形 和 UI 设计稿不规范列举了以上的这些点,烂摊子太多了,好在有一个点,领导的支持力度还不错,看我是如何突围的。 明确自己的任务前端技术建设的核心目的,是为了提高开发效率,保证开发质量,为保障项目高质量按时交付,同时兼顾考虑中长期研发实际情况,结合团队实际能力,为未来做技术储备,为业务发展提供更多的可能性,大概将自己的分为以下四类
如何解决首先,要对现有的问题进行梳理归纳,按照问题的优先级进行排序,然后,分阶段性目标进行实现,对于上面的问题,我大概整理了一张表格
团队管理人员管理
权限管理主要是指代码权限控制,目的是确保代码安全,问题可控可避免可追溯 具体管理举措有以下几条:
前后端接口对接前后端开发联调有一个严重问题,就是后端接口变动或者字段改动时,没有在事前事后通知相应前端开发,测试人员,导致效率底下,并且会出现各种异常情况。 因此,通过梳理开发流程,出接口文档,作为对接标准。 我们使用 但在实际情况中,还是会有一些接口文档和实际接口不符的情况发生,导致一些问题产生,这个我们也在思考。 前端工程化体系刚入职的时候,由于上面的项目框架问题太多,之前也尝试过解决,但,解决不了,领导也意识到了这点,而且也有新项目进来,就让我重新搞一套项目框架。所以,我自研了一套基于 基础架构设计Git 分支管理规范化我们使用的是
分支命名规范
分支说明
提交信息规范提交信息应该描述"做了什么"和"这么做的原因",必要时还可以加上"造成的影响",主要由 3 个部分组成: Header Header 部分只有 1 行,格式为 type 用于说明提交的类型,共有 8 个候选值:
subject 用于概括提交内容。 Body 省略 Footer 省略 这样做起来的好处,这个项目下:
总之,一目了然。 开发人员基本流程在这个流程中,开发人员只对个人仓库拥有可控权,无法直接改变公司仓库代码,当需要提交到公司仓库下时,需要发起 主分支代码和线上代码进行隔离,由组长将指定版本的 通过以上流程,前端代码能保证高质量,高稳定性的状态,运行在服务器端。 工程化设计要根据实际业务情况和团队规模,技术水平来做,关键是要形成一个闭环,所谓闭环就是从零开始到上线再到迭代的全链路,有很多节点,这些节点需要根据实际情况进行设计,避免过度设计。 定制 Webpack 项目框架为何不是 create-react-app create-react-app 是基于 为何不是 umi umi 提供的功能很多,这也导致它太过于臃肿。而且你还要去学它的封装化配置,而不是学原生第三方库的配置,如果你只想要一些简单的功能,追求更高的可玩性,哪 umi 不太适合。 所以,我自己定制了一套脚手架,实现了以下功能:
解决了以下的问题:
完成整个编码过程的一个闭环:
这些节点要视实际情况,以最小成本去做,然后逐步升级。比如编码规范,我们是采用业界比较著名的 这套项目框架,目前开发体验非常爽,在我司多个产品线上,投入使用,并已开源,**框架地址**,演示页面比较少,大佬们觉得不错的话,可以给个 Star 🌟,也欢迎给项目提 issues ~ 业务场景我们是做 针对公司的实际业务场景,其他子系统不会特别复杂,页面也不会多,共享一套账号体系,这里采用的思路是只有一个项目,不分主从系统,通过 如果子系统特别复杂,有主从系统概念,可以考虑使用微服务设计,这里不做过多介绍。 静态资源除了业务代码以外,前端还会有一些公共静态资源,例如 对于这些文件,是所有项目所共享的,假如这些文件分散在各个项目里,既没必要,也容易导致不同项目依赖文件不统一。 我们是放在 项目管理
