V2EX - 技术 |
- 360 浏览器做了什么 让拼多多这么忌惮
- 看到「学什么新语言」这个问题,推荐这本书
- 求一个减法递推
- 昨儿生日给自己做了个游戏
- 前端发来的数据包含增删改查多种操作时,应该如何接收处理?
- 请问 dnspod dns 的 ca 证书如何下载,用于 routeros doh 解析。
- 之前设计的 HTTP 状态码 T 恤开源了,感兴趣的同学可以自己印制
- 想用桌面版 Google 云端硬盘把本地所选文件夹实时同步到 Google Drive,结果却发现同步到 Google Drive 里的文件夹不在 ”我的云端硬盘“,有什么办法可以让本地文件夹自动同步到 ”我的云端硬盘“ 吗?
- winserver 云服务器求推荐
- 关于 Django 执行单独文件时导入内部包的问题
- 如何选择最适合你的分布式事务方案
- Server 2022 release 以及 Server 貌似彻底和 ltsc 以及个人版分家了
- 钱包节点可以被 DDOS 吗? 如果是如何防护
- Windows 11 引入番茄时钟功能,可以关联 To do 和 Spotify,有点强
- requests 的 post 中的 data 如何按顺序进行封装?
- Python 图片去除图片水印的问题
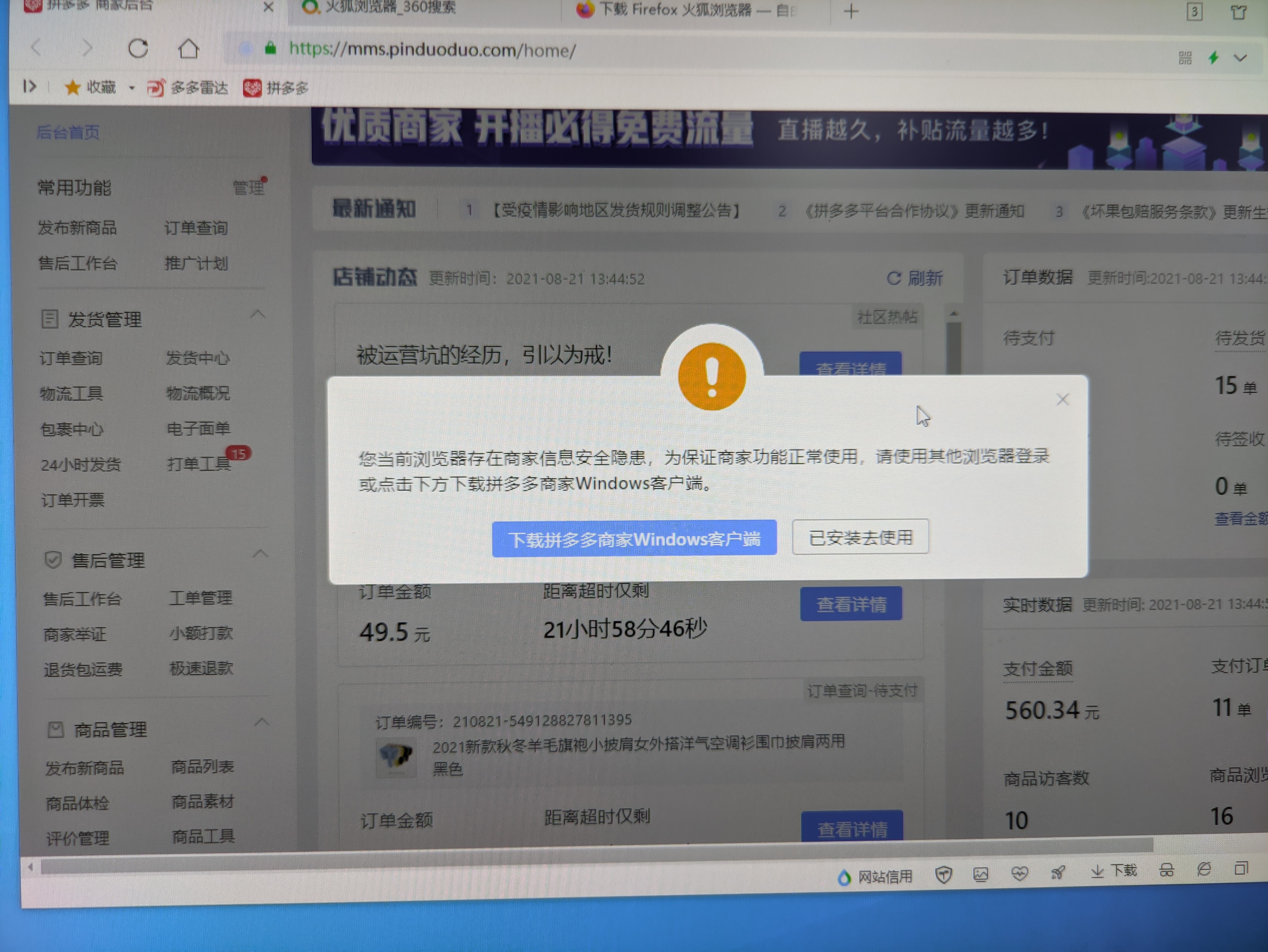
| Posted: 21 Aug 2021 03:51 AM PDT
| ||||||||||||||||||||||||||||||||||||
| Posted: 21 Aug 2021 03:19 AM PDT 《七周七语言:理解多种编程范型》 https://book.douban.com/subject/10555435/ 书里囊括了颇有代表性,但很多程序员未必了解的 7 种语言:
书的篇幅没有那么长,这些语言也未必能用在实际工作上,但一定能打开你的眼界。书里介绍的语言,和 vczh 之前推荐的几门编程语言( https://www.cnblogs.com/geniusvczh/archive/2013/04/27/3047560.html , Go 语言粉丝请不要点开这个链接!)也高度重合。 这里( https://segmentfault.com/a/1190000002944730 )还有一篇对作者的采访。他甚至后来还写了第二本书( https://book.douban.com/subject/26921107/ ),包括 Lua 、Idris 、Elm 、Elixir 等。 「语言都是工具」这话本身是没错的,但喜欢说这句话的人时常是在表达一种虚无主义的态度,即「什么语言都一样」。但锤子和螺丝刀都是工具,大概人们也不会混用它们吧? | ||||||||||||||||||||||||||||||||||||
| Posted: 21 Aug 2021 03:14 AM PDT 16->23->33->57 id 为 16 是顶级,id 为 57 是最下级 比例分配思路是 id=16 的 | ||||||||||||||||||||||||||||||||||||
