V2EX - 技术 |
- 微信公众号上传图片为何返回 ID 而不是地址?有什么考虑吗
- golang 有按时间/日期切割的 log 库吗?
- 求问 aiohttp 和 requests 库,产生的预期不一致。
- 盆友们,过年都屯什么酒了吗?
- 现在很多人鼓吹 Windows 系统不分区,一个 C 盘,那么重装怎么办呢
- 测试用手机,一直插着 USB,怎么能防止/延缓锂电池鼓包,各位大佬有什么方法不?
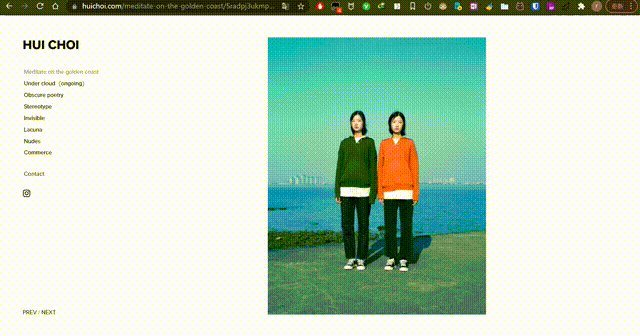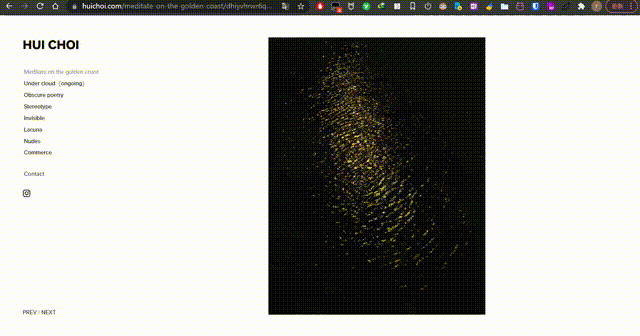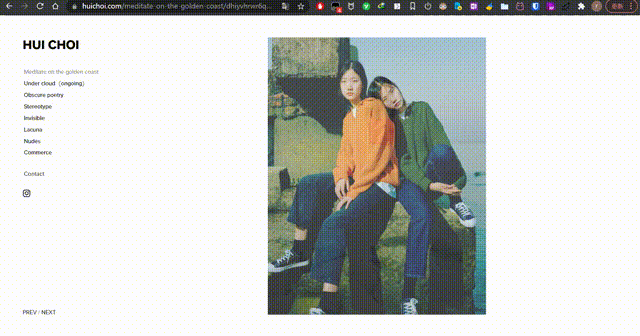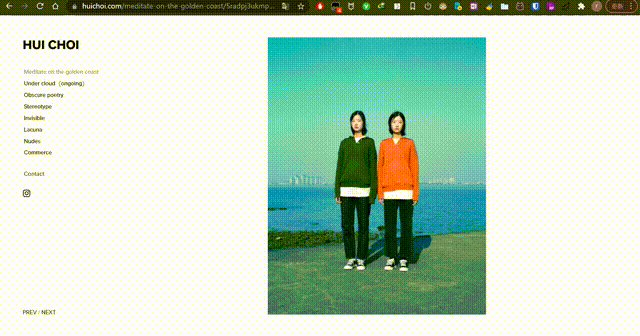
- 请问一下如何做像 https://www.huichoi.com 这个网站一样点击 PREV/NEXT 切换图片?可以简单说下思路、主要用啥,我去学!
- K8S Ingress 只是给局域网用可以吗
- jmeter 最大线程问题
- 如何实现一个压缩追加的功能?求大佬们给点思路
- 本人开发了一个简历 PDF 生成下载的的网站,永久免费!
- 写了一份前端 Linter 的总结教程
- 求教一条 Python 中使用的 sql 语句
- Laravel-Plugin 基于 Laravel 的插件机制解决方案
- 多线程消费, 队列没有清空就退出了, 请教原因, 谢谢!
- 一加现在不让刷氧了吗?
- aws s3 用户上传的文件,如何只允许用户访问
- 请教一个 oracle 的排序问题
- 躺着吃灰 不如物尽其用
- Windows 锁屏下,怎么通过 Python 截图运行桌面
- 反向代理出错后,会出现线程泄露?
- 安卓手机连接 wifi 网络异常求助
- 求问一个关于 Mac 系统唤醒机制的奇异的问题
- 除浏览器插件外,有没有获取 chrome 书签的 API 或方案
- DaoCloud 道客云原生开源项目 Clusterpedia(The Encyclopedia of Kubernetes clusters)加持 kubectl,检索多集群资源
- [K8s 超级补丁] KLTS 新手攻略: KLTS 现有成果、如何使用、RoadMap 规划,如何参与到 KLTS 项目贡献中来?
- 关于 VUE 组件自动调整样式问题
- 线程池的原理(小学篇)一,大家帮我看看呗
- 谁有使用过 JXTA 2 的经验吗
- 关于 Jest 配置的提问
- 请教大佬: 关于印尼盾程序如何处理
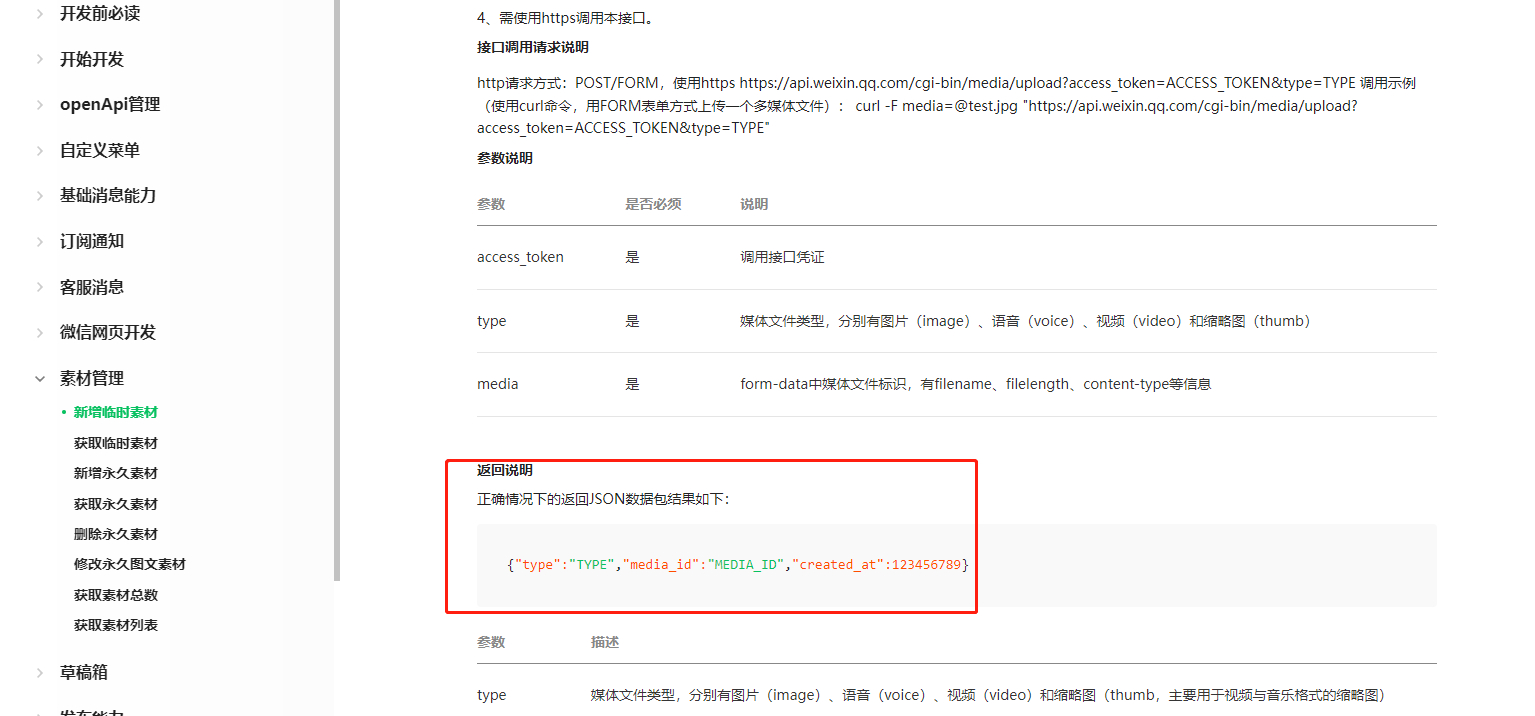
| Posted: 18 Jan 2022 06:57 AM PST https://developers.weixin.qq.com/doc/offiaccount/Asset_Management/New_temporary_materials.html
在获取图片的时候要拿 media_id 去请求
|
| Posted: 18 Jan 2022 06:57 AM PST 类似 log4j/logback 那种的 |
| 求问 aiohttp 和 requests 库,产生的预期不一致。 Posted: 18 Jan 2022 06:56 AM PST 币安的批量撤单接口,发送 DELETE 协议,进行批量撤单。 |
| Posted: 18 Jan 2022 06:45 AM PST 现在白酒都涨的离谱,囤了几瓶留着过年喝。 酒单:水晶剑,金剑南 k6 ,泸州窖龄 30 ,老白汾 10 ,五粮春 |
| 现在很多人鼓吹 Windows 系统不分区,一个 C 盘,那么重装怎么办呢 Posted: 18 Jan 2022 06:39 AM PST 我感觉还是分出一个 C 盘,如果系统出了问题,重装比较方便恢复,或者说现在有更好的办法? |
| 测试用手机,一直插着 USB,怎么能防止/延缓锂电池鼓包,各位大佬有什么方法不? Posted: 18 Jan 2022 06:09 AM PST |
| 请问一下如何做像 https://www.huichoi.com 这个网站一样点击 PREV/NEXT 切换图片?可以简单说下思路、主要用啥,我去学! Posted: 18 Jan 2022 05:54 AM PST 感觉是要用 js |
| Posted: 18 Jan 2022 05:47 AM PST 目前服务暴露方式主要用的是 NodePort 。 但担心这种方式重启服务时,有可能被其他服务占用 Port ,需要对其他上游服务屏蔽 Port 变化。 因此考虑用 Ingress + NGINX Ingress Controller 。 对上游统一通过 VIP + 80 暴露服务,不同 Service 使用不同 path 区分。 现在的问题,似乎 Ingress 似乎只支持 Domain 方式... 请教大佬们,有其他解法嘛...其实我的服务不需要暴露给公网... |
| Posted: 18 Jan 2022 05:18 AM PST 目前在学习 jmeter ,设置的最大线程是 5000 ,但是每次都只能跑到 4054 ,JDK 环境是 1.8.0_312 ,M1Pro ,最大内存 16G ,编辑了 bin 目录下的 jmeter 文件,: "${HEAP:="-Xms1g -Xmx8g -XX:MaxMetaspaceSize=256m"}",Xmx 设置成 2g 和 8g 是有差别的,但是 4g 网上线程都上不去了,求大佬指导一下,具体还有哪里限制了线程。 |
| Posted: 18 Jan 2022 05:18 AM PST 平时开发会有部分场景都是需要压缩,但是每次有新增时就要重新进行压缩,所以就想着是不是能够向一个压缩包中追加文件来节约性能。目前网上的文章都搜不到,特来此寻求帮助(花花) |
| Posted: 18 Jan 2022 05:12 AM PST 其它在线制作简历的平台模板和下载都收费,所以我做了一个在线简历生成的工具,pdf 文件一键下载,永久免费。 模板后期也会继续补充,大家有什么使用上建议可以给到我哦~ |
| Posted: 18 Jan 2022 04:53 AM PST 最近在搞项目的基建,在配置 ESLint 和 Prettier 的时候感觉非常痛苦:NPM 的包太多了,而且名字又太像: eslint-plugin-prettier, eslint-prettier, eslint-config-prettier... 不仅配好了 ESLint 还要考虑 ESLint x TypeScript 结合,ESLint x LintStaged 结合等等一堆东西。受不了了,所以直接重新学习了一下前端 Linter 这块的内容,最后写了一份总结: 希望可以帮助前端 er 来理解这些概念。如何你看完这个教程后再看自己项目的 .eslintrc, .prettierrc 以及 package.json 里相关 NPM 包时,都能知道他们什么意思,那这个教程的目的就达到了。 因为网上对这些工具的介绍都比较简单,所以我能参考的资源也比较少,一般来自文档、Issue 和 Wiki ,所以如果你发现了错误,或者你有更好的配置方案,也可以提 Issue ,不要喷太重哈~ 小弟我已经尽力了。 这里依然有两个问题我没能解决:
目前我翻看了网上一些文章和文档,都没找到更好的解决方案,小弟我已经尽力了。 |