熟悉产品线业务所谓技术服务业务,找产品了解现有的业务流程以及痛点,甚至未来要做的一些产品规划,好的技术架构,要考虑各种各样的业务场景,怎样才能结合业务的复杂度,设计出颗粒度更加细化的组件。 画出产品架构图 提升相关人员的能力产品人员需求频繁且混乱,决策摇摆不定、动辄推倒重来。市面上一个好的产品经理是很贵的,没个三四万是拿不下一个真正靠谱的能抗住复杂产品线的产品经理,但是很多公司老板是不愿意花这个钱,一般就会招个工作一两年的产品经理先过来,顶个位置把这个工具给做出来就行了。恰恰因为这样一个认知导致产品经理这一层他既没话语权,又不能让自己闲着,所以层出不穷的需求全堆上来了,而对于公司长久型的产品架构就把控不住,如果一个产品经理无法起到,上对客户负责,下对开发负责,不会对所有需求进行筛选,把需求只会丢给开发,不会进行工时把控和质量把控。甚至对现有产品有什么功能,都不了解,那么就不是一个合格的产品。 所以对产品经理的要求非常严格,因为一个公司,如果战略方向把握住了,那么核心是要看产品,能否把握住市场方向,非常关键。这样才能决定你是否能占有市场,由于我司是做一个 测试人员对测试人员,尽量覆盖全所有场景,保证核心流程畅通,要求能找到复现步骤,提高开发解决 BUG 的效率。 设计规范由于我司采用的是 某个列表页 普通的列表,和设计,产品都约定好,上面是筛选,下面是按钮,底部是表格展示。 某个详情页 详情页大量会使用到表单,所以直接使用 表单每行放多少个,都是以 这样带来的好处就是尽量避免定制化的开发,所有列表和详情都是按照这种风格来进行开发。 总结上面这些,包含其他的,大概花了一年多的时间,建设完成,我们目前的基建状况如下表所示 前端人员的开发效率较之前,提升了一倍左右的开发效率,前提是完全熟悉我这套项目框架的开发模式。 项目管理,人员工时占比,资源协调,目前下来都还不错,平稳进行。 如果你觉得对你有帮助或启发,欢迎点赞留言。 | ||||||||||||||||
| Posted: 07 May 2021 04:30 AM PDT ## 1.封装 1PB 的成本(仅供参考) 计算基准:黑石大数据机型 BMD3c 8255C*2/2933-32G*12/HDD-12T*12/SSD-480G*2/NVMeSSD-3.84T*1/HBA-25GE*2, 大概并发 24 个 plots,1TB 文件,12 个小时,一天两轮,大概能封装 4.8TB 数据 按 1 个月完成 1PB 封装,按目录价算 347729 元,费用预估构成如下: 1 )黑石:BMD3c 19230 元 /月(包月方式),封装 1PB,需 7 台 BMD3c 封装 1 个月; - 成本=19230*7=134610 元 | ||||||||||||||||
| 7zip 官方 7-Zip 21.02 alpha (2021-05-06)源代码编译... Posted: 07 May 2021 04:24 AM PDT 7-Zip 21.02 alpha (2021-05-06): https://www.7-zip.org/a/7z2102-linux-x64.tar.xz 这个官方发布的命令行版本在 centos7 里会报错,应该是官方编译版本对 libstdc++.so 有要求: ./7zz: /lib64/libstdc++.so.6: version `CXXABI_1.3.8' not found (required by ./7zz) ./7zz: /lib64/libstdc++.so.6: version `CXXABI_1.3.9' not found (required by ./7zz) # ls -l /usr/lib64/libstdc++.so.6 lrwxrwxrwx. 