V2EX - 技术 |
- 不让用自己电脑开发,公司电脑不能带回去
- 迫于远程施法,寻求一款手机
- GET 方法有没办法传递 token
- 内卷时代的筛选手段:面试考算法,你怎么看?
- 大家对开源怎么看,很多开源作者被抄袭,所以开源的意义何在?
- 装个桌面版 Linux 能不能实现 IDEA 进行语言开发以及基于 docker 环境配置
- 服务器系统选择,都在说 Debian 好,到底好在哪?
- 程序员都有哪些可实操的副业
- 关于程序员如何精进细节的三个问题。
- 你们有遇到不准用自己电脑开发项目的公司?
- 请教一下,怎么样才能让 pdf, epub, mobi 这种可以在线阅读?
- github actions 突破 6 小时限制编译超大项目
- 关于 mysql 联表执行顺序问题
- 请教一个,有关 react 的 re-render 的性能小问题
- 生成器模式-代码的艺术系列(一)
- Windows-server2008 设 DNS 解析, active directory 勾选是灰色的,怎么办?
- 求助: apache 的所有网站上不去
- 有关 Python 的一个问题。
- UWP App 在外置显示器上显示异常
- Samba 在共享的时候,如何比较好的设定:可写但不允许删除目录?
- webkit 如何监听网页加载状态
- git 如何根据文件大小进行忽略,想跳过大文件。
- 一大波 Android 构建的迭代
- 请教熟悉 WinRAR 的老哥一个问题,详见下文。
- 关于在一个服务端 urlencode 编码后传递的 post 参数请求时候 在 nodejs 接收时报错
- 输出推送不到 server 酱上
- 有没有比较安全、好用的纯净版 win7/win10 gho?
- 介绍自己搭的一个 Go Web 脚手架项目
- 使用共享协议(NFS、SMB、FTP、WebDav 等)实现的 NAS 存储需要哪些软硬件支持?
- 通过点击 Sublime Text 的付费提示的确认按钮继续使用算不算破解和盗版?
- Linux kernel 4.4 模块编译 提示 module PLT section(s) missing
- 面试经典题目--公交路线
- Python 客户端方案, orm 还是 http?
| Posted: 24 Jun 2021 03:56 AM PDT 这样的公司还可以去吗,有 V 友遇到过吗 | |||||||||||||||||||||||||||||||||
| Posted: 24 Jun 2021 03:51 AM PDT 迫于雷总远程施法,手上的小米 6 承受不住,经常卡顿死机,想着也用了 4 年多,打算换台手机,预算 3500 内,轻微游戏控(第五人格,王者这些),拍照扬声这些能希望好一些,V 友们有没有推荐的 | |||||||||||||||||||||||||||||||||
| Posted: 24 Jun 2021 03:50 AM PDT 有个网站,需要校验是否有权限,判断头部的 token 参数。 但是,直接在浏览器上输入网址后,能否自动头部添加 token 呢? 是不是只有 session+cookie 的方式了。 | |||||||||||||||||||||||||||||||||
| Posted: 24 Jun 2021 03:48 AM PDT 现在面试太注重算法了,搞得大家都去疯狂地刷题、背题,以求通过面试的初筛。 这显然是内卷时代的一种筛选手段:行业涌入的人才越来越多,所以门槛就会不断提高。 但这会导致一个不好的现象:很多人以为刷够了题,背会了面经,就能搞好软件开发,实际上还差得远。 你怎么看这种风气? | |||||||||||||||||||||||||||||||||
| Posted: 24 Jun 2021 03:38 AM PDT | |||||||||||||||||||||||||||||||||