| Posted: 18 Jan 2022 04:22 AM PST Python 业余编程爱好者,查了好久都没解决,来请求下帮助 当以下这样写时没问题 condi1 = 'code like' + '"%' + str(code) + '%"' condi2 = 'code like' + '"%' + str(code2) + '%"' df = pd.DataFrame(pd.read_sql('select * from f63 where ' + condi1 + ' OR ' + condi2, conn)) 但我想写成 code = 就会报错 condi1 = 'code =' + '"%' + str(code) + '%"' condi2 = 'code =' + '"%' + str(code2) + '%"' df = pd.DataFrame(pd.read_sql('select * from f63 where ' + condi1 + ' OR ' + condi2, conn)) 请问是不是"="转义的问题? 如果是,应该怎么表达,有查到用\,也有用",甚至和 Python 里的 r'有点概念混一起分不清了 |
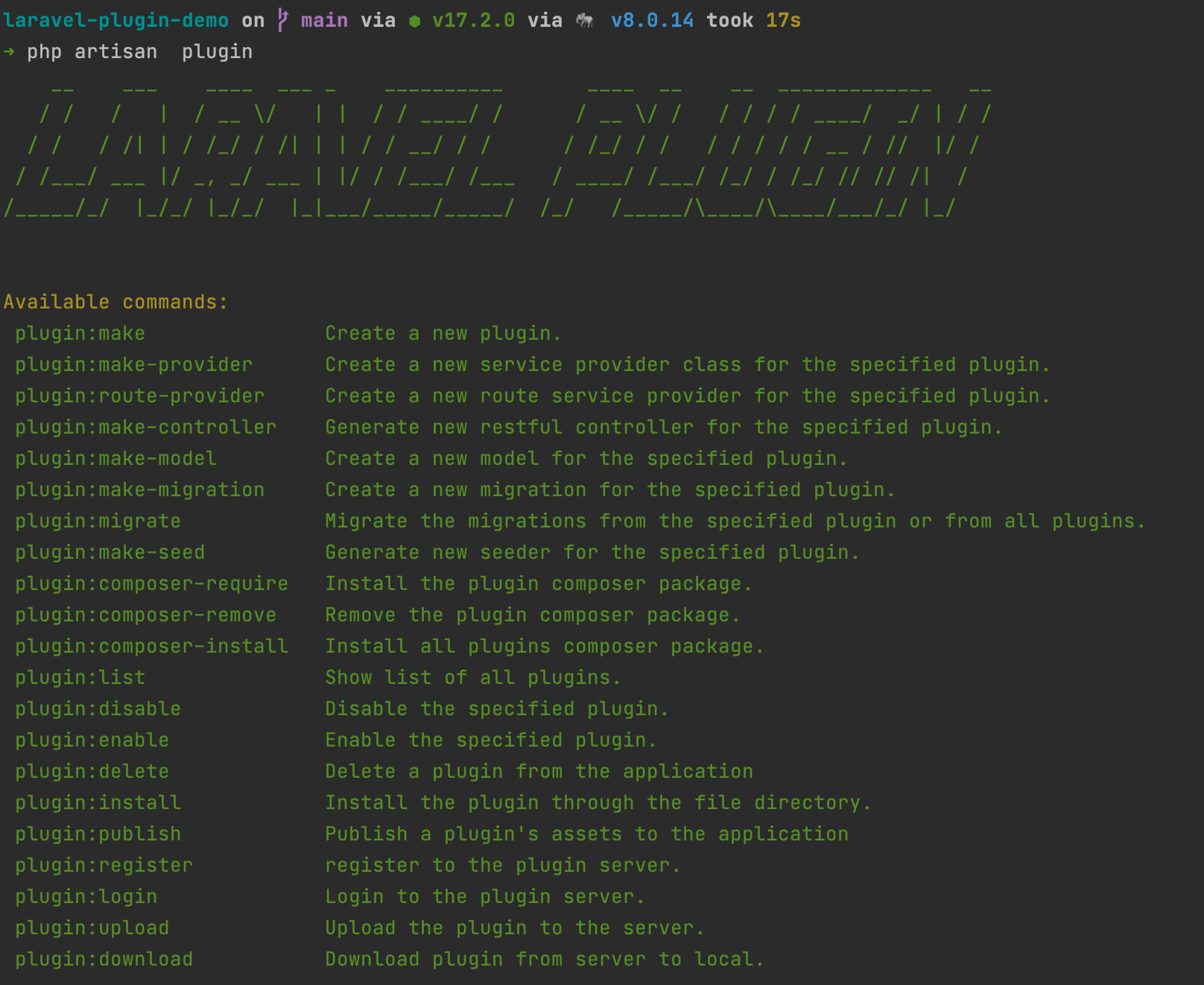
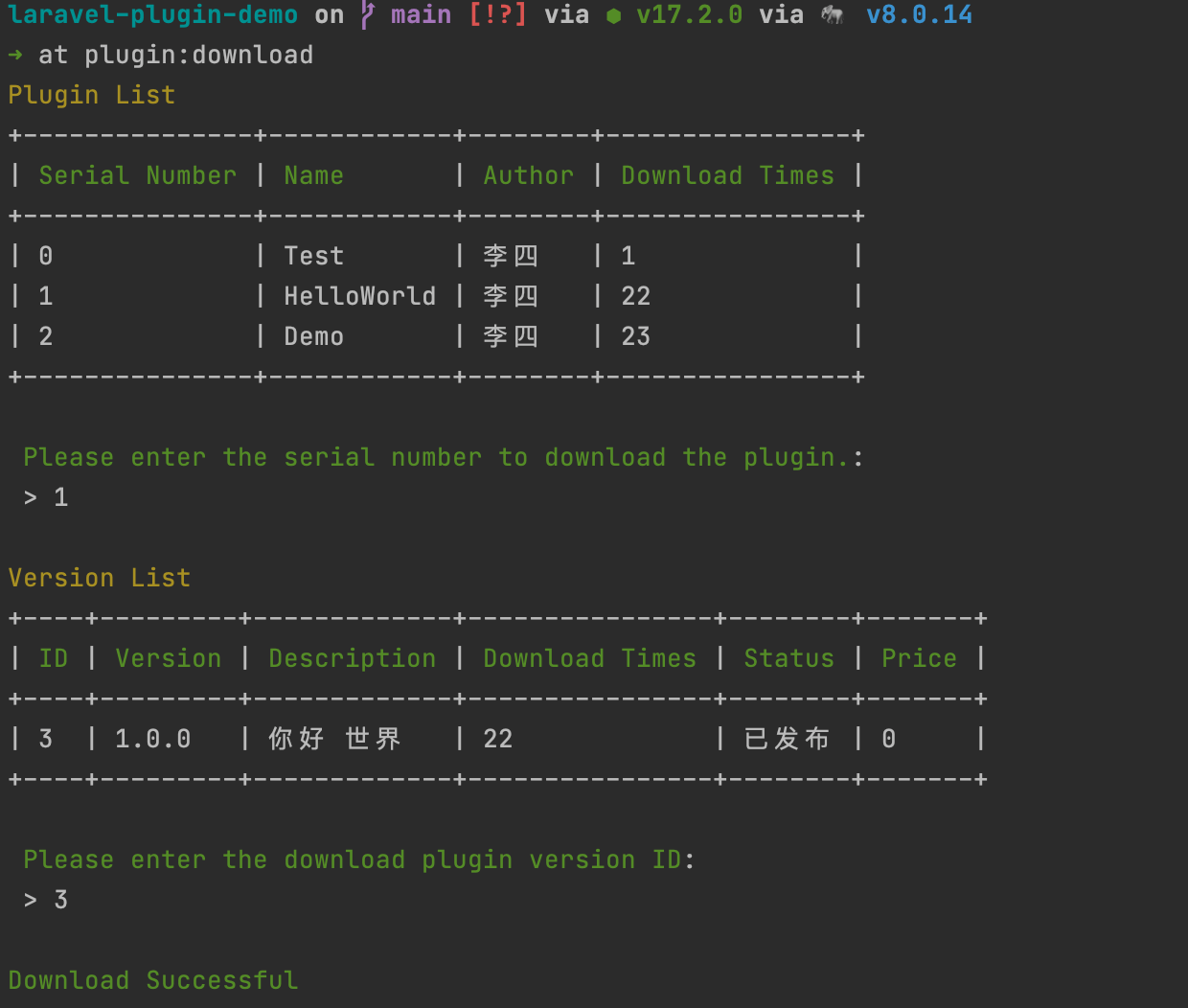
| Laravel-Plugin 基于 Laravel 的插件机制解决方案 Posted: 18 Jan 2022 03:13 AM PST 介绍Laravel Plugin 是为需要构建自己生态的开发者提供的插件机制解决方案,使用它您可以构建类似 wordpress 的生态。它能为您提供的帮助如下:
文档地址欢迎在 GitHub Star Laravel-Plugin 场景想做一个开源版本的 erp ,开源版本只有简单的进销存功能,我希望用户可以以插件的形式购买我的生成加工,财务核算,数据报表等功能。这样以开源的形式还可以盈利。同样如果你做一款开源商城,cms 同样可以用 Laravel-Plugin 构建你的插件生态。 快速制作并上传你的第一个插件安装好 Laravel-Plugin 以后,在命令输入
创建插件通过 注册插件创建好以后,我们需要注册一个账号才可以上传。我们有两种注册方式
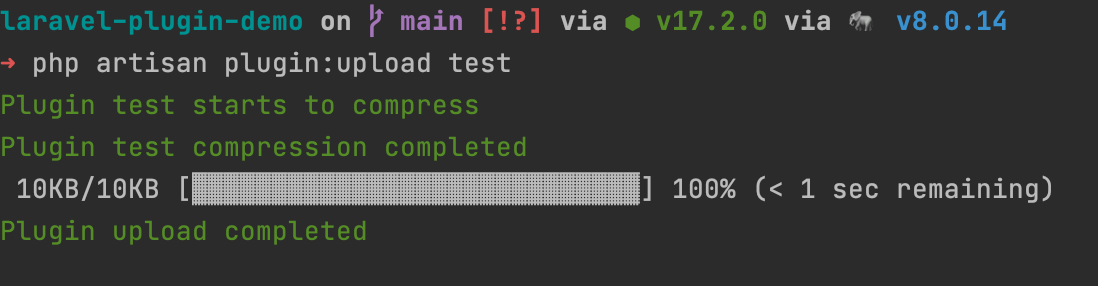
上传注册完成以后执行
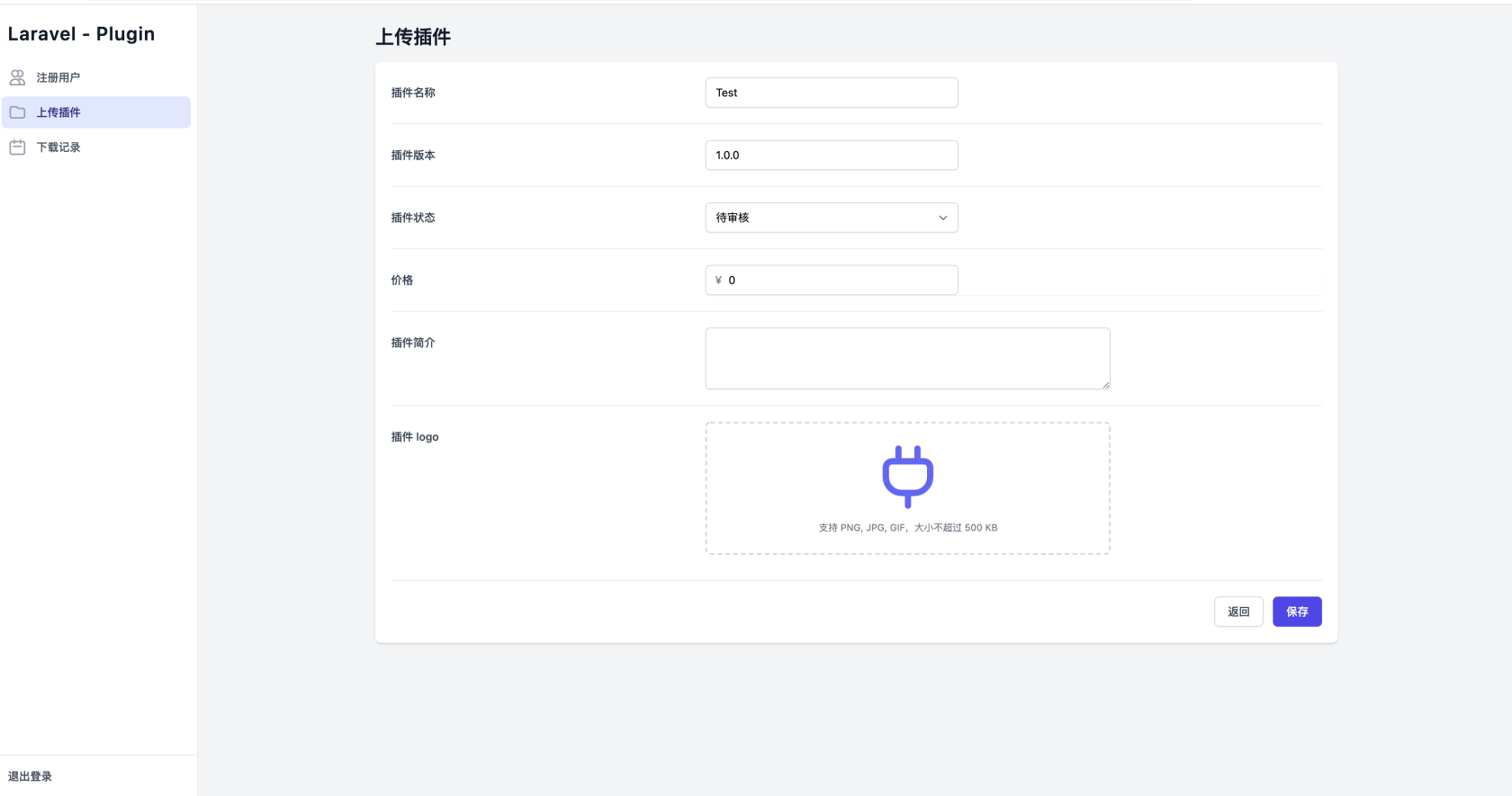
查看上传的插件在 插件市场 登录以后,点击插件管理就可以看到刚刚上传的插件。
审核发布插件市场工作人员在后台审核以后,你的插件就可以发布到 插件市场 给他人下载使用了
命令行下载在命令行登录以后,你可以通过执行
以上介绍了怎么通过 Laravel-Plugin 快速发布你的第一个插件。如果你想对 Laravel-Plugin 有更多的了解,建议仔细阅读 Laravel-Plugin 文档。 插件市场使用 Laravel-Plugin ,默认链接的是我这边用 laravel + vue3 + tailwincss 写的一个基础插件市场,在 Laravel-Plugin 文档 介绍了怎么自定义你自己的插件市场,当然,你也可以找我购买插件市场,后续中我会不断完善插件市场功能。 交流讨论
|
| Posted: 18 Jan 2022 02:52 AM PST 我想通过 ThreadPoolExecutor 使用多个线程来消耗 redis 队列。但进程在队列没有消耗完的情况下退出了 下面是实现代码 请问 bug 写在哪里了? 感谢大佬
|
| Posted: 18 Jan 2022 02:30 AM PST 6T 老机。10.0.10 |
| Posted: 18 Jan 2022 02:28 AM PST 前端开发同学,自己在做后端。 用户通过我们的产品(网站形式),上传的文件保存在 s3 ,如何能只允许用户自己访问(其它人拿到文件的链接不可以访问。) aw3 的文档看着摸不着头脑,是否只能通过 aws IAM 做到? |
| Posted: 18 Jan 2022 02:23 AM PST 目前有一个场景是 条件 A 执行 select * from table order by a, b c ,d 条件 B 执行 select * from table order by b, c, a,d 想请问下 oracle 大佬,oracle 数据能不能实现把这两个语句写成一个语句, 网上查了 case when 的功能和我想要的是完全不是一个东西。 |
| Posted: 18 Jan 2022 01:06 AM PST
还记得那是一个下着小雨的傍晚 我们在五道口的一家商场吃晚餐 来北京挺久了却是我们初次见面 那天我们吃的是烤肉吧还是火锅 五年的记忆两人却陷入相望无言 好想说一句你瘦了变得更好看了 可在这样的时刻去夸你太残忍了 本以为是我先打破这可怕的沉默 百度离你住的很近你确定不去吗 是哦我住在八号线朱辛庄西二旗此行的目的原本就是奔着他来的 可是我想留北京的意图你知道吧 到了这个份上知不知道还重要吗 是或不是去或不去有什么意义吗 站在星巴克门口看着这人来人往 小雨戚戚沥沥似乎在诉说着往事 天不早了我该回去了你也早点走 你和我就这样站着不说话看天空 想留不能留才最寂寞竟是这滋味 广场大妈送过来一把透明的雨伞 十块一把却是我见过最美的浪漫 我将你送上了计程车目送你远去 雨水湿了我的眼眶世界也被淹没 现在这把伞就藏在这个小盒子里 透明的简单的做工粗糙却很好看 伞下面还有硬盘显卡以及火车票 如今写代码的感觉终于就像写诗 我居然真的当程序员八年如青丝 这张卡已经在这里躺了七年有余 与其躺着吃灰舍不得扔不如送人 也好了却这桩心事不再睹物思人 总不该早已相忘江湖还怨天尤人
|
| Windows 锁屏下,怎么通过 Python 截图运行桌面 Posted: 18 Jan 2022 12:52 AM PST 跟各位大佬请求一个问题。 我现在有一个需求是,通过 Python 进行 windows 的全屏截图,但是 Windows 的屏幕是处于锁定状态的。 现在测试,通过 Windows 的 user32 调用的话,直接调用截图功能,只能截取到锁屏的图片,但是通过句柄的方式截图,就只能截取到对应句柄的,还是没有办法截取到运行桌面的截图。 请教:我应该通过什么样的方式截图,才可以在锁屏的情况下,截取到我运行桌面的图片,谢谢。 |
| Posted: 18 Jan 2022 12:17 AM PST 我用 GO 写了一个很简单的反向代理程序,代码如下: 端口 8908 后边是一个 NodeJS socket.io 服务端,现在我通过 NodeJS 向 10086 端口同时发起 1000 个 websocket 连接,这些链接均会被代理到 8908 端口服务,然后将所有连接断开,重复几轮后可见控制台报如下错误: 此时通过 windows 资源监视器可看到反向代理程序线程数为 298 ,通过 Process Explorer 可以看到 Handles 数为 1855 ,并且存在大量 Thread 。 再次建立连接再断开,反向代理程序的线程数持续增长,通过 pprof 可见 threadcreate 此时达到了惊人的 472 ,并一直保持。 似乎是系统端口数量限制导致的错误,然后错误导致线程未被回收? 我是 GO 新手,大家有遇到过这个问题吗? |
| Posted: 18 Jan 2022 12:07 AM PST 昨天小米刷机后发现连接家里 wifi 无法上网,一开始以为是刷机刷出问题了,后来发现家里人的手机也有不能上网的。 目前的问题是可以打开部分网页,qq 和 wx 都可以接受消息,甚至于 b 站都可以打开,但是抖音无法打开,商店无法打开。都显示没有网络 我自己的 iphone 和 ipad 都没有问题。小爱都正常上网 目前我将自己的手机的走软路由后网络恢复了正常,但是依旧不知道是什么问题 问题补充: 测试情况: 小米 11 安卓 12 网页正常 bilibili 正常, 应用商店无法打开,抖音无法打开,部分微信小程序无法打开 一加 7 安卓 11 问题同上 魅族 16 安卓 10 一切正常 苹果 一切正常 电脑 一切正常 措施: 路由器已经全部重新设置过一遍了,reset 手机是线刷的完全初使状态 |
