V2EX - 技术 |
- [游戏提问] 射击游戏中,子弹轰炸到地面,轰炸造成地面形成一个坑,这个效果怎么实现?
- 你们的项目启动时间是几秒?
- 面对公司屎山,我内心毫无波澜,因为准备跑路了
- 求连体验证码识别方案
- Rocky Linux 8.4 正式发布了
- 长时间敲代码,是浅色背景好还是深色背景好?
- 一个 React re-render 导致 html5 视频无法播放的问题
- 在线蹲一个正则表达式,求大佬帮助!
- list<map>合并问题,面试题
- 群晖用哪种硬盘格式比较好呢?
- 请教一个 nginx 请求方面的问题
- 如何以最快速度加载 H5 页面,考虑网络不佳的情况?
- 求助,神奇的 css,为何 overflow 了也没有左右滚动条?
- 亚马逊群晖 DS220+ 1591 元值得轻度用户入手吗?
- 这段代码有办法更优雅一点吗?
- 账号被盗恶意登录,现在密码改成了 100 位强密码并启用了双重认证,这下安全了吧?
- 各位在 10 下用 edge 浏览器的时候 怎样才能只登录浏览器不登录 w10 系统账户?
- 说一说我的 NAS 方案
- 分片存储-细碎设计系列
- react-dnd 有没有用得比较好的兄弟,请教一下?
- 分享一个 App 安装来源追踪工具
- 引用 tools.jar 下的类, 编译不过?
- 求教, docker 安装 redis cluster 后, 客户端/redis-cli -c 跳转啥的访问到的是 docker 内部的 ip. 连接失败.
- 安卓 recycleview
- 关于 PHP 的 yield 的一个奇怪的问题
- 请问,这种情况下返回类型声明有必要吗?
- 格式化磁盘失败(35)这个是什么问题= =
- 如何在一段时间内逐渐降低 Windows 的音量?
- 萌新请教一个 ES 字符数组过滤问题
- CloudQuery 的数据安全技术运用
- PDF 去水印
- VLOOK 10.5 发布!表格自动排版特性又上新了~好用实用的 Markdown 主题包与插件
- 一个头疼的问题
- 求 V 友推荐个 Hugo 主题~
- docker 运行 redis, NFS 挂载目录权限不足的问题
| [游戏提问] 射击游戏中,子弹轰炸到地面,轰炸造成地面形成一个坑,这个效果怎么实现? Posted: 22 Jun 2021 04:57 AM PDT |
| Posted: 22 Jun 2021 04:55 AM PDT 现在手头负责的单体项目是 15-20 秒左右, 有点影响自己的写代码节奏。。加一些启动参数能达到 10-12 秒,感觉变化不大,如果能在 5 秒内启动该多好。 |
| Posted: 22 Jun 2021 04:41 AM PDT 从入职第一天起,就发现要面对屎山,但好在 leader 搞这个项目三四年了,感觉还行,每次遇到问题都问他 结果他前阵子离职了。。。。。 最近很艰难,遇到一个不大的问题,我们组内另一个资深工程师也搞不定了。。。。。我俩上周奋斗好几个小时,连本地 server 都 setup 不起来, 面对这陈年屎山,我其实有点不烦躁,就是很迷惘。。。。。 |
| Posted: 22 Jun 2021 04:38 AM PDT 比如 aws 的验证码,或者国信证券网上营业厅的验证码。 https://trade2.guosen.com.cn/gxwt/pc/getRandom?rc=0.7285685439680818 cv2 先 2 值化,去干扰线,都没问题,但连体字符搞不定,求切割算法或其他方案。 |