| Posted: 21 Aug 2021 03:11 AM PDT 忽然想到作为码农的人生总结应该在 V 站发一下( ADV,而且剧本比较矫情,过敏者慎入 对我而言,28 岁就意味着国内社会意义的 30 岁( 14 岁=中二,28 = 14 x 2 值得讽刺的是从大学就开始做游戏的我尝试了很多次,却一直没有完成品,第一个"完成"的作品居然是以这样的形式完成的 前前后后大概花了两个月,没有美术音乐全是自己用照片和素材拼凑的(不涉及商用应该没什么问题吧,只有视频也没放出原游戏 不要颜面得说,这两天自己对着自己做的这个游戏看了好多次发呆了很久,又对比了下大学时候写的那个充满希望和纯真的游戏 DEMO(梦见星空之诗),尤其是在深夜的时候,居然会哭出来。 感觉这么多年除了技术上的成长是正面的和我想要的,其他的所谓"成长"都是负面的、我从来不想要的,并且这些负面的东西反过来也影响了很多部分的技术理想。 以上种种加上最近各种形势的变化,从未迷惘信念坚定、一直相信未来会更好的我竟然有些迷惘了。。。直到三年前愿意相信世界上大部分事物都是美好的那个少年,现在竟然变成了这个样子 挺唏嘘的。。。 | ||||||||||||||||||||||||||||||||||||
| Posted: 21 Aug 2021 01:27 AM PDT
| ||||||||||||||||||||||||||||||||||||
| 请问 dnspod dns 的 ca 证书如何下载,用于 routeros doh 解析。 Posted: 21 Aug 2021 01:16 AM PDT 如题。 | ||||||||||||||||||||||||||||||||||||
| 之前设计的 HTTP 状态码 T 恤开源了,感兴趣的同学可以自己印制 Posted: 21 Aug 2021 12:29 AM PDT | ||||||||||||||||||||||||||||||||||||
| Posted: 20 Aug 2021 11:45 PM PDT 想用桌面版 Google 云端硬盘把本地所选文件夹实时同步到 Google Drive,结果却发现同步到 Google Drive 里的文件夹不在 "我的云端硬盘",而在 "计算机 > 我的笔记本电脑" 里了,有什么办法可以让本地文件夹自动同步到 "我的云端硬盘" 吗? 自己尝试解决但未成功的办法: 已经尝试过把要同步到 Google 云端硬盘的本地文件夹复制粘贴到 "此电脑 > Google Drive(G:) > 我的云端硬盘" 路径下,但同步时被桌面版 Google 云端硬盘提示「文件系统不受支持,因此无法同步 "G:\我的云端硬盘\logseq"」。 个人万不得已的解决办法: 把同步到 "计算机 > 我的笔记本电脑" 下的文件夹,然后到网页版 Google Drive 手动制作一份副本,然后再移动到 "我的云端硬盘",但这样太麻烦了,每次本地文件夹有新同步时,就要重新手动制作一份副本,然后再移动到 "我的云端硬盘",而且还要把之前的旧的副本删除。 桌面版 Google 云端硬盘使用过程中出现的问题: 问题一: 在安装桌面版 Google 云端硬盘时 Google 不给选择安装位置,如果点 Next 就会直接强制默认安装在 "C:\Program Files\Google\Drive File Stream\50.0.11.0" 。 这里说明这个情况是因为我在网上看到一些过时的文章说「默认直接安装在了 C 盘的 "C:\Users\yourusername" 路径下,这就导致如果我们想要将那些文件实时同步到云端,就需要将这些文件放在该目录下,即 "C:\Users\yourusername\Goole 云端硬盘" 目录下」,按这个意思要同步本地某一文件夹到云端硬盘还要把文件夹放在特定目录,但据我实测我的桌面版 Google 云端硬盘默认安装在了 "C:\Program Files\Google\Drive File Stream\50.0.11.0" ,上面已经说过了,而我一开始选的 D 盘某一文件夹,也同步成功了,只是没同步在 "我的云端硬盘" 而已,难道几年前必须先把本地需要同步的文件夹放在特定目录后才能用桌面版 Google 云端硬盘同步?