| Posted: 17 Jan 2022 11:41 PM PST 背景:家里一台 Mac ,公司一台 Mac ,家里的平时开着 qq 然后盖盖睡眠 今天公司的 mac 上挂着 qq ,突然提示别的设备登陆 qq 本设备掉线。 赶紧看了看手机 qq 上登录设备的信息,发现最近登陆的只有手机,家里的 Mac ,公司的 Mac 三台, 而且家里的 Mac 的登陆时间就是刚刚提示别的设备登陆的时间。 一开始以为家里进贼了,看了看家里的监控,发现啥事都没有。 想了一圈,最可疑的还是 mac 的唤醒机制。 因为我平时在公司的电脑网页打卡后直接睡眠,但是第二天早上开电脑后,打卡页面显示的当前时间经常是早上 5 点之类明显没人的时间。 但是看了一圈设置,没看见关于自动唤醒的方面设置。有大神知道是啥回事么? |
| 除浏览器插件外,有没有获取 chrome 书签的 API 或方案 Posted: 17 Jan 2022 11:30 PM PST 除浏览器插件外,有没有获取 chrome 书签的 API 或方案,然后导入数据库 |
| DaoCloud 道客云原生开源项目 Clusterpedia(The Encyclopedia of Kubernetes clusters)加持 kubectl,检索多集群资源 Posted: 17 Jan 2022 11:04 PM PST
在多集群时代,我们可以通过 cluster-api 来批量创建管理集群,使用 Karmada/Clusternet 来分发部署应用。不过我们貌似还是缺少了什么功能,我们要如何去统一的查看多个集群中的资源呢? 对于单个集群的资源,我们可以使用 kubectl 来查看搜索资源,但是在想要检索多集群的资源时,貌似没有什么趁手的产品可以使用。这个问题不会再困扰你,因为在 DaoCloud 道客云原生开源项目 Clusterpedia 的加持下,你手上的 kubectl 已经可以用来检索多集群资源啦! 例如,使用 kubectl 来获取多个集群下 kube-system 命名空间内的 deployments 。 $ kubectl get deployments -n kube-system CLUSTER NAME READY UP-TO-DATE AVAILABLE AGE cluster-1 calico-kube-controllers 1/1 1 1 63d cluster-1 coredns 2/2 2 2 63d cluster-2 calico-kube-controllers 1/1 1 1 109d cluster-2 coredns-coredns 2/2 2 2 109d cluster-2 dce-chart-manager 1/1 1 1 109d cluster-2 dce-clair 1/1 1 1 109d 01 Clusterpedia 介绍 Clusterpedia ,名字借鉴自 Wikipedia ,同样也展现了 Clusterpedia 的核心理念 —— 多集群的百科全书。 通过聚合多集群资源,在兼容 Kubernetes OpenAPI 的基础上额外提供了更加强大的检索功能,让用户更快更方便的在多集群中获取到想要的任何资源。 当然 Clusterpedia 的能力并不仅仅只是检索查看,未来还会支持对资源的简单控制,就像 wiki 同样支持编辑词条一样。 架构设计 Clusterpedia 在架构上分为四个部分: Clusterpedia APIServer:以 Aggregated API 的方式注册到 Kube APIServer ,通过统一的入口来提供服务。 ClusterSynchro Manager:管理用于同步集群资源的 Cluster Synchro 。 Storage Layer (存储层):用来连接操作具体的存储组件,然后通过存储层接口注册到 Clusterpedia APIServer 和 ClusterSynchro Manager 中。 存储组件:具体的存储设施,例如 mysql ,postgres ,redis 或者其他图数据库。 另外,Clusterpedia 会使用 PediaCluster 这个自定义资源来实现集群认证和资源收集配置 Clusterpedia 还提供了可以接入 mysql 和 postgres 的默认存储层。 Clusterpedia 并不关心用户所使用的具体存储设置是什么,用户可以根据自己的需求来选择或者实现存储层,然后将存储层以插件的形式注册到 Clusterpedia 中来使用。 特性和功能 支持复杂的检索条件,过滤条件,排序,分页等等 支持查询资源时请求附带关系资源 统一主集群和多集群资源检索入口 兼容 kubernetes OpenAPI, 可以直接使用 kubectl 进行多集群检索, 而无需第三方插件或者工具 兼容收集不同版本的集群资源,不受主集群版本约束, 资源收集高性能,低内存 根据集群当前的健康状态,自动启停资源收集 插件化存储层,用户可以根据自己需求使用其他存储组件来自定义存储层 高可用 02 部署 Clusterpedia 关于部署的详细流程,可以查看 README ,这里着重介绍了如何使用 clusterpedia 。https://github.com/clusterpedia-io/clusterpedia#%E9%83%A8%E7%BD%B2 03 集群资源收集 clusterpedia 部署完成后,我们可以通过 kubectl 来操作 PediaCluster 资源。 $ kubectl get pediaclusters 在 examples 目录下,可以看到 PediaCluster 的示例 apiVersion: clusters.clusterpedia.io/v1alpha1 kind: PediaCluster metadata: name: cluster-example spec: apiserverURL: "https://172.30.43.41:6443" caData: "" tokenData: "" certData: "" keyData: "" resources:
caData , tokenData , certData , keyData 字段用于集群的验证。 当前暂时不支持从 ConfigMap 或者 Secret 中获取验证相关的信息,不过已经在 Roadmap 中了。 在设置验证字段时,注意要使用 base64 后的字符串 在 examples 目录下提供了生成用于访问子集群的 rbac yam clusterpedia_synchro_rbac.yaml ,来方便的获取子集群的权限 token 。 在子集群中部署该 yaml ,然后获取对应的 token 和 ca 证书。 $ # 当前 kubectl 连接到子集群中 $ kubectl apply -f examples/clusterpedia_synchro_rbac.yaml clusterrole.rbac.authorization.k8s.io/clusterpedia-synchro created serviceaccount/clusterpedia-synchro created clusterrolebinding.rbac.authorization.k8s.io/clusterpedia-synchro created $ SYNCHRO_TOKEN=$(kubectl get secret $(kubectl get serviceaccount clusterpedia-synchro -o jsonpath='{.secrets[0].name}') -o jsonpath='{.data.token}') $ SYNCHRO_CA=$(kubectl get secret $(kubectl get serviceaccount clusterpedia-synchro -o jsonpath='{.secrets[0].name}') -o jsonpath='{.data.ca.crt}') 复制 ./examples/pediacluster.yaml, 并修改 .spec.apiserverURL 和 .metadata.name 字段,并且将 $SYNCHRO_TOKEN 和 $SYNCHRO_CA 填写到 tokenData 和 caData 中。 使用 kubectl apply 创建。 $ kubectl apply -f cluster-1.yaml pediacluster.clusters.clusterpedia.io/cluster-1 created 为了方便后续使用,建议再创建一个 cluster-2 资源收集 可以通过设置 spec.resources 字段的 group 和 group 下的 resources 来进行指定收集的资源。 在 status 中我们也可以看到资源的收集状态。 status: conditions:
resources:
version: v1.22.2 04 资源检索 配置好我们需要收集的资源后,我们就可以进行重头戏了 —— 集群检索 clusterpedia 支持两种资源检索: 兼容 Kubernetes OpenAPI 的资源检索 集合资源 (Collection Resource) 的检索 $ kubectl api-resources | grep pedia.clusterpedia.io collectionresources pedia.clusterpedia.io/v1alpha1 false CollectionResource resources pedia.clusterpedia.io/v1alpha1 false Resources 为了方便我们更好的使用 kubectl 来进行检索,我们可以先通过 make gen-clusterconfig 来为子集群创建用于检索的 '快捷方式'。 $ make gen-clusterconfigs ./hack/gen-clusterconfigs.sh Current Context: kubernetes-admin@kubernetes Current Cluster: kubernetes Cluster "clusterpedia" set. Cluster "cluster-1" set. 使用 kubectl config get-clusters 可以查看当前支持的集群。 其中 clusterpedia 是一个特殊的 cluster ,用于多集群检索,以 kubectl –cluster clusterpedia 的方式来检索多个集群的资源。 多集群资源检索 我们先看一下我们都收集了哪些资源,只有被收集的资源才可以进行检索。 $ kubectl --cluster clusterpedia api-resources NAME SHORTNAMES APIVERSION NAMESPACED KIND pods po v1 true Pod deployments deploy apps/v1 true Deployment 可以看到当前收集并支持 pods 和 deployments.apps 两种资源 查看所有集群的 kube-system 命名空间下的 deployments $ kubectl --cluster clusterpedia get deployments -n kube-system CLUSTER NAME READY UP-TO-DATE AVAILABLE AGE cluster-1 calico-kube-controllers 1/1 1 1 63d cluster-1 coredns 2/2 2 2 63d cluster-2 calico-kube-controllers 1/1 1 1 109d cluster-2 coredns-coredns 2/2 2 2 109d cluster-2 dce-chart-manager 1/1 1 1 109d cluster-2 dce-clair 1/1 1 1 109d 查看所有集群的 kube-system, default 命名空间下的 deployments $ kubectl --cluster clusterpedia get deployments -A -l "search.clusterpedia.io/namespaces in (kube-system, default)" 查看 cluster-1, cluster-2 两个集群下的 kube-system, default 命名空间下中的 deployments $ kubectl --cluster clusterpedia get deployments -A -l "search.clusterpedia.io/clusters in (cluster-1, cluster-2),\ NAMESPACE CLUSTER NAME READY UP-TO-DATE AVAILABLE AGE kube-system cluster-1 calico-kube-controllers 1/1 1 1 63d kube-system cluster-1 coredns 2/2 2 2 63d default cluster-1 dao-2048-2048 1/1 1 1 20d default cluster-1 hello-world-server 1/1 1 1 26d default cluster-1 my-nginx 1/1 1 1 39d default cluster-1 phpldapadmin 1/1 1 1 40d kube-system cluster-2 calico-kube-controllers 1/1 1 1 109d kube-system cluster-2 coredns-coredns 2/2 2 2 109d kube-system cluster-2 dce-chart-manager 1/1 1 1 109d kube-system cluster-2 dce-clair 1/1 1 1 109d 显示数据有删减,略多 查看 cluster-1, cluster-2 两个集群下的 kube-system, default 命名空间下中的 deployments ,并根据资源的名字排序 $ kubectl --cluster clusterpedia get deployments -A -l "search.clusterpedia.io/clusters in (cluster-1, cluster-2),\ kube-system cluster-1 calico-kube-controllers 1/1 1 1 63d kube-system cluster-2 calico-kube-controllers 1/1 1 1 109d kube-system cluster-1 coredns 2/2 2 2 63d kube-system cluster-2 coredns-coredns 2/2 2 2 109d default cluster-1 dao-2048-2048 1/1 1 1 20d kube-system cluster-2 dce-chart-manager 1/1 1 