| Posted: 22 Jun 2021 04:16 AM PDT 你好 Rocky,再见 CentOS ! 正式版比 RC1 略微小了一丁点。删掉了几个 redhat 开头的 rpm 。准备玩玩看了。 https://ww3.sinaimg.cn/bmiddle/8307fa20ly1grqrz7vykvj210j0kz412.jpg https://ww3.sinaimg.cn/bmiddle/8307fa20ly1grqrz7hmpnj20te0l4agu.jpg https://photo.weibo.com/2198338080/wbphotos/large/mid/4650816357270179/pid/8307fa20ly1grqrz7vykvj210j0kz412?Refer=weibofeedv5 https://photo.weibo.com/2198338080/wbphotos/large/mid/4650816357270179/pid/8307fa20ly1grqrz7hmpnj20te0l4agu?Refer=weibofeedv5 我在 Parallels Desktop 里安装的时候踩了个小坑,供参考: https://cumt.org/blog/769 |
| Posted: 22 Jun 2021 04:09 AM PDT 如题,大家在 ide 里面是深色背景还是浅色的呢? 个人是浅色背景,常用 idea,发现深色背景下的字体对比度不如浅色背景,看久了容易类。老哥们有没有实际的数据说明哪个更好地呀 |
| 一个 React re-render 导致 html5 视频无法播放的问题 Posted: 22 Jun 2021 03:59 AM PDT 一个很简单的 App,加载本地视频,在视频播放的同时,在页面上显示当前视频的时间。但是载入视频后,点击播放按钮,视频无法播放,看起来像是被重绘了,是因为 |
| Posted: 22 Jun 2021 03:39 AM PDT 限制输入字符串规则: 1.仅支持输入中英文 数字 连字符- 空格字符 2.且不能全为空格字符 |
| Posted: 22 Jun 2021 03:36 AM PDT 今天面试,问了个题没答上来。。。 题目: 有 listA<map>例如[{"a1":""},{"a2":""},{"a3":""}...],数据量 10W 条 和 listB<map>例如[{"a1":"aaaa"},{"a3":"ssss"},{"a4":"dddd"}...],数据量 15W 条 listA 中 map 的 key 和 listB 中 map 的 key 有些相同,现需要把 listA 里面的和 listB 里面的 key 相同的合并,保留 listB 里面非空的 map,例如合并后为[{"a1":"aaaa"},{"a2":""},{"a3":"ssss"},{"a4":"dddd"}...] 数据量比较大,不让用双层循环。 这个怎么做啊。。。没思路 |
| Posted: 22 Jun 2021 03:35 AM PDT EXT4 ? BTRFS ?其他? Raid 在磁盘出现故障时,恢复数据的几率大吗? 比如 2 块盘,坏了 1 块,会不会出现一定几率无法恢复 是 1 台 nas 开启 raid 好呢?还是 2 台 nas 备份好呢 |
| Posted: 22 Jun 2021 03:28 AM PDT 我用 gunicorn+django 部署了一个项目。前端页面调接口 nginx 提示 error: nginx 配置如下: 这两天 baidu 、google 都还没有找到问题。有一种说法是数据的问题。 |
| Posted: 22 Jun 2021 03:26 AM PDT 如题,公司在做一个类似收钱吧的产品 需要用户扫一个二维码,加载微信公众号下的付款页面 页面内容是一个简单的数字键盘,用于输入付款的金额 这个过程有一个微信授权的跳转,大概 200ms 左右 服务器页面的响应大概 400ms 左右 这是正常网络的情况,但是会有弱网络的情况,比如小县城的菜市场 目前是单台服务器, 加载的 js 放了 cdn,然后还有个商家上传的 logo,压缩过 老板的问题是,为什么别人(收钱吧)在(菜市场)打开很快,而我们的很慢? 求教各位大佬,还有什么办法可以加快页面加载速度 ? 阿里云的 SLB 负载均衡+高可用的服务,感觉是为了高并发和弹性扩容设计的,用在提高加载速度上效果是否明显? |