| 装个桌面版 Linux 能不能实现 IDEA 进行语言开发以及基于 docker 环境配置 Posted: 24 Jun 2021 03:36 AM PDT 找了好多资料,也没能实现我的这个想法。 1 、首先安装桌面版 Linux ( Centos/Debian/ubuntu/统信)求推荐一个系统+版本号; 2 、安装 idea 难度较低 3 、如何整合 docker 内的 mysql/maven/JDK 等给 linux 中的 idea 用。这个我不会配置,请大佬发个教程链接。 谢谢谢谢谢谢谢谢谢谢谢谢谢谢谢谢谢谢谢谢谢谢谢谢谢谢谢谢谢谢 纯属个人摸鱼胡思乱想的需求,搞不定这个想法睡不好。 还有还有,我天天摸鱼没事儿干,求推荐摸鱼思路?比如说看看 Java 架构师或者什么的。 | |||||||||||||||||||||||||||||||||
| Posted: 24 Jun 2021 03:29 AM PDT 服务器选 Debian 还是 Ubuntu,无论是知乎还是 V2EX 之前的调查,大部分都在说 Debian 好,什么稳定,占用内存小之类的,这个"稳定"到底是什么稳定,我用 Ubuntu,centos 服务器跑了多年也没啥问题,感觉"稳定"是个玄学&主观的问题,Debian 我从没用过,那么 Debian 到底好在哪?和 Ubuntu 比,Debian 是优点多还是缺点多?真的是网上吹嘘的那么神乎? | |||||||||||||||||||||||||||||||||
| Posted: 24 Jun 2021 03:29 AM PDT 迫于年龄(30)和房贷压力, 一直在想办法拓展一下自己的副业, 无奈由于自己的认知和人脉资源有限, 没有可交流的朋友一起探讨 希望有过实践经验的大佬能分享一些切实可行的副业案例(不与您构成竞争关系, 不暴漏您隐私, 不影响您收益的案例) 以示真诚, 我把自己实践过的案例分享一下, 为了避免广告嫌疑, 我已抹掉个人信息 1.闲鱼接单 一般每年 4-6 月份, 毕业季需求旺盛, 可接一些毕业设计、项目讲解的活 其他月份, 可接一些实习生或新手小白的 bug 修复、调试或业务逻辑梳理的活 目前这个我已实践 1 年 3 个月, 收益还可以, 只是比较累, 算是一种比较苦力的搬砖工 基本除了本职工作外, 大部分时间都在写代码或讲课 再加上最近闲鱼针对代写查的比较严, 已经判了 2 次违规, 第 1 次 7 天, 第 2 次 15 天, 目前我还处于禁言和下架所有商品的状态中
2.考拉代下单 由于网易考拉 APP 上很多商品的普通会员价格和黑卡价格差别很大, 黑卡的售价常年在 279 元, 对一些偶尔买东西的用户来说, 单独购买黑卡很不划算, 于是他们就会找各种平台寻求代下单, 恰好考拉的商品返佣比较高, 平均在 6%以上, 再加上有很多活动价格波动大, 可退差价 我从 2019 年便开始了代下单, 人多的时候一个月能赚到 3000(佣金+价保差价)左右, 后来由于考拉卖给了阿里,闲鱼上开始了大量封杀代下单, 无奈下只能改关键字, 流量也下降了很多,现在基本只剩以前沉淀的老客户还在下单
3.个人网站挂 adsense 刚开始的时候很有激情, 写了一些技术分享的文章, 搜索和实践了很多 SEO 优化的文章, 后来看到流量太小便失去了耐心, 现在基本处于放养状态, 从运营到现在, 已经满 2 年了, 前两天才提现 100 美元, 现在基本每天 0.3 美元, 勉强抵消服务器开支
| |||||||||||||||||||||||||||||||||
| Posted: 24 Jun 2021 02:50 AM PDT 诚心请教各位三个问题
另外奉劝跟我一样的小白,做稍微偏底层一点的东西,C 和 C++是逃不掉的,学得越熟练越好。 | |||||||||||||||||||||||||||||||||
| Posted: 24 Jun 2021 02:39 AM PDT 上家项目黄了,最近跳到上海某家做社交 App 的公司。原来开发都是用自己电脑的,昨天刚入职,领导看到我用自己电脑,直接跟我说不要用自己电脑,用公司的(公司电脑配置渣渣)。听出来意思是怕我偷他们项目。听到这话心里五味杂粮的吧!不明白为什么不是内网开发,有必要要求员工用公司电脑? | |||||||||||||||||||||||||||||||||