1 109d kube-system cluster-2 dce-clair 1/1 1 1 109d kube-system cluster-2 dce-registry 1/1 1 1 109d kube-system cluster-2 dce-uds-storage-server 1/1 1 1 109d default cluster-1 dd-airflow-scheduler 0/1 1 0 53d default cluster-1 dd-airflow-web 0/1 1 0 53d kube-system cluster-2 metrics-server 1/1 1 1 109d default cluster-1 my-nginx 1/1 1 1 39d default cluster-1 nginx-dev 1/1 1 1 14d default cluster-1 openldap 1/1 1 1 40d default cluster-1 phpldapadmin 1/1 1 1 40d 显示数据有删减,略多 指定集群检索 我们如果想要检索指定集群的资源的话,我们可以使用 –cluster 来指定具体的集群名称 $ kubectl --cluster cluster-1 get deployments -A NAMESPACE CLUSTER NAME READY UP-TO-DATE AVAILABLE AGE kubeapps-oidc cluster-1 apach2-apache 1/1 1 1 35d kube-system cluster-1 calico-kube-controllers 1/1 1 1 63d cert-manager cluster-1 cert-manager 1/1 1 1 42d cert-manager cluster-1 cert-manager-cainjector 1/1 1 1 42d cert-manager cluster-1 cert-manager-webhook 1/1 1 1 42d kube-system cluster-1 coredns 2/2 2 2 63d default cluster-1 dao-2048-2048 1/1 1 1 20d kubernetes-dashboard cluster-1 dashboard-metrics-scraper 1/1 1 1 54d default cluster-1 dd-airflow-scheduler 0/1 1 0 53d default cluster-1 dd-airflow-web 0/1 1 0 53d 显示数据有删减,略多 除了 search.clusterpedia.io/clusters 外其余的复杂查询的支持和多集群检索相同。 如果我们要获取一个资源的详情,那么也是需要指定集群才可以。 $ kubectl --cluster cluster-1 -n kube-system get deployments coredns CLUSTER NAME READY UP-TO-DATE AVAILABLE AGE cluster-1 apach2-apache 1/1 1 1 35d 复杂检索 clusterpedia 支持以下复杂检索: 指定一个或者多个集群名称 指定一个或者多个命名空间 指定一个或者多个资源名称 指定多个字段的排序 分页功能,可以指定 size 和 offset labels 过滤 对于字段的排序,实际的效果是根据存储层来决定的,默认存储层支持根据 cluster , name , namespace , created_at , resource_version 进行正序或者倒序的排序。 检索条件的传递方式 上面实例中,演示了使用 kubectl 来进行检索,而这些复杂的检索条件通过 label 来传递的。实际上 clusterpedia 还支持直接通过 url query 的传递这些检索条件。 label key 的操作符支持 ==, =, !=, in, not in 对于 size 这个条件,实际上 kubectl 可以通过 –chunk-size 来指定,而不需要通过 label key 。 集合资源 (Collection Resource) 在 clusterpedia 还有对资源更加高级的聚合,使用 Collection Resource 可以一次性获取到一组不同类型的资源。 可以先查看一下当前 clusterpedia 支持哪些 Collection Resource 。 $ kubectl get collectionresources NAME RESOURCES workloads deployments.apps,daemonsets.apps,statefulsets.apps 通过获取 workloads 便可获取到一组 deployment, daemonset, statefulset 聚合在一起的资源 而且 Collection Resource 同样支持所有的复杂查询。 kubectl get collectionresources workloads 会默认获取所有集群下所有命名空间的相应资源。 $ kubectl get collectionresources workloads CLUSTER GROUP VERSION KIND NAMESPACE NAME AGE cluster-1 apps v1 DaemonSet kube-system vsphere-cloud-controller-manager 63d cluster-2 apps v1 Deployment kube-system calico-kube-controllers 109d cluster-2 apps v1 Deployment kube-system coredns-coredns 109d cluster-2 apps v1 Deployment dce-acm-agent dce-acm-agent 84d 在 cluster-1 中增加收集 Daemonset, 输出有删减,太多 由于 kubectl 的限制所以无法在 kubectl 来使用复杂查询,只能通过 url query 的方式来查询。 自定义 Collection Resource Collection Resource 支持哪些资源是由存储层来提供,而默认存储层未来会支持自定义组合 Collection Resource 。 05 对资源进行更复杂的操作 clusterpedia 不仅仅只是用来做资源检索,和 wiki 一样,它也应该具有对资源简单的控制能力,例如 watch, create, delete, update 等操作。 对于写操作,实际会采用双写 + 响应 warning 的方式来完成。 感兴趣的话可以在 issue 中一起讨论。 06 集群的自动发现与收集 clusterpedia 中用来表示集群的资源叫做 PediaCluster, 而不是简单的 Cluster ,最主要的原因便是 clusterpedia 设计初衷便是让 clusterpedia 可以建立在已有的多集群管理平台之上。 为了遵循初衷,第一个问题便是不能和已有的多集群平台中的资源冲突,Cluster 便是一个最通用的代表集群的资源名称。 另外为了更好的去接入到已有的多集群平台上,让已经接入的集群可以自动的完成资源收集,我们需要另外的一个集群发现机制。这个发现机制需要解决以下问题: 能够获取到访问集群的认证信息 可以配置触发 PediaCluster 生命周期的 Condition 条件 设置默认的资源收集策略,以及名称前缀等 这个功能会在 Q1 或者 Q2 中开始详细讨论实现。 