| 求助,神奇的 css,为何 overflow 了也没有左右滚动条? Posted: 22 Jun 2021 03:08 AM PDT 设置父 div 的 overflow 为 scroll,如果它的子 div 的 left 设置为 100(从右侧 overflow),那么父 div 就有左右滚动条;如果 left 设置为-100(从左侧 overflow)就没有滚动条了。 这是为什么呢?难道从左侧 overflow 和从右侧 overflow 还有区别吗?(测试了 chrome 和 firefox 都是这样的) 没有左右滚动条: 有左右滚动条(与上面的唯一的区别是 left 由-100px 改为了 100px): |
| Posted: 22 Jun 2021 03:03 AM PDT 来源小众软件,手机不方便贴图,麻烦大家自行查看 |
| Posted: 22 Jun 2021 02:44 AM PDT |
| 账号被盗恶意登录,现在密码改成了 100 位强密码并启用了双重认证,这下安全了吧? Posted: 22 Jun 2021 02:30 AM PDT |
| 各位在 10 下用 edge 浏览器的时候 怎样才能只登录浏览器不登录 w10 系统账户? Posted: 22 Jun 2021 01:41 AM PDT 如题。因为在公司使用。所以只想登录 edge 不登录 win10 系统。但是只要我登录了 edge 他就会默认登录 win10.百度了一下没找到方法。。不知道是不是我姿势不对 |
| Posted: 22 Jun 2021 01:39 AM PDT 最近看待很多 V 站老哥求 NAS 方案,就来说说我的树莓派+移动硬盘方案吧 价格
软件方案
速度通过 frp 中转速度大概 500-900k(因为我的中转服务器最大带宽只有 3M),没有试过 frp 的 xtcp 的 p2p 打洞方案 |
| Posted: 22 Jun 2021 01:37 AM PDT 摘要
前言大量的数据存储,常见的水平分片算法:
Range基于 Unique Key 按照范围分片。切分的维度:
优点:
不足:
Hash基于 Unique Key 取模,均匀分片。 优点:
不足:
例子Passport Service 几乎是每一个公司必备的基础服务。 之前团队中负责设计 passport 服务时有过 user 存储的思考和设计,简单说说。 Passport Service 是一个非常常见的基础服务,主要提供账号通行证相关能力, 在使用场景中比如登录、注册、登出、登录态校验、更新等,其核心存储是一张 user 表: 比如:
ok,这张表如何设计呢? 单表实现不合理,结合业务场景,水平分片是必须要有的。 账号量级大,请求量高,需要保证高可用和高一致性。UID 作为 Unique Key,基于 UID 是高频查询,那么就基于 UID 水平分表。
问题基于 UID 分片,那么问题来了~
方案issue1: 用 UID 分片,如何高效实现查询?方案一:索引法 思路:UID 可以定位分片,user_name 无法直接定位,那么通过 user_name 定位 UID,进而定位分片。 方案:
问题:多一次 DB 查询,性能相对降低。 方案二: 持久化缓存映射 思路:接受不了多一次 DB 查询,那就将映射关系持久化到缓存中。 方案:
问题:
方案三:基于 username 生成 uid 思路:不想单独存储映射关系,直接通过 username 生成 uid 方案:这种通过字符串生成 ID 的 Hash 函数很多,f(username) = uid 问题:
方案四: 基因法 思路: 从 username 中提取基因,加入到 uid 生成规则中。 方案: 这里需要引入分布式全局唯一 ID 生成能力,该基因法依赖分布式 ID,后续会输出《分布式发号器》的文字,先简单普及下分布式 ID 生成的一种常见算法, SnowFlake 算法生成 id 的结果是一个 64bit 大小的整数,它的结构如下图:
所谓基因算法就是提取 username 的分片基因,合并到全局唯一的 ID 上,生成一个全新的 UID 。如下图:
直接上 Demo 源码吧:
基础配置: 这是个 Demo, 基因 ID 实例: 样本基因提取:
基于雪花算法生成完整 ID:
不足: username 不能更新 issue2: 如何多分片高效检索汇总?思路 1:前后台 思路 2:接受数据 思路 3:后台存储组件可以基于数据时效性选择:
之前基于 Elasticsearch 做过前后台数据隔离设计,大概设计如下:
基于阿里开源的 下游可以通过 后台服务基于 Elasticsearch 的 总结Issue1: 用 UID 分片,如何高效实现查询?
Issue2:如何多分片高效检索汇总?
思考
tips:学习不要光靠脑袋记,沉淀下来记到本子上才是自己的。
收工
|
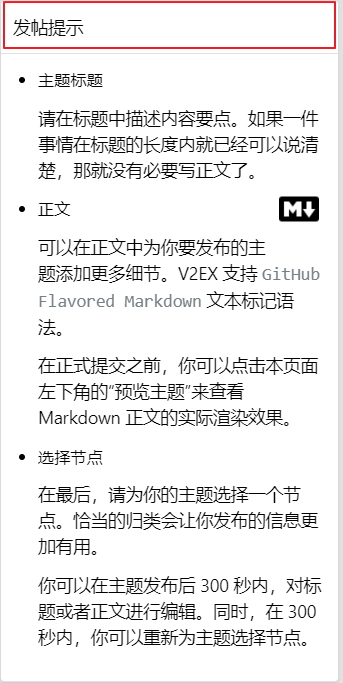
| Posted: 22 Jun 2021 01:28 AM PDT 最近需要实现一个"可以在页面中"拖动的 Panel,我们拿 V2EX 右侧的这个"发帖提示"举例。
如图,我已经实现了一个 panel,有 header "发帖提示",有内容,就是下面的"主题标题,正文"等等。
所以,不是很了解 react-dnd 。特意来问问。react-dnd 怎么实现我的需求,或者有没有其它组件能够做到? p.s. 我找到一个使用起来很简单的组件,react-rnd,这个实现 1 的需求 很容易(试过了),但是,貌似 2 做不到。react-rnd 包含的组件,都是可拖动的。我只想鼠标移动到 header/上面一部分的时候能够拖动就好。 https://github.com/bokuweb/react-rnd |
| Posted: 22 Jun 2021 01:27 AM PDT 作为 APP 的开发者和运营商,都会研究分析渠道的效果。很多 App 在推广的时候,需要分成 N 个渠道来引流,将 H5 落地页分享出去后,我们希望通过一定的技术手段,知道激活或注册用户是从哪个渠道来的。Android 上可以通过打渠道包的形式,将渠道 ID 硬编码到包里做到这一点,但 iOS 上这样做不太现实。 有一个常见的需求就是:在推广渠道相当多的情况下,通过分发 H5 落地页给不同渠道,从每个渠道来的用户,没有任何感知的情况下,后台可以统计到他激活及注册时的渠道 ID (甚至其他任意参数)。 第三方 SDK openinstall 能够解决这个问题 openinstall 能提供哪些服务呢? 1、携带参数安装 为 App 的每一次安装自定义不同的初始化参数,在下载落地页自定义参数,匹配携带参数来区分不同渠道带来的激活用户。通过分发渠道链接给不同渠道,让每个渠道来的用户,没有任何感知的情况下,后台可以统计到他激活及注册时的渠道 ID (甚至其他任意参数)。 2、App 渠道统计
3、免费服务:快速安装与一键拉起 快速安装:社交分享一键安装,从此告别"右上角打开浏览器",大幅提升安装概率,助力用户增长。在微信、QQ、新浪微博、钉钉、支付宝等社交平台中直接快速下载安装 apk (兼容 iOS )告别'右上角打开浏览器'操作。 一键拉起:实现 web 页面到 App 间的无缝跳转,解决拉新、拉活、留存、转化等问题,一键拉起 App 到指定场景页面,给用户更优更快体验。从外部分享链接打开的页面,可一键唤醒 App,直达指定页面,如一键加入游戏房间、视频播放页、App 活动详情页等;首次安装 App 后也可还原到对应场景页。 部分使用场景:
传送门: https://www.openinstall.io/ |
| Posted: 22 Jun 2021 12:54 AM PDT 代码 使用 javac 来编译, 报如下错误 程序包 com.sun.tools.javac.util 不存在 使用的是 jdk1.8 有铁子知道原因么? |
| 求教, docker 安装 redis cluster 后, 客户端/redis-cli -c 跳转啥的访问到的是 docker 内部的 ip. 连接失败. Posted: 22 Jun 2021 12:35 AM PDT 创建了一个 bridge network, 解决了容器之间网络访问问题, 但客户端连接 redis cluster 后, 获取到的节点的 ip 是 docker 分配给容器的 ip. 这肯定访问不了. 有大侠知道解决办法吗.. 头都秃噜皮了. |
| Posted: 21 Jun 2021 11:48 PM PDT recycleview FlexboxLayoutManager 可以通过 setMaxLine 设置只显示多少行 ,但是最后的一行的元素宽度会被压缩 有办法不让压缩吗?能展示多少个就多少个 |
| Posted: 21 Jun 2021 10:30 PM PDT 最近在学习 PHP yield 相关的知识,遇到了一个搞不懂的问题,直接上代码: 上面这段代码会输出: 但是,只要在代码里加多一句 然后输出就会变成(相比原输出,少了一行"Generator return:1"): 问题:在这个例子里,为什么加了一句 send 后,输出内容就改变了? |
| Posted: 21 Jun 2021 09:40 PM PDT 这里的 |
| Posted: 21 Jun 2021 09:11 PM PDT 主板是华擎 j3455,我把 3617 引导装在了 128 的 ssd 上,插上硬盘后安装系统就报 35 错误,无法格式化 |
| Posted: 21 Jun 2021 09:00 PM PDT 有些用户在晚上放音乐时会有这个需求 Linux 下应该可以用 Bash 非常方便地实现 Foobar2000 的一些插件或许也可以实现,但是解决方案和具体软件绑定不太好 请问有什么现成的工具可以实现这一需求吗? |
| Posted: 21 Jun 2021 07:44 PM PDT 索引中某个字段的值是字符数组,例如"test": ["test1", "test2"],查询的时候怎么过滤数组中某个值,只知道 long 类型可以直接过滤,但是这种复合类型似乎不行,mapping 是 "mappings" : { "properties" : { "test" : { "type" : "text", "fields" : { "keyword" : { "type" : "keyword", "ignore_above" : 256 } } } } } |
| Posted: 21 Jun 2021 07:42 PM PDT 随着电力行业信息化的不断发展,其内部信息系统越来越复杂,数据库作为信息系统的核心和基础,承载着越来越多的关键业务信息。同时,国家对信息安全方面的重视程度也逐步加深:2014 年 7 月 2 日,国家能源局发布《电力行业网络与信息安全管理办法》; 2018 年,9 月 13 日,国家能源局发布《关于加强电力行业网络安全工作的指导意见》,内容全面覆盖《网络安全法》、《电力监管条例》及相关法律法规要求,对加强关键信息基础设施安全保护、加强电力企业数据安全保护等方面提出了更高、更严的要求。 H 电力公司经过多年发展,依靠现代化经营管理能力,不断加强了信息化、自动化、系统化的特点,而基于政策指导和信息数据化进程不断加快,H 电力公司更需要对数据进行强制性、可控性保护。 