我看知乎也有网友在几年前发帖求问有关 Google 云端硬盘如何更改同步文件夹的帖子。 我不知道现在还是不是仍然有这个问题存在,所以想问问现在使用桌面版 Google 云端硬盘同步本地文件夹的各位 V 友你们知道这个吗?求一个安心。反正现在我这是安装位置在 C 盘,同步本地文件夹时只要选择好要同步的文件夹即可,没有上面提到的那些顾虑。 问题二: 安装桌面版 Google 云端硬盘后,"此电脑 > Google Drive(G:)" 路径下有两个文件夹,一个是我的云端硬盘,一个是其他计算机,这个其他计算机文件夹里有啥用,是桌面版 Google 云端硬盘的必要组成部分吗? 问题三: 桌面版 Google 云端硬盘偏好设置里有个本地缓存的文件目录,可以手动更改路径,网上说这个路径一定要改,因为默认路径是 C 盘,我把它改为了 D 盘,改是改好了但我不知道这个本地缓存的文件目录是干嘛的,每次桌面版 Google 云端硬盘同步本地文件夹时,这个本地缓存的文件目录里就会自动生出来很多文件夹,这是为啥? | ||||||||||||||||||||||||||||||||||||
| Posted: 20 Aug 2021 11:45 PM PDT 有以下几点要求: winserver 的云服务器是不是自家的 azure 体验最好? | ||||||||||||||||||||||||||||||||||||
| Posted: 20 Aug 2021 08:37 PM PDT . 这是文件结构,同时 main.py 处在一个 django_web 的文件夹下。 然而在配置 DJANGO_SETTINGS_MODULE 时引用 settings 文件是没问题的。sys.path 也包含了 main.py 的父目录的路径。 print(sys.path) from django_web.RealTimeData.models import RowRecord | ||||||||||||||||||||||||||||||||||||
| Posted: 20 Aug 2021 06:24 PM PDT 之前我有一篇文章,介绍了分布式事务最经典的七种解决方案,这里我们从业务需求的角度,根据不同的业务场景,给出最适合的解决方案。 当我们采用服务 /微服务架构,对业务进行分拆解耦后,原先在一个单体内,使用本地数据库保证 ACID 的数据修改,因为跨了多个服务,就不再适用了,就需要引入分布式事务来保证新的原子性。 由于分布式事务方案,无法做到 ACID 的保证,没有一种完美的方案,能够解决掉所有业务问题。因此在实际应用中,会根据业务的不同特性,选择最适合的分布式事务方案。 业务分类下面是常见的几种业务分类,以及适合的解决方案介绍 多个微服务组合成原子操作有一类业务场景是需要把多个微服务组合成原子操作:假设您有一个活动业务,用户点击领取按钮后,会领取一张优惠券,和一个月的会员。优惠券和会员分别属于不同的服务,需要都被调用,不希望出现一个服务调用成功,另一个因为网络或者其他故障导致没有成功。 这个场景适合可靠消息方案,可以使用 rocketmq 、rabbitmq 等,发送给消息队列的消息,一定要等收到队列接收确认,再返回应用程序。 本地事务+多个微服务组合为原子操作有一类业务与前一种业务情况类似,但有一些差别:假设您有一个新用户注册成功后,领取一张优惠券和一个月会员。如果注册不成功,不希望调用领取;只有注册成功才领取。 这种情况,适合本地消息方案,或者事务消息方案。这两种方案都能保证本地事务和消息的原子性。 订单类对一致性要求较高的业务订单交易类业务,涉及资金、库存、优惠券等多个服务,完成一个订单,需要相关的各个服务组合成一个整体可回滚的事务。如果订单进行过程中金额先扣减,后续因为库存不够只能退款,把金额补偿加回来。