| 请教一下,怎么样才能让 pdf, epub, mobi 这种可以在线阅读? Posted: 24 Jun 2021 02:30 AM PDT 想着做一个内部的电子书服务器,可以让 pdf,epub,mobi 这种格式的电子书能够通过网页阅读,最好是服务器版本的,calibr 好像要客户端来看。 | |||||||||||||||||||||||||||||||||
| github actions 突破 6 小时限制编译超大项目 Posted: 24 Jun 2021 02:24 AM PDT 最近在试着编译第三方 chromium,发现 kiwi browser 有在 actions 上编译,虽然脚本没有维护已经 4 个月没有成功编译了,但还是有参考价值, 自己跟着编译了下发现,github actions 单次 6 小时完全不够用,就这一半都没编译好, 研究了下 kiwi 怎么实现的,发现是用 ccache 缓存编译结果,用 rclone 保存到他自己的服务器上, 别人访问不了他的缓存,自然无法快速编译, 于是花了好几天的时间,一点一点调整,最终实现分步编译,每一步编译完成将 ccache 缓存传到另一个 github 仓库上, 超过 5 小时没成功编译直接打断,保存当前缓存,然后每 6 小时开启一个新的 actions 继续编译, 最终全部完成缓存之后一次编译打包只要一小时多点, 之后就可以试着修改代码了,我想搞一个安卓端支持拓展同时支持谷歌的第三方 chromium, https://github.com/AoEiuV020/kiwibrowser-build/blob/main/.github/workflows/build.yml https://github.com/AoEiuV020/kiwibrowser-ccache-arm64/commits/main  | |||||||||||||||||||||||||||||||||
| Posted: 24 Jun 2021 02:24 AM PDT user 表的记录有几百万,update_time 有索引,limit 0,20 和 limit 19999,20 的效果也是一样上面的语句很明显从索引找出符合的条件然后回表在临时表排序 不太明白 mysql 为什么不根据索引排序后的 row_id 回表进行查询,本身索引也是有序的,过滤 20 行回表不就可以了吗 难道回表的随机查询导致分析成本过高, 改写后 执行时间大大缩减了,没有临时表和文件排序。 | |||||||||||||||||||||||||||||||||
| 请教一个,有关 react 的 re-render 的性能小问题 Posted: 24 Jun 2021 01:22 AM PDT 有关 react 的两个小问题。 我忘记在哪里看到的(年纪大了,记性不太好),在以前 class component 的时代,不推荐 button2 的写法,就是把函数体直接赋值给 button's onClick 。因为这样会使得每次 button2 都有变化,会 re-render 。在大的项目 /组件多的情况下,会有性能问题。一般是建议在 class 里面定义一个函数,然后赋值给 button's click. 现在来到 function component 时代,当 button 被点击的时候,会触发 function app 被重新调用,handleClick 也会被重新生成,这个时候,button1 和 button2 的用法,还有区别么?不过,当 handleClick 比较复杂时,应该可以通过 useCallback 提高性能。虽然 const handleClick 是一个新的变量,但函数体被记忆 /缓存了。 另,我还"隐约"记得,button1 的写法,当用户点击 button 时,会触发"两"次 render,我不记得为什么了?是我记错了么? 最后,有没有什么 debug 方法,能够知道,比如,我点击 button1 后,跟踪一下,触发了多少次 render ? 谢谢! | |||||||||||||||||||||||||||||||||