一方面,H 电力公司需要通过不断挖掘数据价值以支撑自身服务质量、工作效率和发展需要;另一方面,又要保证数据在复杂场景、系统之间被安全、合理的访问和使用。 传统安全防护手段无法跨越的鸿沟根据国家能源局对数据安全的意见及 H 电力公司对数据安全的要求,H 电力公司进行了自查,发现了如下不足: 敏感数据管理不足 随着 H 电力公司信息化建设的持续推进,营销、人资、财务、资产、协同、综合等核心系统中存储着大量的业务往来、用户隐私等重要敏感数据。 H 电力公司内部电力数据传输与共享场景普遍,当前虽然有一些数据脱敏手段,但是主要采用脚本或人工脱敏的方式,脱敏规则不统一,从而导致脱敏效率低下,以及脱敏后数据质量差、数据间关联关系被破坏等一系列问题,需要通过对敏感数据进行专业的脱敏实现,"用、护"结合。 风险行为监控不足 H 电力公司信息化规模庞大、系统繁杂、人员众多,日常工作中发生越权访问、下载或篡改数据等违规操作行为难以及时发现和定位,往往对内部数据安全事件的预防和调查造成困扰。 数据库运维管控不足 H 电力公司的网络复杂、业务特殊、数据库众多,在运维专区中,使用堡垒机来对运维人员进行管理,但这种管理方式在数据安全防护上存在一定问题:运维人员不按操作规范或既定方案进行数据库运维操作、非法导出敏感数据、数据库操作行为没有细粒度的审计记录等。 H 电力公司根据目前数据安全痛点和对现状的深入分析,提出如下需求: 1.实现与现有运维管理流程深度融合,实时监控运维人员数据库操作; 2.实现与现有 SPV 集成,运维人员无需单独申请对数据库访问,保持操作习惯不变; 3.实现细粒度运维管控,控制对象可以是库,可以是表,并可以精准到列;除了传统的增删改查操作外,还可以根据访问的影响行判断是否存在数据窃取、批量删除等高危行为;管控的对象还包括用户、登录 IP 、时间、客户端工具等多种条件; 4.提供用户行为审计,方便及时发现风险隐患; 5.支持动态数据遮蔽防止敏感数据泄漏,查询数据自动显示签名,防止拍照外传。 ###没有授权进不去 未经许可拿不走 数据泄漏赖不掉 针对以上 H 电力公司面临的问题,CloudQuery 提出本次项目目标应做到"没有授权进不去,未经许可拿不走,数据泄漏赖不掉"。 根据 H 电力公司对信息安全工作的指示,加强对数据中心数据安全的防护要求,经过深入研究,整理出如下建设思路: 数据脱敏 由于 H 电力公司数据错综复杂,各业务数据流转通道各不相同,按照数据的分级分类标准,在对数据进行共享时,应针对重要数据进行脱敏降级,确保数据接收方不会对数据内容进行二次扩散。 数据库安全管控 通过引入 CloudQuery,对数据库的访问及其他操作行为进行细粒度防御、审计分析,从而全程监控、记录包括非法访问、数据库违规操作、数据批量导出或篡改在内等一系列风险行为,实现对所有数据访问行为进行审计记录,然后通过数据分析技术结合数据操作审计典型策略要求,对风险行为进行挖掘和预警,并可在安全事件发生后,做到准确、高效的溯源定责。 数据库运维与管理 在确保不影响正常开展运维工作的前提下,建立数据库运维操作的审批机制和技术措施。通过 CloudQuery 对所有涉及敏感数据的操作进行限制,强化对数据库运维操作的监管力度,及时阻断越权操作行为的发生,令运维工作实际操作与计划操作保持一致。 对数据运维操作的关键动作进行划分,将那些敏感操作梳理出来并默认禁止。当有变更需求时,通过发起运维审批流程,根据审批小组的审批意见,有序、安全的执行运维操作。 四大核心模块 解决电力行业棘手问题针对 H 电力公司的系统现状、其数据库安全管控需求及目标,CloudQuery 制定了符合 H 电力公司数据库安全管控目标的解决方案,全面发挥数据库安全管控平台在企业中的价值。 