1 root root 19 Apr 5 01:58 /usr/lib64/libstdc++.so.6 -> libstdc++.so.6.0.19 # strings /usr/lib64/libstdc++.so.6.0.19 | grep CXXABI CXXABI_1.3 CXXABI_1.3.1 CXXABI_1.3.2 CXXABI_1.3.3 CXXABI_1.3.4 CXXABI_1.3.5 CXXABI_1.3.6 CXXABI_1.3.7 CXXABI_TM_1 但是升级 libstdc++.so 容易造成别的应用混乱,想折腾下在 centos 7 下自己源码编译...但是搜了 google,发现大多是在 windows 下用 VSC 编译.exe 的教程.坛里有大佬折腾过 linux 下怎么编译么?求指教 PS:主要是 7zip 这货在 windows 和 linux 下都太好用了... | ||||||||||||||||
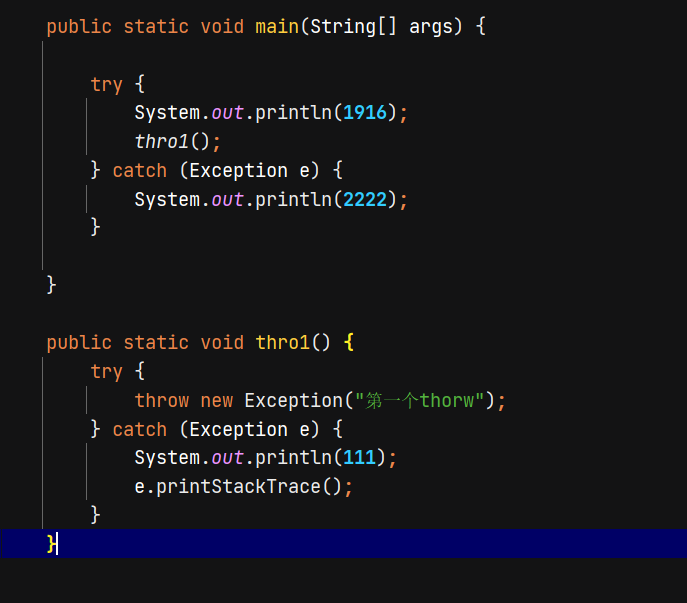
| Java try catch 代码块中调用层级 catch 的捕捉问题 Posted: 07 May 2021 04:12 AM PDT 之前为了捕捉到 http 请求超时的异常信息想直接 catch 到异常内容,结果发现 catch 里面的代码块根本不走,后来自己试了一下如图: | ||||||||||||||||
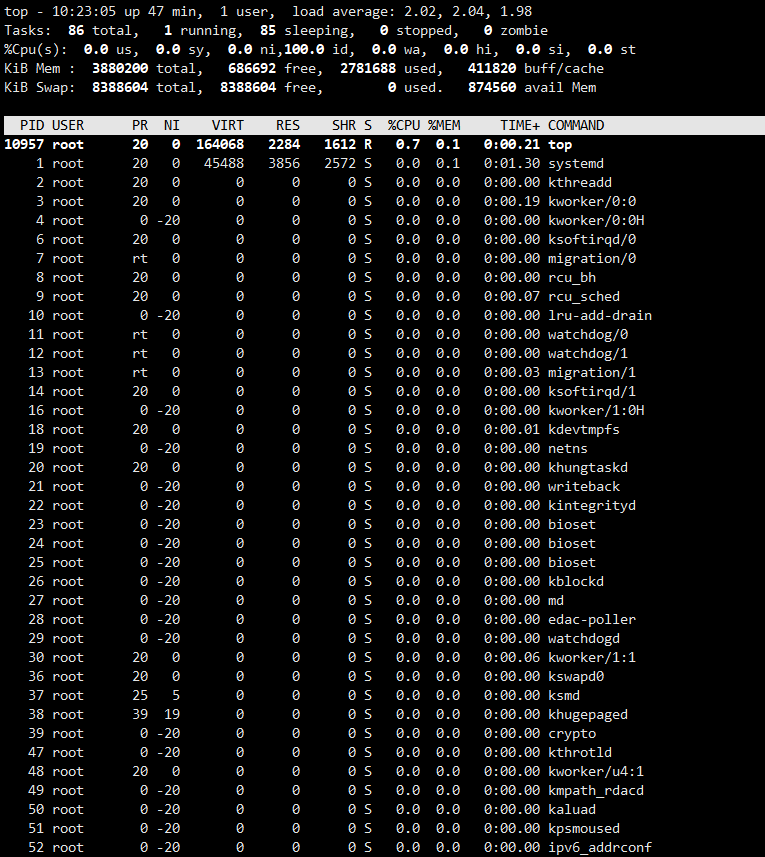
| Posted: 07 May 2021 03:40 AM PDT 前段时间买腾讯的 1H2G5M 学生轻量云,然后升级了 2H4GB6M ;但是现在发现内存占用太高了,重启之后就会占用近 3G 的内存,导致后面起了 docker 跑了两个 java demo 服务虚拟内存占用过多卡的不行,个人感觉内存并没有升级到 4G,这种有人知道怎么整吗? 重启之后没开任何服务的内存占用: top 里面也没有进程占用比较多的内存: | ||||||||||||||||
| XCode 里下载不到 ios 12 以下的镜像了,排查问题好不方便,到底咋想的? Posted: 07 May 2021 03:39 AM PDT APP 支持到 9.0,用户是 10.3 ; 公司没有对应版本的测试机可以复现,打算用模拟器,下完 XCode 发现只能下载 12+的镜像; 什么鬼?苹果处于什么目的? | ||||||||||||||||
| 求推荐,有啥简单好用的容器服务吗, docker-compose 一配,文件上传就运行,不用买集群啥的 Posted: 07 May 2021 02:55 AM PDT 1G 单核用 docker 压力有点大,今天卡死好几次了 | ||||||||||||||||