在这个过程中用户看到了金额减少,又金额变回来,体验很差。一般这类业务都会先冻结资金,如果订单能成功,再扣减资金;不能成功,则解冻资金,这样能够让资金信息对用户更友好。 这种场景适合 TCC 方案,可以在 TCC 的 Try 中冻结资金,Confirm 中扣减资金,Cancel 中解冻资金 一致性要求不高的可回滚业务如果业务对事务中的一致性要求不高,允许用户看到中间状态,例如用户的积分数据等。 这种模式适用 SAGA 模式,SAGA 对比与 TCC,只有正向操作和逆向补偿操作,会更加简单 耗时较久的全局事务耗时较旧的全局事务适合可靠消息和 SAGA,不适合 TCC 和 XA,因为大多数的 XA 和 TCC 实现,为了方便用户灵活的定义事务,通常把事务的进度保存在应用程序,一旦事务进行中应用程序崩溃,无法往前进行下一步,只能回滚。 SAGA 和可靠消息,把事务进度保存在数据库或消息系统中,任何一个组件临时的失败,如果重试成功,能够让事务继续。 其中如果整个事务是需要回滚的,那么适合 SAGA,不需要回滚的,适合可靠消息 并发度较低的业务如果业务并发度不高,事务又需要支持回滚,那么适合 XA 方案。XA 方案,除了并发不高,也还需要本地数据库能支持 XA 接口。这个方案的优点是,使用上较简单,比较接近本地事务 实践上面介绍完各种业务类型,以及适合的事务方案,通常情况下,您需要选择合适的开源项目来实施技术方案。在分布式事务领域,应用比较广泛的有DTM、SEATA、RocketMq 其中 seata 用 Java 开发,支持 Java 语言的接入,支持 TCC 、SAGA 、XA 、AT(类似 XA,性能更高,但有脏回滚) RocketMq 用 Java 开发,支持各类语言的接入,仅支持可靠消息、事务消息模式 这里重点介绍 DTM,它用 GO 开发,基于 HTTP 协议,支持多种语言接入,支持 TCC 、SAGA 、XA 、可靠消息、事务消息模式。 可靠消息例子我们拿第一个最简单的业务场景"多个微服务组合成原子操作"来看 DTM 是如何解决问题的 假设领取优惠券和会员的处理函数分别是:ObtainCoupon 和 ObtainVip,那么处理领取逻辑的处理函数(用 Go 做示例)只用这么写: dtm 收到客户端提交的消息后,会保证 ObtainCoupon 和 ObtainVip 被调用,如果任何一个出现失败,会不断重试,直到成功。 假如您采用的是 rocketmq 方案,那么您需要做以下几个步骤:
对比 dtm 和 rocketmq 的方案,dtm 仅需要简单的几行代码即可( dtm 也提供 http 的接口,可以用任何语言直接发 http 请求),清晰简单。而 rocketmq 方案,涉及较多队列的知识,要做的工作较多 SAGA 例子假设我们有一个积分兑换课程的业务,一方面积分不属于非常核心的资产,中间状态允许用户看到,另一方面兑换课程可能出现课程已拥有权限,则需要回滚,因此该业务属于"一致性要求不高的可回滚业务"。 我们采用 SAGA 方案来解决这个问题,来看看 DTM 的解决方式,代码大致如下: dtm 收到客户端提交的 saga 事务之后,会按顺序调用 AdjustIntegral,AuthCourse,如果函数返回错误要求回滚,dtm 则会调用 AuthCourseRevert,AdjustIntegralRevert 进行回滚。 如果您没有采用 dtm 方案,那么您可以采用 SEATA 的 SAGA,涉及比较多的背景知识,接入较复杂。 更多的例子您可以访问https://github.com/yedf/dtm ,里面有很多的分布式事务例子 多种模式并存如果您的实际项目,涉及分布式事务的场景较多,一种事务模式,可能并不满足需求,可能需要使用 SEATA+Rocketmq,接入以及维护成本较高。而 DTM 提供了一站式的解决方案,对常见的各种业务场景都提供了便捷的支持。 小结dtm 作为一个新兴起的分布式事务框架,提供了强大的功能,以及简单易用的接口,极大的简化了微服务架构下,分布式事务的使用。 下面是 dtm 与 seata 的主要特性对比:
dtm 的项目地址为https://github.com/yedf/dtm ,欢迎大家访问、试用、点亮 star | ||||||||||||||||||||||||||||||||||||
| Server 2022 release 以及 Server 貌似彻底和 ltsc 以及个人版分家了 Posted: 20 Aug 2021 05:16 PM PDT https://docs.microsoft.com/en-us/windows-server/get-started/windows-server-release-info https://docs.microsoft.com/en-us/windows-server/get-started/whats-new-in-windows-server-2022 以后 Server 只有长期大版本 2022 基于 20348 而 Ltsc 疑似基于 19044 | ||||||||||||||||||||||||||||||||||||
| Posted: 20 Aug 2021 05:05 PM PDT 这个问题比较弱智, 因为钱包机器没有 ip 地址.理论上没办法定位, 但是如何避免呢? | ||||||||||||||||||||||||||||||||||||
| Windows 11 引入番茄时钟功能,可以关联 To do 和 Spotify,有点强 Posted: 20 Aug 2021 03:14 PM PDT Windows 11 自带时钟应用
| ||||||||||||||||||||||||||||||||||||
| requests 的 post 中的 data 如何按顺序进行封装? Posted: 20 Aug 2021 06:39 AM PDT 假设 data 如下 data={ a = '11', b = '22', c = 某个变量, d = 另一个变量, e = '33' } 然后我 requests.post 理论来说 他 data 的顺序应该是 a=11&b=22.....依次按顺序,但是我测试抓包发现,他顺序是乱的,特别是变量,他可能会封装成 a=11&c=某个变量&d=另一个变量值&b=22..... 我想让他就按照从上往下的顺序进行封装起来,百度了下也没人问这类的问题,请问有解吗? | ||||||||||||||||||||||||||||||||||||
| Posted: 20 Aug 2021 05:43 AM PDT 代码 我在网上搜的,但是这个样子会留下背景版,如果吧整个水印都删除呢, 也就是指定区域的部分都删除,这种效果该怎么做呢? |































| You are subscribed to email updates from V2EX - 技术. To stop receiving these emails, you may unsubscribe now. | Email delivery powered by Google |
| Google, 1600 Amphitheatre Parkway, Mountain View, CA 94043, United States | |
No comments:
Post a Comment