CloudQuery 作为一体化企业数据安全管控平台,是企业数据操作的入口,将组织(包含应用)、数据、安全整合到一个平台,提供一系列数据应用工具辅助应用和 IT 人员完成相关的数据处理和操作,并逐渐培养组织的数据化流程、协作机制,完善组织的数据意识。 CloudQuery 采用以服务组件为单位,面向云的分布式架构,支持高可用模式保持用户使用的连续性,针对 H 电力公司,我们主要将平台划分为四大核心模块:数据处理中心、用户管控中心、监控中心、审计中心。 数据处理中心:广泛的数据库支持,集中管控数据 CloudQuery 支持绝大多数国内外主流数据库以及中间件,目前支持 Oracle 、SQLServer 、MySQL 、PostgreSQL 、Redis 、Hbase 、达梦、RDS for MySQL 等,未来将支持更多种类的数据库及中间件数据源。覆盖 H 电力公司目前使用的主要数据库数据源。同时,CloudQuery 完美支持各数据库特性,契合操作人员日常数据操作习惯。 用一个平台对所有数据操作进行管控,包含登录登出、权限、脱敏、审计、监控、过滤、回退等。内置一系列流程库,可通过 OpenAPI 接口与现有运维管理系统进行对接,实现数据操作 /授权在数据中心内部流转。 对于 H 电力公司的数据脱敏要求,CloudQuery 采用被动脱敏方式,即不改变数据库内容,但查询得到的结果为脱敏后的数据。脱敏按照规则来处理数据,规则分为内置和动态,内置规则只要用户查询的数据中符合系统内部定义的敏感资源,就会被处理;动态规则指系统管理员或者拥有者根据业务自定义,比如订单里的门牌号等。系统支持 5 种脱敏模式设定:替换、掩码、加密、截断后加密和无效化。 脱敏还会应用在以下场景:
用户管控中心:细粒度权限管控,越权访问需审批 针对可能存在的用户越权访问、非法导出等违规行为,CloudQuery 从不同需求和不同维度进行细粒度权限控制:
审计中心:记录用户行为,风险操作可追踪 CloudQuery 审计系统可跟踪用户在平台上的所有操作,覆盖数据库、流程、权限等方面的查询和变更。审计明细包含用户、连接、库、操作对象、动作、摘要、时间、结果、IP 来源等,可按条件过滤,并支持 Excel 导出。 除了审计明细,系统还支持面向业务的审计分析,可进行多维度的分析,如 UV 、PV 、数据库类型、语句执行时长、慢查询、高危操作。 而通过应用探针或 Cloud Query 提供的审计驱动可对应用的数据操作进行审计分析。相对于面向人的操作审计,应用数据审计主要是站在数据库管理员和安全的视角,对应用的数据访问进行分析,找出违反审计规则的语句,每一个应用包含一个审计视图。主要包含:
同时应用审计会基于 SQL 模式进行数据分析,支持以下维度的分析:
数据库监控中心: CloudQuery 可以提供一个集中监控平台,连接管理员可以看到自己管纳连接的数据库负载情况,针对每一种数据源会有不同的监控指标,方便更直观的排查与定位问题。 CloudQuery 的应用价值没有授权进不去 基于细粒度的权限管控体系,CloudQuery 通过「用户-角色-权限」,在快速授权的同时精准控制每个用户的访问及操作权限,规避了 H 电力公司原先可能面临的越权访问、下载或篡改数据等违规操作行为。 未经许可拿不走 CloudQuery 以独创的「查导分离」作为数据防泄漏的最后一道防线,将导出动作单独形成一种权限类型,与查询动作分离开来。即使 H 电力公司内部人员恶意获取数据也无法将数据落地至 PC 电脑,更别提在企业内部甚至外部进行流通。 数据泄露赖不掉 CloudQuery 作为企业内部的第四道安全防护门。对平台内部众多操作进行埋点,保证 H 电力公司的用户每一个动作都可追踪、可溯源。一旦有用户执行恶意语句或误操作可以及时定位到问题用户及用户 PC IP 。同时,CloudQuery 辅助以告警模块,从不同风控视角来监测当前平台内用户的操作风险性,可以让 H 电力公司在发生数据泄漏时间后快速、精准定位到责任人,及时还原丢失数据。 从 H 电力公司的应用可见,CloudQuery 站在企业角度,根据内部数据流向提供全链路的干涉跟踪保护机制,贯穿数据登录、使用、登出整个生命周期。1:1 针对各数据源的终端,可实时对操作的 SQL 执行拦截、分析、审计、告警等操作,精确到人和应用。避免延后追溯,避免安装堡垒机客户端,也避免审计记录和录像的对比,极大的提高了审计效率和用户体验,让企业内部数据运转更加流畅、安全。 |