| Posted: 07 May 2021 02:28 AM PDT 今天作为面试官面了个应聘初级 Java 的程序员,该程序员工作 3 年,因为是初级,先问了几个简单的问题: 1 、final 修饰的变量到底是指引用不能变还是引用的对象内容不能变? 答曰:引用的对象内容不能变 2 、有两个 Integer 类型的变量,他们的值都是 100,如果用==比较,结果是什么? 答曰:false,他说==比较的是内存地址 3 、关于 MySQL 的索引问题,like 会不会走索引? 答曰:不会,而且还特别补充了一句,只要用到了 like 都不会走索引。 4 、创建线程有哪几种方式? 答曰:只知道线程池的方式,其他方式不清楚(然后我顺着这个问了他线程池,结果他说工作中没有用到过线程池,对线程池不是特别了解)。 但其他的理论性东西又答的还可以,估计是背的面试题。 | ||||||||||||||||
| 关于 kotlin 安卓开发,网络框架有用 Retrofit+协程的方式实现的吗,真的好用吗 Posted: 07 May 2021 02:14 AM PDT 刚刚在看相关文章,自己也动手实现了下,发现并不怎么好用啊,还是说我没 get 到 viewmodel 里面请求接口,结果封装成 sucessLiveData 、errorLiveData 、loadingLiveData,ui 界面监听 livedata 更新 ui 1.某些接口如果请求失败会把错误数据以 httpexception 的方式返回到客户端,这种方式好像没办法同时兼容统一处理业务的错误数据和 exception 的错误数据 2.很多页面都是多个请求,单一的 sucessLiveData 、errorLiveData 处理好像并不太优雅 2 可以通过不同的接口建不同的 livadata 来解决,主要是 1,应该怎么处理呢 | ||||||||||||||||
| Posted: 07 May 2021 02:02 AM PDT | ||||||||||||||||
| pymssql 在插入数据库操作时候网络断开应该如何捕获异常? Posted: 07 May 2021 01:53 AM PDT 如题,找了好多帖子没有找到办法! 使用 try: except: 无法捕获异常,程序直接退出,我代码如下: | ||||||||||||||||
| Posted: 07 May 2021 01:21 AM PDT 除了 a 都是变量(在运行时都是常量),所以这是一个只含有一个未知数的方程组,求 a 的表达式。 Symbolab 好像不支持用字母表示常量,是不是用法不对?
| ||||||||||||||||
| Posted: 07 May 2021 01:20 AM PDT 网上说法千奇百怪,DDD 分层导致实体转来转去,标准是什么,好处到底是什么 | ||||||||||||||||
| 在 boss 上看到有一些对外的岗位和一些远程的岗位工资很高 Posted: 07 May 2021 12:42 AM PDT 三线城市程序员,前两天在 boss 上看到有一些对外的岗位和一些远程的岗位工资很高,但要求有流利的英语口语。我觉得自己的阅读能力尚可,但是口语方面确实不行,请问一下大家,如果辞职去练英语口语,练到可以流利沟通的程度,再来找工作,是否可行。 | ||||||||||||||||
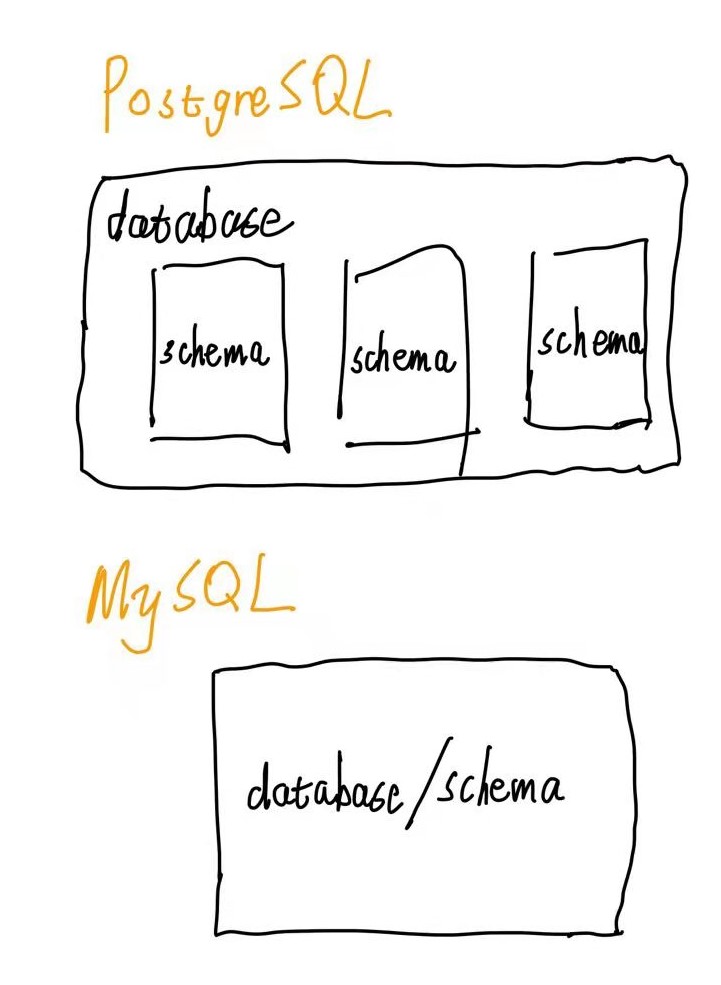