07 当前进展 clusterpedia 当前处于比较早期的阶段 (v0.0.9-alpha),核心功能刚刚完成,还有很多可以优化的地方,对于这些优化点也都提了对应的 issues ,欢迎大家一起讨论 这里简单说一些进入 v0.1.0 版本前的优化点: 从具有 Server-Side Apply 特性的集群中收集到的资源会带有很臃肿的 managedFields 字段,clustersynchro manager 模块会增加相应 feature gate ,来允许用户在收集时裁减掉这个字段 同样的臃肿字段 annotations 中的 kubectl.kubernetes.io/last-applied-configuration ,也要允许裁剪这个字段 在指定集群获取资源时,如果集群处于异常状态时,应该在响应中添加 warning 来提醒用户 对 PediaCluster 的状态信息有更准确的更新 弱网环境下,资源收集的优化 更多的优化项,大家可以在 issue 中提出新的想法。 08 Roadmap 当前只是暂定的 Roadmap ,具体的排期还要看社区的需求程度 2021 Q4 在 2021 的 Q4 阶段会完成上述的优化项,并且完成对自定义资源的收集 详细化资源收集状态 自定义资源的收集 Q1 支持插件化存储层 实现集群的自动发现和收集 Q2 支持对集群资源更多的控制,例如 watch/create/update/delete 等操作 默认存储层支持自定义 Collection Resource 支持请求附带关系资源 09 使用注意 多集群网络连通性 clusterpedia 实际并不会解决多集群环境下的网络连通问题,用户可以使用 tower 等工具来连接访问子集群,也可以借助 submariner 或者 skupper 来解决跨集群网络问题。 当然您也可以加入我们的企业微信交流群和我们交流互动:
DaoCloud 公司简介:「 DaoCloud 道客」云原生领域的创新领导者,成立于 2014 年底,拥有自主知识产权的核心技术,致力于打造开放的云原生操作系统为企业数字化转型赋能。产品能力覆盖云原生应用的开发、交付、运维全生命周期,并提供公有云、私有云和混合云等多种交付方式。成立迄今,公司已在金融科技、先进制造、智能汽车、零售网点、城市大脑等多个领域深耕,标杆客户包括交通银行、浦发银行、上汽集团、东风汽车、海尔集团、屈臣氏、金拱门(麦当劳)等。目前,公司已完成了 D 轮超亿元融资,被誉为科技领域准独角兽企业。公司在北京、武汉、深圳、成都设立多家分公司及合资公司,总员工人数超过 350 人,是上海市高新技术企业、上海市"科技小巨人"企业和上海市"专精特新"企业,并入选了科创板培育企业名单。 |
| [K8s 超级补丁] KLTS 新手攻略: KLTS 现有成果、如何使用、RoadMap 规划,如何参与到 KLTS 项目贡献中来? Posted: 17 Jan 2022 10:40 PM PST
KLTS 持续维护 Kubernetes 早期发行的版本,定期修复常见的 CVE 漏洞和 bug ,可直接用于生产,完全开源,包含了完整的 Kubernetes 运行时环境及其依赖。KLTS 提供的维护版本,可以说是 Kubernetes 早期发行的版本的超级补丁。 如何使用?如何可持续的发展和培育 KLTS ?接下来就为大家详细介绍一下,KLTS 现有成果、如何使用、RoadMap 规划,以及如何参与到 KLTS 项目贡献中来。 01 KLTS 现有成果 KLTS 已经正式上线一段时间了,目前 KLTS 的维护者包括 Kubernetes 社区 Member 、Reviewer 、Approver 各个层级的成员,涉及到社区中多个 SIG 。与之对应的,他们也是 KLTS 的 Member 、Reviewer 、Maintainer 。 目前,在 KLTS 成员的辛勤维护下,目前 KLTS 发布了 Its.1 的版本内容,支持 Kubernetes 1.10 ~ 1.19 的 10 个版本。修复了一些中高优先级的 CVE 和严重问题,还提供了国内镜像加速,支持 CentOS 和 Ubuntu 操作系统,定制了一键安装脚本,目前共计 76 个 PRs 。 如下图所示,V1.16.15 是 Kubernetes 的社区发行版本号,而 lts.0 是 KLTS 提供的补丁版本号。
一键安装即可尽享 KLTS 维护版本 为方便广大开发者进入社区后,更便捷安装和使用版本内容,KLTS 提供了以下脚本,可以自动完成安装流程,一键到位,方便快捷。 wget https://github.com/klts-io/klts/raw/main/install.sh chmod +x install.sh ./install.sh Usage: ./install.sh [OPTIONS] -h, --help : Display this help and exit --kubernetes-container-registry=ghcr.io/klts-io/kubernetes-lts : Kubernetes container registry --kubernetes-version=1.18.20-lts.1 : Kubernetes version to install --containerd-version=1.3.10-lts.0 : Containerd version to install --runc-version=1.0.2-lts.0 : Runc version to install --kubernetes-rpm-source=https://github.com/klts-io/kubernetes-lts/raw/rpm-v1.18.20-lts.0 : Kubernetes RPM source --containerd-rpm-source=https://github.com/klts-io/containerd-lts/raw/rpm-v1.3.10-lts.0 : Containerd RPM source --runc-rpm-source=https://github.com/klts-io/runc-lts/raw/rpm-v1.0.2-lts.0 : Runc RPM source --others-rpm-source=https://github.com/klts-io/others/raw/rpm : Other RPM source --kubernetes-deb-source=https://github.com/klts-io/kubernetes-lts/raw/deb-v1.18.20-lts.0 : Kubernetes DEB source --containerd-deb-source=https://github.com/klts-io/containerd-lts/raw/deb-v1.3.10-lts.0 : Containerd DEB source --runc-deb-source=https://github.com/klts-io/runc-lts/raw/deb-v1.0.2-lts.0 : Runc DEB source --others-deb-source=https://github.com/klts-io/others/raw/deb : Other DEB source --focus=enable-iptables-discover-bridged-traffic,disable-swap,disable-selinux,setup-source,install-kubernetes,install-containerd,install-runc,install-crictl,install-cniplugins,setup-crictl-config,setup-containerd-cni-config,setup-kubelet-config,setup-containerd-config,daemon-reload,start-containerd,status-containerd,enable-containerd,start-kubelet,status-kubelet,enable-kubelet,images-pull,control-plane-init,status-nodes,show-join-command : Focus on specific step --skip='' : Skip on specific step 此外,对于想要了解安装细节和准备工作流程的伙伴,我们准备了下列比较详细的安装介绍。 2.1 准备工作