| Posted: 24 Jun 2021 01:01 AM PDT 前言
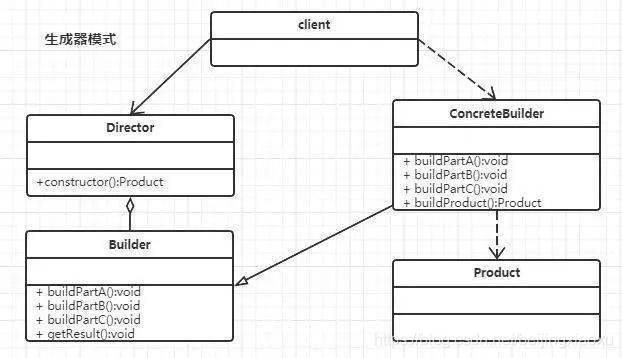
网上讲解设计模式都是基于 so 我们的 生成器模式
来看概念:生成器模式是一种
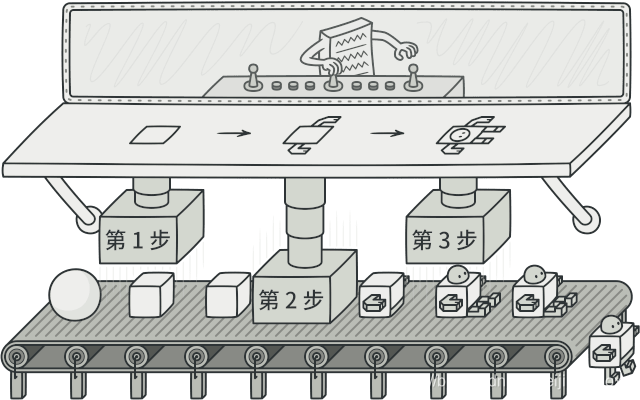
概括的说:有些对象的创建流程是一样的,但是因为 基本看不懂啥意思, 来看结构:
实战学习概念性描述你懂了么?不懂就对了,程序员先理解概念不如直接上代码来的刺激。
上实战~ 产品需求
pm 要在自家的电商网站电脑产品垂类下增加报价功能。 PRD 描述当用户进入 mac 品牌的详情页,他可以选择 I7 CPU,500G 内存,1T 磁盘的配置,查看报价。 不同品牌的部件价格不相同,并且不同品牌在同一时刻有不同的优惠折扣。 需求目标: 实时计算出用户选择的电脑配置折后价钱。 需求收益: 提高下单率 50% 技术文档
乍一听感觉很简单,没什么复杂逻辑。 其实真的很简单。但是问题是不同品牌的部件配置价格不同,而且不同品牌的折扣也是不同的。用户选择了 A,B,C-Z 一坨配置,我的代码要这么写么? 这样看这坨代码的代码量绝对高,并且大部分是重复代码,而且当电脑配置越来越多,getMaxPrice 函数入参也跟着变多,参数顺序谁能保证?有的产生是必填有的是非必填,怎么帮助必填的没有被漏掉? 这样的代码时间久了,逻辑看着很简单,但是没人敢用吧。 怎么办呢? 使用生成器模式来解决是不是好一点,每个部件作为一个生成步骤,每次执行一个步骤即添加一个部件配置,最终生成一个完整的电脑报价,并且设置部件、获取折扣、计数报价这些步骤本身是有序的,是可以通过生成器模式中的 Director 小干部来统一操作的。 好,来看代码吧! 代码"文档"
1. 2. 3.开始定义各个电脑品牌抽象生成器 先看 Mac 的 在看一个 huawei 的。 看到区别了吧,两个品牌生成器的 来看主管 到这块是不是差不多看懂了?最后我们看下客户端是如何调用实现的: 上线效果还是符合预期的!
生成器优缺点
思考
收工
** [点击] 关注再看,您的关注是我前进的动力~!**
| |||||||||||||||||||||||||||||||||
| Windows-server2008 设 DNS 解析, active directory 勾选是灰色的,怎么办? Posted: 24 Jun 2021 12:56 AM PDT 设正向解析以及反向解析 发现不管正向还是反向建立区域向导,正向搜索区域 /右键 /新建区域,"主要区域"并选中"在 Active Directory 中存储区域(只有 DNS 服务器是可写域控制器时才可用)"复选框是灰色的。。。无法和 Active Directory 活动目录集成 它要求 DNS 是域控制器,要怎么具体配置的?网上没搜到相关内容 T_T | |||||||||||||||||||||||||||||||||
| Posted: 24 Jun 2021 12:22 AM PDT 最近要用到 echarts 和 xerces,现在才发现 apache 域名的所有网站都上不去。。。 挂梯子也上不去,但是群里面北京那边的就可以上,我这里是湖北的。 求支招。 | |||||||||||||||||||||||||||||||||
| Posted: 23 Jun 2021 11:39 PM PDT 为什么 try 放在 function 里面就没有作用了,可以拿什么代替? def theUpdate(bookName, addQuantity): | try: | | str(bookName) | | int(addQuantity) | Except........(省略) 这里的 try 并不能起到把 bookName 改成字符串, 也不能把 addQuantity 改成一个数字。不知道有没有更好的方法。 | |||||||||||||||||||||||||||||||||