| PostgreSQL 和 MySQL 中 schema 的区别 Posted: 06 May 2021 11:47 PM PDT 背景公司同事对于 schema 的概念比较模糊。 PostgreSQL 、MySQL 、SQL Server 、Oracle 都有 schema (模式)的概念,并且在实际应用中体现的作用不大一样,这里重点解释 PostgreSQL 和 MySQL 的 schema 。 区别PostgreSQLschema 在同一个数据库中可以创建多个,每个 schema 可以拥有相同表名的表。 假设有 MySQL与 PostgreSQL 不大一样,在 MySQL 的 database 和 schema 是同一个概念,所以在 MySQL 中不会特别提及 schema 。 MySQL 中,可以同时操作多个数据库( 和 schema 的概念一致 ) 示意图
PostgreSQL 中 schema 的优势
| ||||||||||||||||
| Posted: 06 May 2021 11:33 PM PDT ECS 在华南 1 深圳 A,想搞个最便宜的基础版 MYSQL,但同地域内 ESSD 的云盘可用区只有 D 和 E 可选,虽然 SSD 有可用区 A 但据说 SSD 云盘的 IO 比较差。 不知道基础版 MYSQL 后续会不会再在 A 可用区上架,到底是再等等还是直接买不同可用区的 RDS 。 请教用过同地域跨可用区的 v 友,跨可用区的内网访问延迟如何?和同可用区内的延迟相比差别大么? 谢谢 | ||||||||||||||||
| PHPStorm 的 Ctrl + / 的单行注释,只能顶头加嘛? Posted: 06 May 2021 11:08 PM PDT | ||||||||||||||||
| 在 Windows 上使用_vscwprintf 处理 UTF-8 编码的字符串时失败,该如何解决? Posted: 06 May 2021 10:02 PM PDT 操作系统:Windows 10 x64 编译器:vs2019, mingw-w64-v8.1.0 项目字符集:UNICODE 项目文件:test_utf8.zip - 蓝奏云 | ||||||||||||||||
| Posted: 06 May 2021 10:00 PM PDT 在氧 os 下无法收到国产应用的推送,那有没有可能把 oppo push 通过 root 的方式移植到氧 os ? 虽然现在大多数应用的 push 都是广告而不是有效的信息,但是在安卓系统有没有推送和能不能是两码事。 | ||||||||||||||||
| Posted: 06 May 2021 09:30 PM PDT 我们花时间学最新的库,最新的特性,写的时候代码优雅注释清晰,这是为了什么? 写几个无脑的 for 循环,无脑的 if 判断就可以搞定上线,让老板赚钱。因为无论你用什么东西写最后的目的就是能用能上线就行,你写的再 nb 再高端,也不会升职加薪,老板也不懂,甚至因为看不懂你的奇淫巧计而批评你。 而且有时学习新东西用新写法还会耽误自己的时间,自己的的 nb 代码,仅仅在写完的时候让自己爽了,其他人都不在乎,只在乎能用就行,其他的意义还有什么嘛。为了面试吗?如果下一家公司还是这样不就陷入了循环之中嘛。 | ||||||||||||||||
| Posted: 06 May 2021 09:19 PM PDT | ||||||||||||||||