2.2 确保每个节点上 MAC 地址和 product_uuid 的唯一性 使用命令 ip link 或 ifconfig -a 来获取网络接口的 MAC 地址 使用 sudo cat /sys/class/dmi/id/product_uuid 命令来校验 product_uuid 一般来讲,硬件设备拥有唯一的地址,但是有些虚拟机的地址可能会重复。Kubernetes 使用 MAC 地址和 product_uuid 来确定集群中的唯一节点。如果这些值在每个节点上不唯一,可能会导致安装失败 。 安装失败: https://github.com/kubernetes/kubeadm/issues/31 2.3 检查网络适配器 如果您有一个以上的网络适配器,同时您的 Kubernetes 组件通过默认路由不可达,我们建议您预先添加 IP 路由规则,这样 Kubernetes 集群就可以通过对应的适配器完成连接。 2.4 允许 iptables 检查桥接流量 确保 br_netfilter 模块被加载。这一操作可以通过运行 lsmod | grep br_netfilter 来完成。若要显式加载该模块,可执行命令 sudo modprobe br_netfilter 。 为了让您的 Linux 节点上的 iptables 能够正确地查看桥接流量,您需要确保在 sysctl 配置中将 net.bridge.bridge-nf-call-iptables 设置为 1 。例如: cat <<EOF | sudo tee /etc/modules-load.d/k8s.conf br_netfilter EOF cat <<EOF | sudo tee /etc/sysctl.d/k8s.conf net.bridge.bridge-nf-call-ip6tables = 1 net.bridge.bridge-nf-call-iptables = 1 EOF sudo sysctl --system 更多细节请查阅网络插件需求页面。 网络插件需求: https://kubernetes.io/zh/docs/concepts/extend-kubernetes/compute-storage-net/network-plugins/#network-plugin-requirements 2.5 检查所需端口 控制平面节点 工作节点
以上是 NodePort 服务的默认端口范围。 NodePort 服务: https://kubernetes.io/zh/docs/concepts/services-networking/service/ 使用 * 标记的任意端口号都可以被覆盖,所以您需要保证定制的端口是开放的。 虽然控制平面节点已经包含了 etcd 的端口,您也可以使用自定义的外部 etcd 集群,或指定自定义端口。 您使用的 Pod 网络插件 (见下) 也可能需要某些特定端口开启。由于各个 Pod 网络插件都有所不同,请参阅相应文档中的端口要求。 下面的表格列举了一些容器运行时及其对应的套接字路径:
如果同时检测到 Docker 和 Containerd ,则优先选择 Docker 。这是必然的,即使您仅安装了 Docker ,因为 Docker 18.09 附带了 Containerd ,所以两者都是可以检测到的。如果检测到其他两个或多个运行时,则 kubeadm 输出错误信息并退出。 kubelet 通过内置的 dockershim CRI 实现与 Docker 集成。 其它操作系统 默认情况下,kubeadm 使用 docker 作为容器运行时。kubelet 通过内置的 dockershim CRI 实现与 Docker 集成。 Docker 基于 Red Hat 的发行版 执行以下命令安装基于 Red Hat 发行版的 Docker: yum install docker 基于 Debian 的发行版 执行以下命令安装基于 Debian 发行版的 Docker: apt-get install docker.io Containerd Containerd 官方默认只提供 amd64 架构的下载包,如果您采用的是其他基础架构,可以从 Docker 官方仓库安装 containerd.io 软件包。在安装 Docker 引擎中找到为各自的 Linux 发行版设置 Docker 存储库和安装 containerd.io 软件包的有关说明。 也可以使用以下源代码构建: VERSION=1.5.4 tar xvf containerd-${VERSION}-linux-amd64.tar.gz -C /usr/local/ mkdir /etc/containerd/ && containerd config default > /etc/containerd/config.toml wget -c -O /etc/systemd/system/containerd.service https://raw.githubusercontent.com/containerd/containerd/main/containerd.service systemctl start containerd && systemctl enable containerd 参阅容器运行时以了解更多信息。 容器运行时: https://kubernetes.io/zh/docs/setup/production-environment/container-runtimes/ 03 KLTS 未来可期 目前 KLTS 发布的一个版本中,已经包含了比较重要的 kernel memory 泄漏问题的规避方案和几个高危漏洞的修复。为了方便用户使用,一键安装脚本已经可以支持最常用的 Centos 和 Ubuntu ,另外就是国内镜像加速做了配置。
KLTS 的路线图制定主要针对目前项目的完整性、易用性和信创场景的覆盖,此外还会结合各种不同的升级的需求,包括跨版本平滑升级等。 完整性方面,我们计划加入 containerd 和 runc 的 LTS 项目,这是因为 containerd 的版本和 kuberentes 版本也有兼容性问题,比如 containerd 1.4 版本需要 kuberentes 版本 1.19+。具体可以参考 https://github.com/klts-io/containerd-lts 的项目介绍,会有这方面的介绍。 易用性层面,我们客户有很多是离线环境,因此离线环境安装升级是急需要解决的问题。 信创层面,随着国内信创云的不断发展,这个方向的需求也是越来越多,未来我们也会逐步完成对各类信创场景的支持。 此外,KLTS 也会根据新用户的需求,更新和完善我们的路线图。 快来参与贡献 KLTS 的明天就在你手中 加入社区的伙伴,在首页点击项目 (project) 的一栏,页面底部任务看板可以查看现有的任务内容。通过参与 PR Review/问题回复 /文档,维护 CI 健康,使用新版本并给出反馈等,参与社区贡献。