| Posted: 23 Jun 2021 11:13 PM PDT 不知道为何,我的 Windows 上面所有的 UWP 应用都出现了或多或少的渲染问题,很多区块没有办法正常显示。譬如 OneNote for Windows 10 变成了下边这样⬇️️
如果我将鼠标移动到这些渲染失败的区块上,如果区块中的按钮更新了其内容,那些空白就会被刷新过的视图覆盖,按钮就会回来了。 奇怪的是,这些渲染问题只会在我的电脑的外接显示器上出现。如果通过本机的显示器就不会出现一样的问题。 我的电脑配置如下:联想拯救者 R9000P RTX3060,Window 版本为 21H1 19043.1055 。出现问题的时候是工作在混合模式下的,但是似乎无论是指定 AMD 集成显示卡还是 nVDIA 显示卡运行,都一样会出现这个问题。 | |||||||||||||||||||||||||||||||||
| Samba 在共享的时候,如何比较好的设定:可写但不允许删除目录? Posted: 23 Jun 2021 10:38 PM PDT 为什么会有这种需求呢,我共享了几个目录给大家用。主要是共享的东西比较重要,怕被误删除。 所以我在每个目录下用 git 做定期备份,所以.git 目录是不能被删除,同理.git 上一级目录也不能被删除。 这样即使其它文件他们怎么折腾都可以,我都可能通过 git 去还原。(关联的帖子: https://v2ex.com/t/785482 ) | |||||||||||||||||||||||||||||||||
| Posted: 23 Jun 2021 10:09 PM PDT 这个状态包括 ajax 请求的状态,因此类似于 onPageFinished()是无效的 | |||||||||||||||||||||||||||||||||
| Posted: 23 Jun 2021 08:11 PM PDT git 提交的时候能不能自动忽略大文件(比如超过 100M ),然后给个提示消息就好了。 | |||||||||||||||||||||||||||||||||
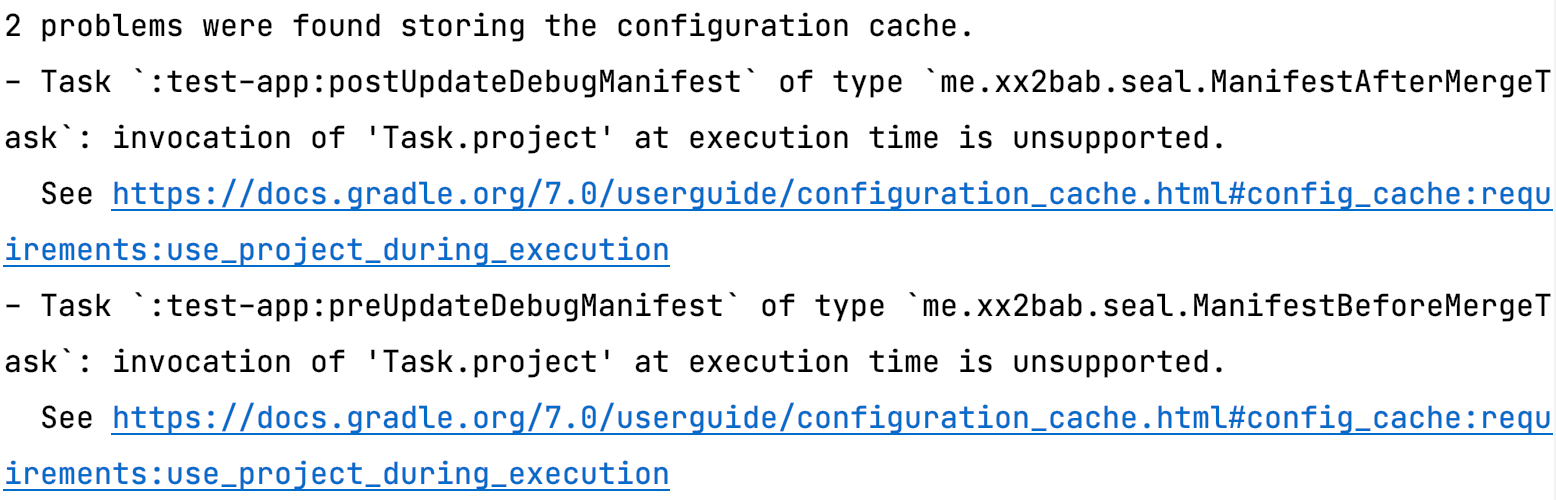
| Posted: 23 Jun 2021 07:45 PM PDT 我的博客原文:https://2bab.me/2021/06/17/google-io-21-agp-recap 距离 Google I/O 2021 已经过去了将近一个月,最近捋了捋关于 Android Gradle Plugin ( AGP )方面的东西,主要集中在 "What's new in Android Gradle plugin" 这个 session 。不过由于 2020 年没有 Google I/O,线下的活动也因为疫情全部暂停,所以这个 session 短短 11 分钟,信息量却相当大,几乎可当作是这两年更新的重点浓缩(前后看了三遍)。也因此,这篇文章里我会放出很多额外的参考资料,挖了下最近一两年大家可能忽略了的 talks/posts/repos 。文章整体脉络仍按这个 session 的 agenda 来。 性能提升Configuration CacheGradle 的生命周期分为大的三个部分:初始化阶段( Initialization Phase),配置阶段( Configuration Phase ),执行阶段( Execution Phase )。其中任务执行的部分只要处理恰当,已经能够很好的进行缓存和重用——重用已有的缓存是加快编译速度十分关键的一环,如果把这个机制运用到其他阶段当然也能带来一些收益。仅次于执行阶段耗时的一般是配置阶段,而今年 AGP 给我们带来的 Gradle Configuration Cache 的支持,一项自 Gradle 6.6 起开始孵化的新功能。它使得配置阶段的主要产出物——Task Graph 可以被重用,在示例的项目中这个优化可以带来 8s 左右的不必要等待(如果 Gradle 脚本配置并没有改变)。