| 谷歌数据集搜索 https://datasetsearch.research.google.com/ Posted: 06 May 2021 08:07 PM PDT | ||||||||||||||||
| Posted: 06 May 2021 06:12 PM PDT 最好是擅长分析和逆思维和反编的,因为要根据目标软件重写服务端和客户端。费用好说,合作也行,利润丰厚,高手联系,新手勿扰,看似简单,难度还是有一点点的。 扣:496237770 | ||||||||||||||||
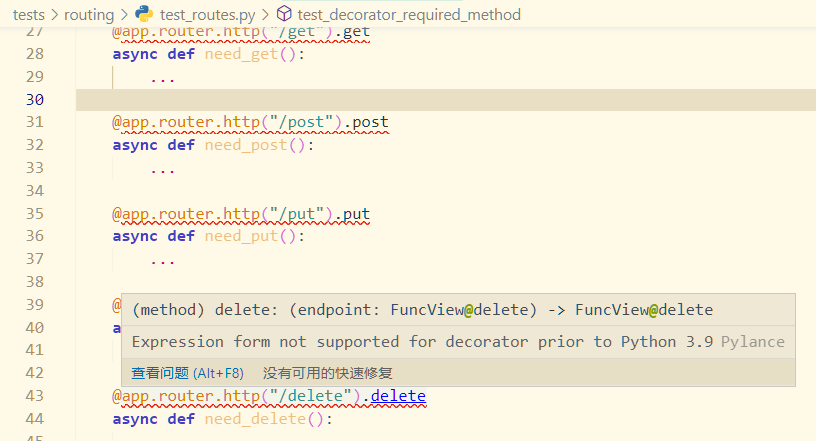
| Posted: 06 May 2021 05:37 PM PDT
偶然想到的 Idea,在保证了向前兼容的情况下,友好的拓展了功能糖。我本地是 3.9 的,这么写完全没问题。然后我的 black 格式检查一直报错说解析不了这个语句,我突然想到之前看 ChangeLog,3.9 好像放宽了装饰器的要求,遂把版本切回 3.7 一看,果然不行。 哭了。Python 什么时候才有那种可以转换代码到指定版本的工具啊(自己试图弄过,相关知识缺口很大,一时半伙搞不出来)。 | ||||||||||||||||
| Posted: 06 May 2021 09:50 AM PDT win7 下面 Git 安装报错,经查是缺少一个 null.sys 驱动,从相同的 win7 下面拷贝了一份,放到了 C:\Windows\System32\drivers 下面,但是不知道怎么安装,请教各位怎么安装这个 sys 驱动文件? | ||||||||||||||||
| Posted: 06 May 2021 09:17 AM PDT 刚接触安卓开发,很多地方不太懂 在应用启动时往往需要进行初始化工作,如连接数据库等。这些代码应该放在哪里合适呢? 目前只能想到 3 个选择:
在 stackoverflow 等地搜了半天,没看到几个相关问题,也几乎没有讨论 希望大佬赐教,谢谢! | ||||||||||||||||
| 我用 type()动态创建了一个类,怎么生成这个类的 Python 源代码??有现成的工具吗?需求的场景是这样的 Posted: 06 May 2021 07:46 AM PDT 如题。通过 type 函数创建一个类,如何生成这个类的 python 代码的形式? 我有一个 json,类似这样 我想用代码生成一个 py 文件,里面是 sqlalchemy 的 model,类似这样 我的想法是用 jinja2 写一个模版,然后往里面填充数据,类似这样 但是感觉这样的方法太笨拙了,请问有高级一点的实现方式吗?比如通过 json, 先用 type()生成一个 model,然后把这个内存对象逆向成字节码,再通过字节码还原成 python 代码??? 不知道我有没有描述清楚,请大佬们帮帮忙 |



| You are subscribed to email updates from V2EX - 技术. To stop receiving these emails, you may unsubscribe now. | Email delivery powered by Google |
| Google, 1600 Amphitheatre Parkway, Mountain View, CA 94043, United States | |
No comments:
Post a Comment