| Posted: 21 Jun 2021 07:42 PM PDT 看领域驱动设计时,google 搜索下载了一本 PDF,每一页都印着水印,学习本身就是枯燥的事情,在加上这洗脑水印,着实令人不爽。试了很多网站和 APP 去水印的功能 都不能去掉,就萌生了学一下 PDF 语法,自己实现 PDF 去水印 有同感的同学可以用一下我博客里的 PDF 去水印功能。 已经实现:
未实现:
|
| VLOOK 10.5 发布!表格自动排版特性又上新了~好用实用的 Markdown 主题包与插件 Posted: 21 Jun 2021 05:31 PM PDT
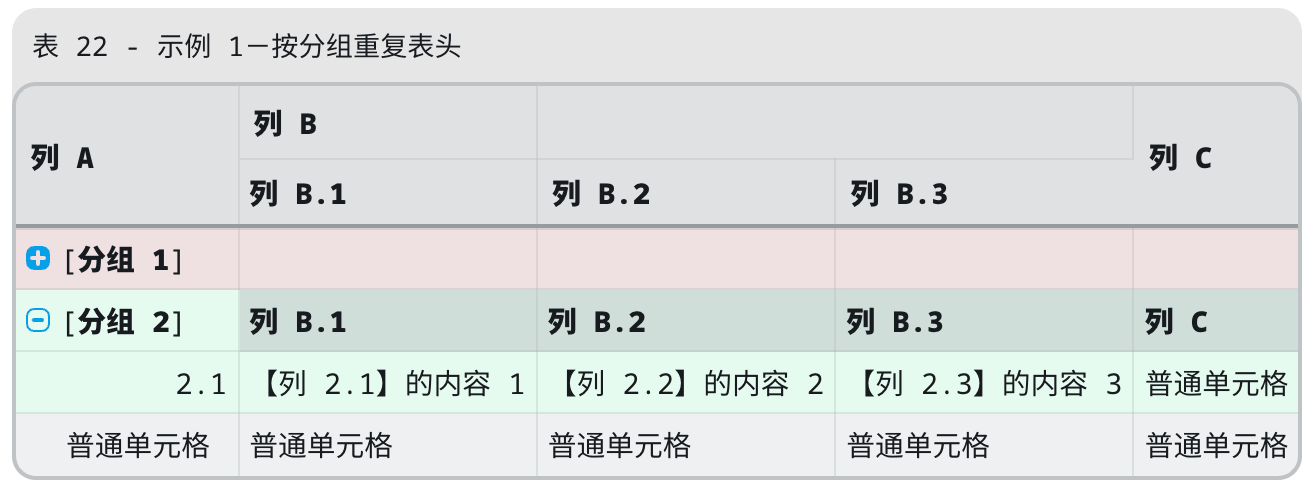
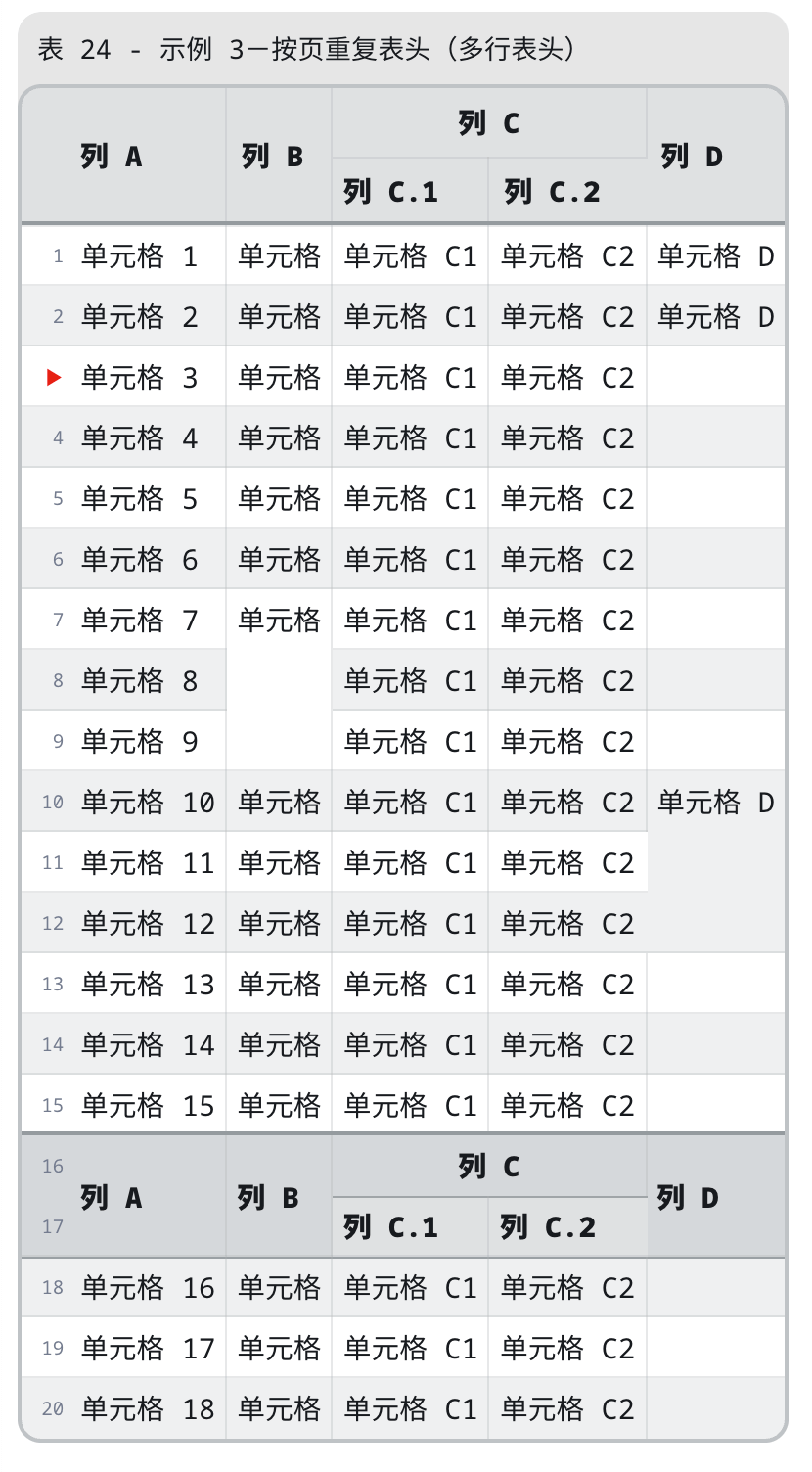
VLOOK™ 的所有特性清单,详见快速入坑 → 一键进入 Markdown 粉最喜欢 VLOOK 「表格自动化排版」特性,今天又上新了! 在 V10.5 版本中,可以实现快速设置表格列头自动重复出现了~这个对于长表格、带行分组的表格绝对是友好的助攻。
完整的更新日志如下:
项目托管于: |
| Posted: 21 Jun 2021 04:35 PM PDT 假设我们现在有 3 个环境 线上 测试 开发 Q1. 当线上出现 bug 我们该如何重现 bug ? 比如中间的数据重现 MQ,redis,数据库等 我觉得只能日志排除,因为想要弄到线上数据一模一样很难 Q2. 测试环境发现 bug 我们该如何重现 bug ?比如中间的数据重现 MQ,redis,数据库等 我觉得看项目规模,但是随着项目越来越大,也只能通过日志排除,很难去同步数据 那么我想问一下, 像大厂这些项目用户千万亿的数据级别,排查 bug 和 bug 重现是怎么实现的呢? 非常好奇。望大佬们指条明路。 有没有啥的,现成的解决方案? |
| Posted: 21 Jun 2021 01:08 PM PDT 已经有单独的博客站,所以希望是 Introduction 类型的主题。用于生成 Home Page 。 目前看上的有: |
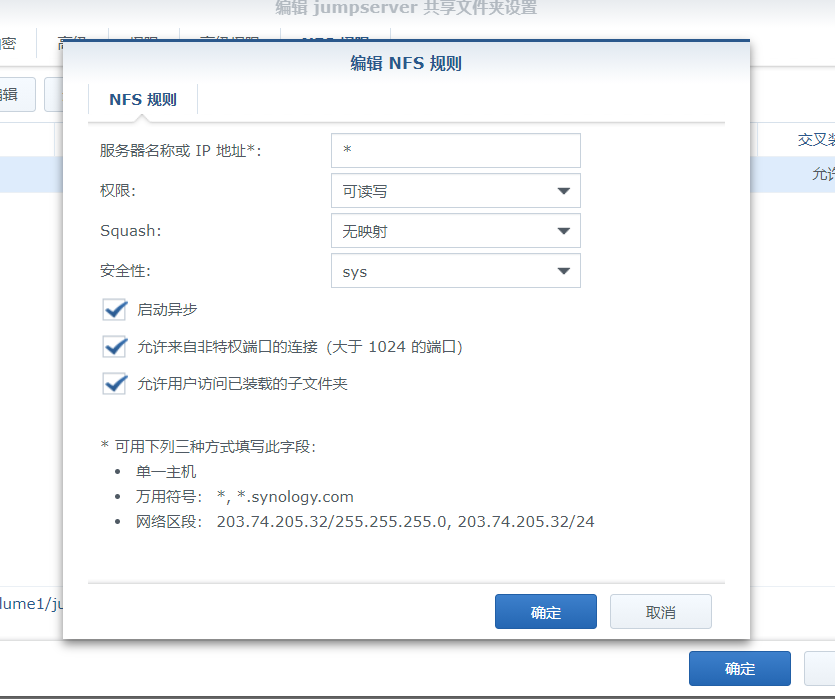
| docker 运行 redis, NFS 挂载目录权限不足的问题 Posted: 21 Jun 2021 12:22 PM PDT NFS 是用的群晖 NAS 创建的 运行 jumpserver start 的时候查看日志说是 redis 目录没权限 我加了 privileged: true 参数启动还是无效,我还特意用 docker run 跑了一下也是如此 jumpserver 配置 |
 )
)






{kind=link}
{kind=link}
| You are subscribed to email updates from V2EX - 技术. To stop receiving these emails, you may unsubscribe now. | Email delivery powered by Google |
| Google, 1600 Amphitheatre Parkway, Mountain View, CA 94043, United States | |
No comments:
Post a Comment