想体验这项优化只需要在执行 Gradle 命令时加入 第一次使用时会看到计算 Task Graph 的提示:
成功后会在 Build 结束时提示:
之后 Cache 就可以被下一次构建复用(如果没有构建脚本修改):
作为插件使用者,发现常用插件出现不支持的情况,可先搜索是否有相同的问题已经出现,例如下面这个 Kotlin 1.4.32 插件和 Gradle 7.0 配合时出现的问题:
在这个 YouTrack issue 下我们可以简单看到通过升级 Kotlin 插件版本至 1.5.0 以上即可解决。 事实上 AGP/Kotlin/Gradle 核心的几个插件(主要是背后的 Tasks )在最近的版本都已经支持 Configuration Cache,通过这几篇文档 /issue 可以了解大概:
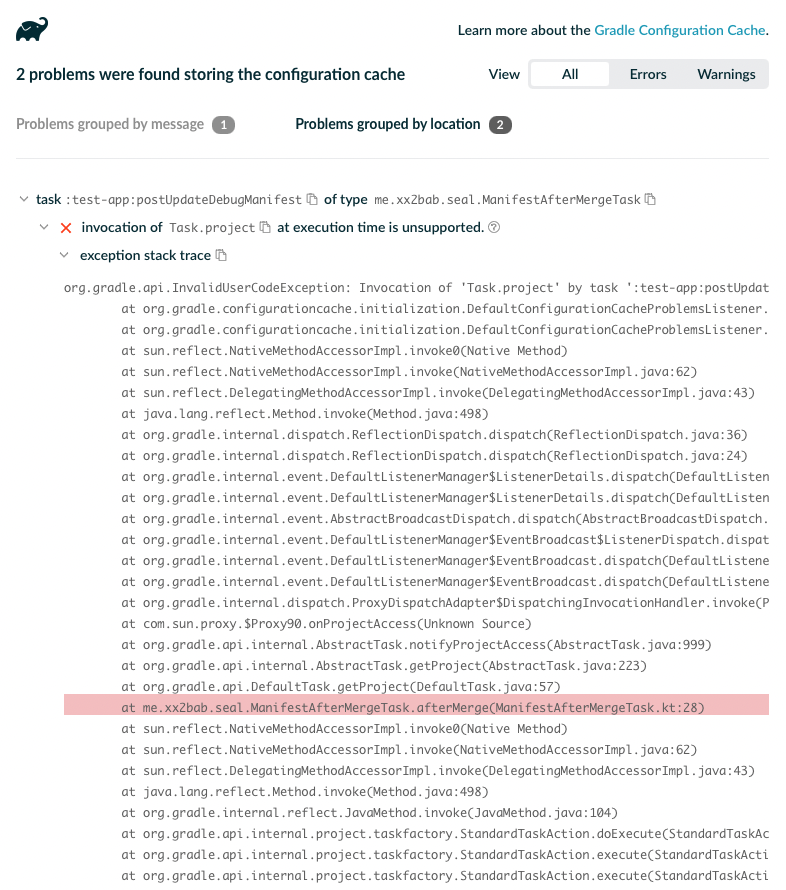
而作为插件开发者,则还要关心 Configuration Cache 的适配工作。其重点在于:Task 的参数和内部实现需要避开直接传入 /使用 Gradle 的几个 Context 及一些无法序列化的类。以我维护的 Seal 插件为例,它是一个解决
通过构建结束时输出的 Configuration Cache HTML Report 我们可以查看到详细的堆栈:
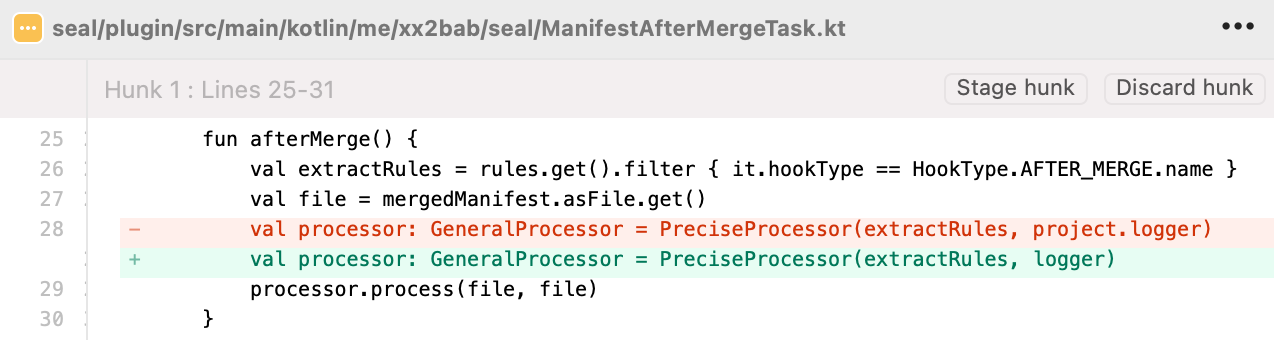
针对这个错误,其实仅仅需要把
对于更复杂的规则和用例,可以参考 Gradle 的文档以及 AGP 兼容 Configuration Cache 的心路历程(修复了 400 多个 issues ): 最后,有个 Gradle 官方维护的 android-cache-fix-gradle-plugin ,一些 AGP build cache 、configuration cache 的特殊问题,可以在此处查阅下,说不定正好是你项目碰到的。 Non-transitive R-classes事实上 R 文件的这类特性已经发展了很多年,可以参考这篇按时间顺序整理的文章。但是最新的
开启方式如下:
这个操作帮助你自动添加两行特性开启的代码到
Cacheable Lint TaskLint 的运行一直是耗时大户,在 AGP 7.0 后(最早计划于是 3.5,见这篇文档),终于正式成为可缓存的 Task 。 其他另外 AS + AGP 自 4.x 以来还有一些提升的点:
可以在 AGP/AS 的 Release Notes 里找到这些信息。
新的 DSLDSL Doc 迁移至 android.com旧的 AGP DSL 文档 从 3.4 之后就不再更新了。新的文档迁移至 android.com,更加统一。依旧可按版本查看:
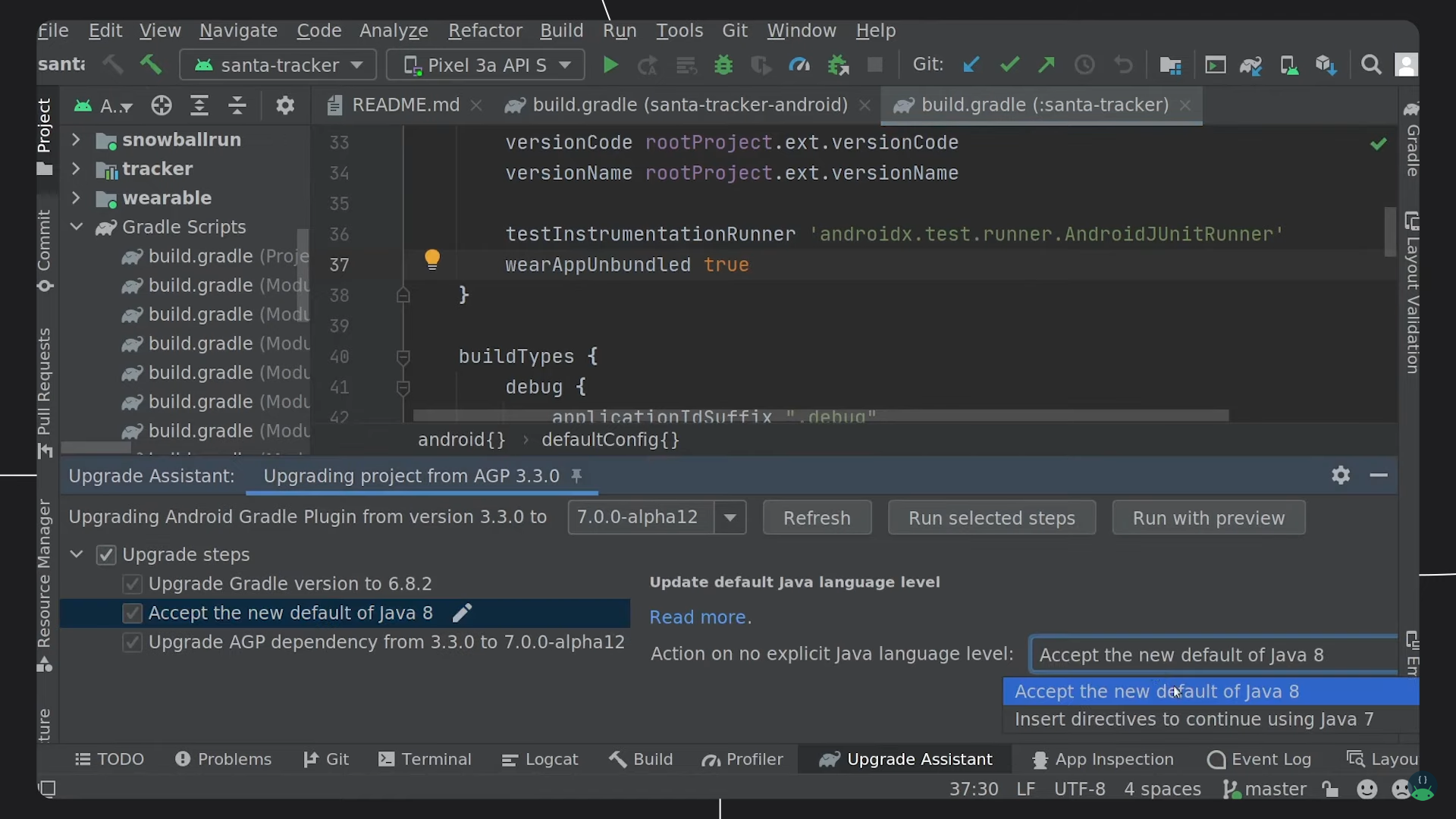
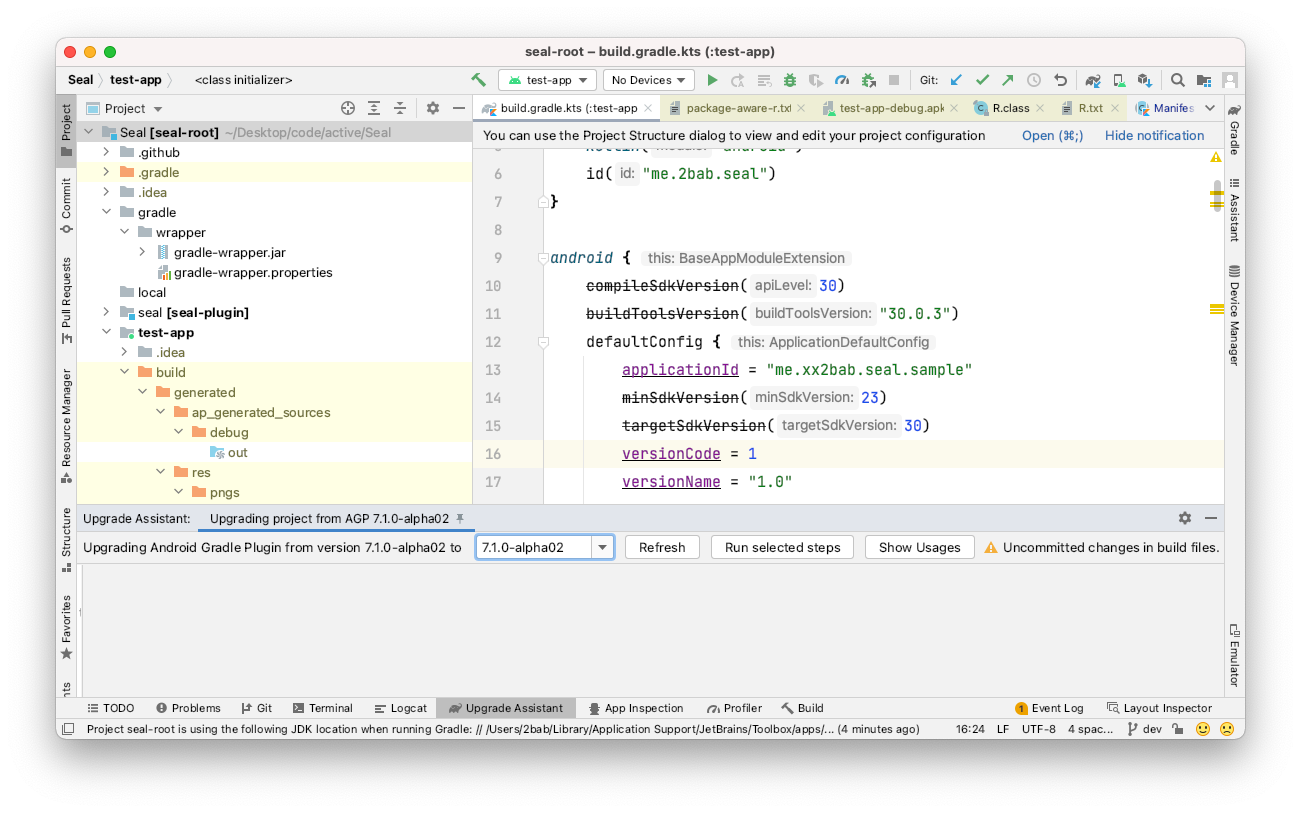
这个变化也反映在了 google source 的 tag 上,对于 AGP 源码来说 Android Studio 提供的 AGP 升级助手为了让开发者便捷流畅地升级 AGP,AGP 配合 AS 的推出了升级助手功能。这个新特性已经迭代了几个版本,目前对 Gradle Groovy DSL 脚本的升级十分有用,当你看到升级提示时(一般发生在刚打开一个工程时):
点击
不过对于 Gradle Kotlin DSL 的支持还有待补齐,例如基础的
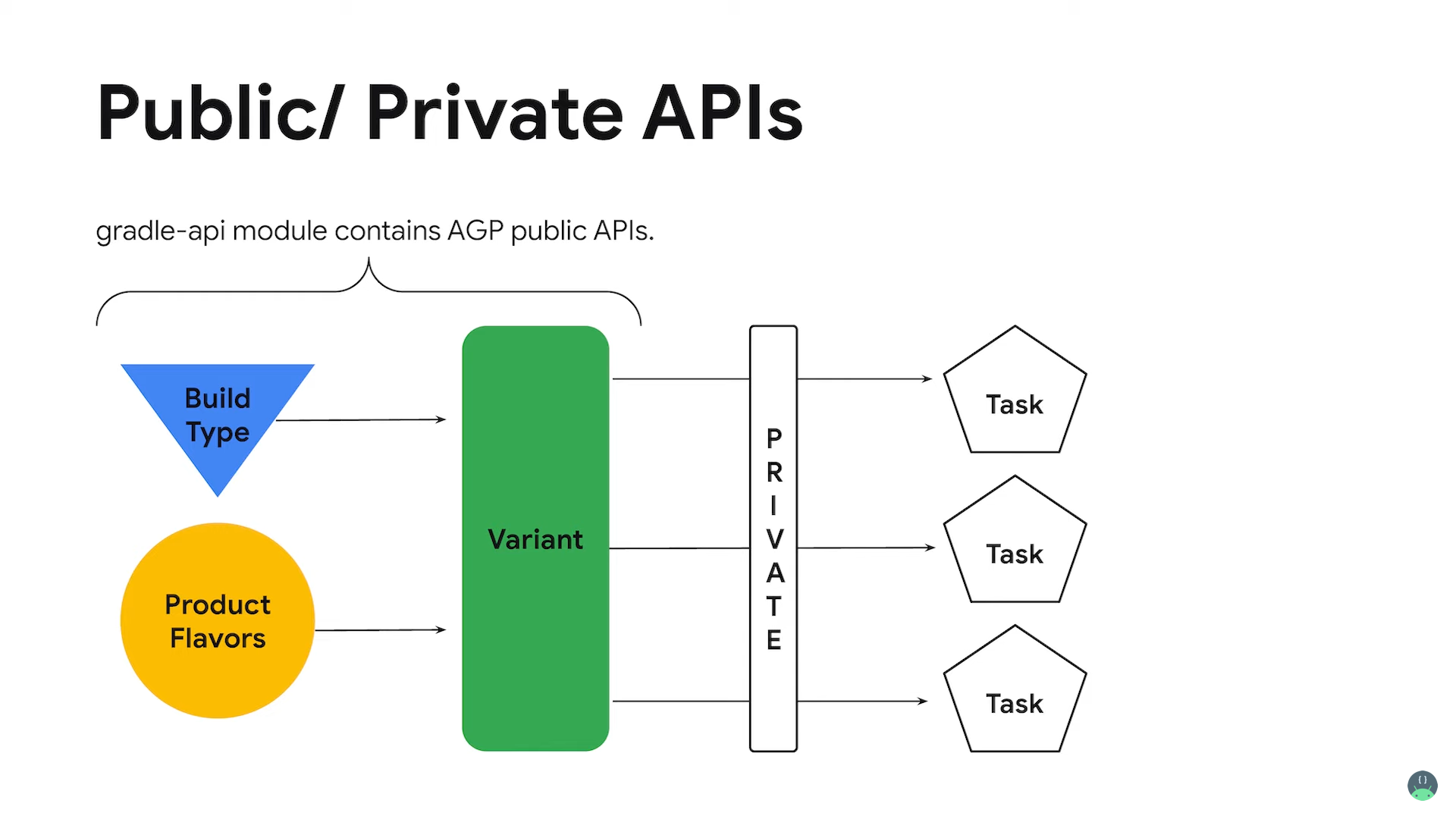
当然,复杂的对象引用也无法帮你直接修改,例如 新的 Variant APIVariant API 是这两年 Android 与插件开发相关的最重要更新,如果之前没有针对 AGP 生态开发过协同插件的朋友可以通过下面这张图"了解什么是 Variant"?