此外,KLTS 还设有双周会议,通常会涉及功能、问题的讨论。如:上次周会的 Action Item 进展追踪,是否有新的发布和 Pending 事项,新增 CVE 和 Issue 讨论,以及其他议题。有任何想法、需求、试用反馈,都可以积极在 github 、slack 周会上,提问和提出建议。会议时间是周三下午 2 点,相关讨论的议题会提前添加到周会链接。 周会链接: https://meeting.tencent.com/dm/PkJXF9cytpxe 合抱之木生于毫末,KLTS 方兴未艾,期待秉持自由软件精神、怀揣浪漫主义思想的广大开发者们,加入 KLTS 开源社区,一起贡献,共同培育,结出硕果。 加入 KLTS 社区 https://github.com/klts-io/ 加入 KLTS Slack 聊天频道 https://join.slack.com/t/klts/shared_invite/zt-za36806q-6PWB_yRRY9rP78orYVonig 当然您也可以加入我们的企业微信交流群和我们交流互动:
DaoCloud 公司简介:「 DaoCloud 道客」云原生领域的创新领导者,成立于 2014 年底,拥有自主知识产权的核心技术,致力于打造开放的云原生操作系统为企业数字化转型赋能。产品能力覆盖云原生应用的开发、交付、运维全生命周期,并提供公有云、私有云和混合云等多种交付方式。成立迄今,公司已在金融科技、先进制造、智能汽车、零售网点、城市大脑等多个领域深耕,标杆客户包括交通银行、浦发银行、上汽集团、东风汽车、海尔集团、屈臣氏、金拱门(麦当劳)等。目前,公司已完成了 D 轮超亿元融资,被誉为科技领域准独角兽企业。公司在北京、武汉、深圳、成都设立多家分公司及合资公司,总员工人数超过 350 人,是上海市高新技术企业、上海市"科技小巨人"企业和上海市"专精特新"企业,并入选了科创板培育企业名单。 |
| Posted: 17 Jan 2022 10:09 PM PST 我有一个组件,默认在 mounted 的时候会在填完数据后计算一下样式,然后做相应的调整。 但是,别人在用的时候,发现,如果他的 parent element 隐藏了,计算的时候获取的 element 的长宽就是 0 ,也就没用了。 有没有办法在自己这个组件内解决这个问题? |
| Posted: 17 Jan 2022 09:18 PM PST 背景很久就一直想讲这个系列,那就是 内容目前发布的是多线程原理,主要是使用现实例子,视频讲解应该是非常的通俗易懂了,使用送快递的例子进行类比,通俗讲解了线程池的原理,并且举例讲解公式推导的过程,小学生都可以推导出来的公式,非常的简单明了,所以叫做《小学篇》。 看完一遍之后,你应该不会忘记这个最大线程数的计算公式了,因为不需要记住了,随时随地就可以推导出来。 还有各种参数设置的场景也讲解了一遍,基本面试遇到后,再也不会被难到了。建议 3 年以下小伙伴都看看,会的就加深记忆,不会的就可以学习以下。 视频地址: https://www.bilibili.com/video/BV1PL411w7oQ/ 也希望大家帮我看看,是否有讲解不到位的地方,我回头再改改修正。 接下来后面会继续创作讲解 NIO 服务,还有 Nio 编程,响应式编程,主要是偏 java 方法的技术。 end |
| Posted: 17 Jan 2022 07:19 PM PST 最近有个校园需求,需要搞一个 p2p 下载,不知道有没有大佬做过类似此经验的项目 |
| Posted: 17 Jan 2022 06:09 PM PST 我的项目的 Jest 需要用到两个 preset ,'ts-jest'和'@shelf/jest-dynamodb' 请问如何合并呢? 也有可能这本身是个伪命题,那么正确的做法应该是什么呢? |
| Posted: 17 Jan 2022 04:07 PM PST 印尼盾 最小单位 |


 DaoCloud 道客云原生开源项目 Clusterpedia ,全称 The Encyclopedia of Kubernetes clusters ,源码查看地址:
DaoCloud 道客云原生开源项目 Clusterpedia ,全称 The Encyclopedia of Kubernetes clusters ,源码查看地址: 

 使用微信或企业微信扫码加入
使用微信或企业微信扫码加入![[ K8s 超级补丁] KLTS 新手攻略:KLTS 现有成果、如何使用、RoadMap 规划,如何参与到 KLTS 项目贡献中来?](https://blog.daocloud.io/wp-content/uploads/KLTS-guide1.jpeg) 欢迎来到 KLTS 新手攻略,相信通过上期《 DaoCloud 道客云原生开源项目 KLTS ,全称为 Kubernetes Long Term Support ,为 Kubernetes 早期版本提供长期免费的维护支持》,大家对 KLTS 开源项目都有了一定的了解。
欢迎来到 KLTS 新手攻略,相信通过上期《 DaoCloud 道客云原生开源项目 KLTS ,全称为 Kubernetes Long Term Support ,为 Kubernetes 早期版本提供长期免费的维护支持》,大家对 KLTS 开源项目都有了一定的了解。![[ K8s 超级补丁] KLTS 新手攻略:KLTS 现有成果、如何使用、RoadMap 规划,如何参与到 KLTS 项目贡献中来?](https://blog.daocloud.io/wp-content/uploads/KLTS-guide3.jpeg)
![[ K8s 超级补丁] KLTS 新手攻略:KLTS 现有成果、如何使用、RoadMap 规划,如何参与到 KLTS 项目贡献中来?](https://blog.daocloud.io/wp-content/uploads/KLTS-guide4.jpeg)
![[ K8s 超级补丁] KLTS 新手攻略:KLTS 现有成果、如何使用、RoadMap 规划,如何参与到 KLTS 项目贡献中来?](https://blog.daocloud.io/wp-content/uploads/KLTS-guide5.png)
![[ K8s 超级补丁] KLTS 新手攻略:KLTS 现有成果、如何使用、RoadMap 规划,如何参与到 KLTS 项目贡献中来?](https://blog.daocloud.io/wp-content/uploads/KLTS-guide6.png)
![[ K8s 超级补丁] KLTS 新手攻略:KLTS 现有成果、如何使用、RoadMap 规划,如何参与到 KLTS 项目贡献中来?](https://blog.daocloud.io/wp-content/uploads/KLTS-guide7.png)
![[ K8s 超级补丁] KLTS 新手攻略:KLTS 现有成果、如何使用、RoadMap 规划,如何参与到 KLTS 项目贡献中来?](https://blog.daocloud.io/wp-content/uploads/KLTS-guide8.png)

| You are subscribed to email updates from V2EX - 技术. To stop receiving these emails, you may unsubscribe now. | Email delivery powered by Google |
| Google, 1600 Amphitheatre Parkway, Mountain View, CA 94043, United States | |
No comments:
Post a Comment