Variant API 的更新可以概括:为了使协同插件的开发者依赖于更稳定的 API,将原来的 Variant 遍历入口变更大部分 AGP 生态的协同插件都需要注册 Variant aware 的 Task,即遍历 Variant 注册与其对应的自定义 Task,例如上面提到的 Seal 插件的 或者 Kotlin 的版本: 如果是适用于 library 的插件则需要 这类 API 现在改成了 这里获取到的 Variant 是 com.android.build.api.variant.ApplicationVariant,Extension 则来自于 com.android.build.api.extension.ApplicationAndroidComponentsExtension。另外一个可能会用到的接口是 部分自定义 Task 的简化这类简化指 Task 插入点和 Task 参数获取(注入)的简化,提供这类特性的 API 也称之为 Artifact APIs 。在比较经典的模式里:对于插入点,一般我们会手动找到 Task 的前后依赖关系,使用 Gradle API 进行依赖关系重新梳理(甚至可能要自定义一些新的生命周期锚点 Task 辅助);对于 Task 的参数,就使出各种奇技淫巧,从已有 Task 里的参数 /中间产物 /私有对象等找到我们需要的数据,再注入到自定义的 Task 中。而现在 Artifact APIs 规范了一套标准操作,使得我们可以简易地和已有的数据、中间产物进行交互,实战角度来看我们可以分为两种模式: 复杂的 Transform/Append/Create 操作:插入 Task 到特定节点和 Task 参数注入一条龙服务,一般适用于需要定义某个具体的插入点; 纯粹的 Get:主动获取 intermediates,一般适用于较为独立的 Task,没有严苛的插入位置要求(但是藉由 Provider 的传递会有隐式的 Task 依赖),没有需要替换等操作: 更多从实用的角度来说,新的 Variant 接口、Extension 接口公开的 API 比之前少了,但更加规范。Artifacts 作为手动获取 Task input/output 的补充,目前的公开 API 也还比较少,希望插件开发者们在遇到合理的需要公开的 API 但目前还没有时,给 AGP team 多提点 issue :)。 另外,限于篇幅我无法在这里介绍全部的 Variant API 更新,包括新的
新的 ASM API
ASM API 是之前 Transform API 的替代品,旨在更低成本地提供一个 Class -> Dex 之间的插入点用以修改字节码。它没有了之前 Transform API 的灵活性,比如目前看起来它和 ASM 字节码工具是绑定的,不支持 Javassist 或者 Aspect 等。但同时,它拥有更好的性能,更低的使用成本(指实现 transform 本身,因为 ASM 实际上是相对 Javasssist Aspect 更底层的 API,更灵活、学习成本也更高),以及更容易适配 Gradle 的新特性。目前刚刚开始孵化,从 API Doc 来看还不推荐开发者使用它来构建一个生产环境的插件。 上面代码用到的 API 可以参考如下说明: 对经典的 Transform 不熟悉的朋友可以看下几个知名的 Transform 库封装(挺巧都是中国公司的开源项目): 总结从开发者的角度来看,Android 工具团队在 AGP & AS 上更加注重 Engineering Experience 的东西了。在解决了很多历史遗留问题的同时,这次的 Session 还透露出对 AGP 周边生态的建设的长远计划,希望明年可以看到这些东西真的被更多 Android 开发者接受,到时候我也一定再写一篇 22 年版的总结和前瞻。 我的 Github / 公众号 。 | |||||||||||||||||||||||||||||||||
| Posted: 23 Jun 2021 07:23 PM PDT 准备补票 WinRAR,但支付时候除了本体还看到有个 WinRAR Maintenance: The WINRAR Maintenance Package includes:
Premium Support 和 Lost Key Support 没什么用,重点似乎是 Upgrade Assurance,时效一年。 (可我似乎没找到 WinRAR Maintenance 的续费链接... 我看 chiphell 上有老哥说 WinRAR 买正版后可以一直使用最新版本,那这个 WinRAR Maintenance 是怎么回事? 我只买本体?还是连 WinRAR Maintenance 一起买?一年以后更新版本怎么办? | |||||||||||||||||||||||||||||||||
| 关于在一个服务端 urlencode 编码后传递的 post 参数请求时候 在 nodejs 接收时报错 Posted: 23 Jun 2021 06:08 PM PDT 报错内容是:[INFO] console - { inspect: [Function: inspect] } 因为用的 koa-bodyparser 对方描述说希望我这边(node)接收时解码就行了 不知道在哪个地方解码.. 有没有大神指点一下啊.. | |||||||||||||||||||||||||||||||||
| Posted: 23 Jun 2021 06:02 PM PDT import requests SCKEY = '666' url2 = 'https://api.tokyo.biliob233.com/user/check-in' cookie2 = 666' def it(): headers = { 'user-agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/80.0.3987.163 Safari/537.36', 'cookie': cookie2 } res = requests.post(url=url2, headers=headers).text print(res) # 微信推送 def pushWechat(desp, nowtime): ssckey = SCKEY send_url = 'https://sc.ftqq.com/' + ssckey + '.send' if '登录' in desp: params = { 'text': 'bilibiliob 签到失败提醒' + nowtime, 'desp': desp } else: params = { 'text': 'bilibiliob 签到提醒' + nowtime, 'desp': desp } requests.post(send_url, params=params) f = open('bilibiliob.txt', 'w+', encoding='utf-8') f.write(res) f.close() desp2 = 'bilibiliob.txt' desp = desp2.read() # 读取数据 pushWechat(desp, nowtime) return desp def main_handler(event, context): return it() if __name__ == '__main__': it() 已签到时:{"code":-1,"msg":"已经签过到了"} 失效时:{"code":-1,"msg":"未登录"} 我想让程序检测到"登录"这个词出现时,发送失败提醒,否则签到成功提醒,不知道是不是因为没写入还是 desp 没读取,反正没有推送 | |||||||||||||||||||||||||||||||||
| 有没有比较安全、好用的纯净版 win7/win10 gho? Posted: 23 Jun 2021 03:14 PM PDT 原版安装较慢,很多驱动需要手工打,较麻烦。请大虾们告知一些安全、好用的纯净版 win7/win10 gho 下载点,感谢。 | |||||||||||||||||||||||||||||||||
| Posted: 23 Jun 2021 12:51 PM PDT Gen Web - 基于 Gin 框架封装的脚手架结构,便于快速开发 API https://github.com/wangbjun/gen 介绍主要使用以下开源组件:
项目目录结构清晰明了,简单易用,快速上手,包含了一个用户注册、登录、文章增删改查等功能的 Restful API 应用,仅供参考! 主要包含以下 API:
架构项目采用了依赖注入的方式贯穿全局,我们可以把 DB 、缓存、HTTP API 等功能看作是项目的一个服务,通过 facebook 开源的 inject 库,我们在启动项目把这些 既灵活,也不影响性能,因为虽然依赖注入使用了反射,但是我们只在程序启动之前做这件事,而且只需要进行一次。 启动流程
紧接着,创建一个 这个 Server 实例是管理所有服务的中心,其主要工作就是加载配置文件,然后根据配置文件初始化日志配置,日志库采用 zap log,主要文件在 然后还有一个最重要是就是初始化所有注册过服务,执行其 如果一个服务实现了 HTTPServer 的代码在 代码介绍在 项目整体是一个 3 层架构,即控制器层、Service 层、模型层。 个人理解,控制器层主要做一些接口参数校验等工作,模型层主要是数据操作,Service 层才是主要的业务逻辑。 数据库相关配置在 项目使用了 Gorm ( 2.0 版本),具体详细用法可以参考官方文档。 路由文件位于
关于接口参数,建议 POST 、PUT 统一使用 JSON 形式,在模型层里面定义好相应的结构体,参数的校验采用了 。。。 。。。 。。。 | |||||||||||||||||||||||||||||||||
| 使用共享协议(NFS、SMB、FTP、WebDav 等)实现的 NAS 存储需要哪些软硬件支持? Posted: 23 Jun 2021 11:42 AM PDT 如题,前段时间买了一款网络摄像头,到手后发现不支持 nas,但同个品牌的其他价格更高的摄像头可以支持,关于 nas 存储的实现,只知道怎么搭建,但不清楚其底层协议的实现是否需要附加的软硬件环境(厂家需要更多成本)支持。想问一下各位大佬,这里是因为增加 nas 存储功能相应也一定幅度的提高了生产成本(软硬件环境相差比较大)?产家为了降低成本不予支持?还是明明可以支持,故意砍掉,让买家去购买更高价格的产品?另外如果需要的话,具体是哪些软硬件环境才支持? PS:当然一个产品加多一个功能,需要多消耗一份人力去维护。不过站在开发者的角度讲,跟基本相差无几的同类产品相比,几乎等于维护同一份功能开发支出。谢谢大家回复。 | |||||||||||||||||||||||||||||||||
| 通过点击 Sublime Text 的付费提示的确认按钮继续使用算不算破解和盗版? Posted: 23 Jun 2021 11:33 AM PDT | |||||||||||||||||||||||||||||||||
| Linux kernel 4.4 模块编译 提示 module PLT section(s) missing Posted: 23 Jun 2021 09:34 AM PDT [ 1854.285430] nfs: module PLT section(s) missing [ 1854.317509] nfs: module PLT section(s) missing 请问 如何解决. | |||||||||||||||||||||||||||||||||
| Posted: 23 Jun 2021 06:34 AM PDT 不得不说,刷题已经和爬山、溜娃一样,成为湾区三俗,基本几个湾区的工程师碰在一起,讨论的话题总跳不出这个圈。爬山,哦不,刷题作为一个贯穿码农整个职业生涯的必须品(就算是我目前呆的微软谷歌这种养老公司也总得跳一跳,毕竟雪花的大包裹是真香啊),几年来基本每天不间断的刷,算是对这一块略有心得。帖子的前半部分想分享一些我作为面试官的常出的一些经典题目,以及题目思路的解析以及一些同类题的归纳,帖子的后半部分我会参考坛友们的留言和拍砖,来决定后面的走向 帖子会长期保持更新,只要是带娃的间隙就会偷偷上来更一下,尽量保持每周两更。 本期我们分享 面试经典题目--公交路线 感兴趣的可以关注公众号--大牛门徒 | |||||||||||||||||||||||||||||||||
| Posted: 23 Jun 2021 06:33 AM PDT 大家好。 数据都在数据库里面,想做一个客户端( library )给用户,又可以调用数据,又能使用这个客户端里的功能。客户端里面有一些复杂的 class,包含了业务逻辑,这样用户可以用 oop 的界面去做更高层次的研究。 刚开始想用 http 的,但是 django 这边做一遍,客户端又要解析 json 、写逻辑,显得非常麻烦。突发奇想直接把 django 的 orm 和 drf (用来序列化)剥离出来放到客户端里,用户提供一个数据库的 read-only 账号就能完成全部操作。我在客户端里写逻辑也比较容易,因为有了 django model 后 ide 提示很不错 ( http json 反序列化后还要写一遍 attribute 就太蛋疼了) 因为客户端里逻辑全写完了,以后我自己 django 后端给网页写 api 也是直接可以复用,把这些 object 直接序列化就行了。 网上看了下,好像这种用法不多见?有什么隐藏的问题吗? 然后就是有没有办法低成本迁移带有业务逻辑的 python class 到前端的 javascript class ? |









| You are subscribed to email updates from V2EX - 技术. To stop receiving these emails, you may unsubscribe now. | Email delivery powered by Google |
| Google, 1600 Amphitheatre Parkway, Mountain View, CA 94043, United States | |
No comments:
Post a Comment