V2EX - 技术 |
- 最近总是被 google 阻断连接
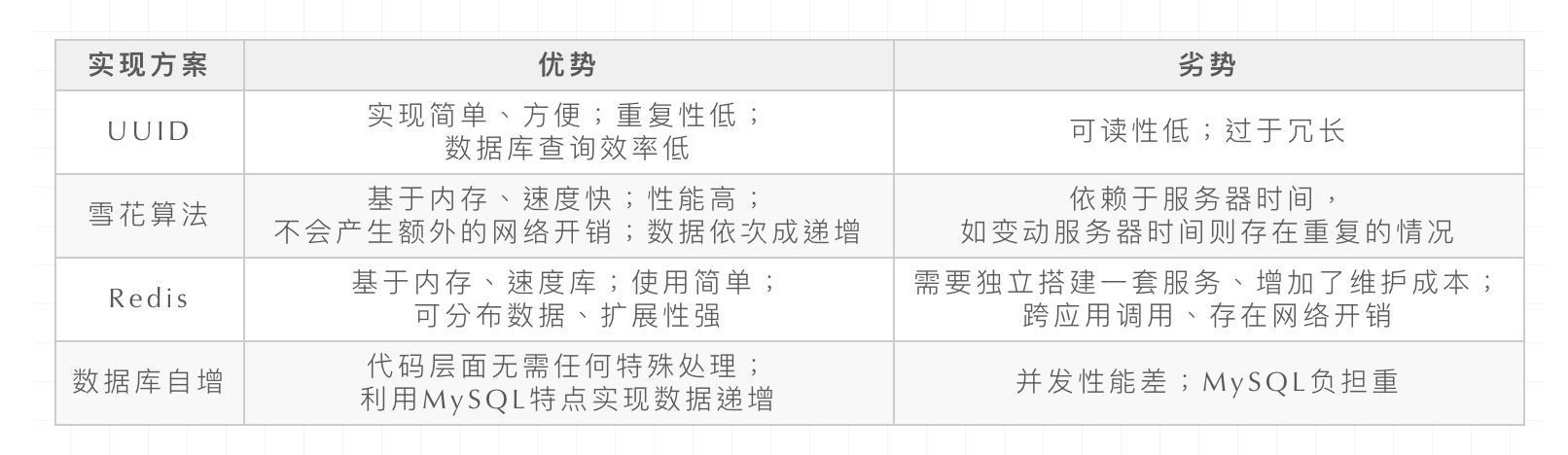
- 数据库表设计是否需要在字段前标注字段的所属对象,比如用户表的名字是 user_name,学校表的名字字段是 school_name
- 近期 1.2.4.8 DNS 出现大规模的 DNS 无响应
- 有人 idea 升级到 2021.1 遇到无法 import 的 bug 吗
- 唉,有点可怕,这开发者好像还在论坛的。还是官网下载的.....FinalShell.....
- Hangouts 环聊不能用了吗?发不出消息
- 一起来从 0 到 1 开发可视化搭建项目吧!
- RESTful API 设计最佳实践
- Sony 新机 Xperia 1 III 能否在 Android 阵营站起来?
- JetBrainsIDE 升级到 2021.1 大家有遇到 git 提交面板偶尔无法输入中文的情况吗?
- 最近个人抽空写的一个网页版的 SSH & SFTP 服务器连接工具,欢迎大家提建议(目前内测中)
- 移动端的未来是什么
- 有数据库建模和实际数据库同步的 数据库建模工具吗
- golang plugin mac 平台下交叉编译 生成 .so 文件 报错
- mongodb 查询返回 value 而不是返回 key:value
- Java 要不要转 .net 换个方向?大佬进来讨论下
- Android 有没有可以升降 key、加减速播放的音乐播放器?
- go 如何动态连接多个数据库
- 不懂就问:如何正确设计一个订单号?
- 如果有个 CRUD 工具会不会有兴趣用?
- stackoverflow 上看到一个问题,不是很理解。
- QQ 令 cpu 温度升高
- 对应届生来说客户端开发真的是劝退吗
- 图查询语言的历史回顾短文
- 谷歌的人机身份验证
- 公司 app 又被腾讯报毒了,有没人见过这情况,
- jboss, JavaEE 这套东西还有人用吗,值得投入太多精力下去吗
- IDEA 可以设置对某个单词高亮嘛
- [flag 回收][密码学]分组密码的工作模式
- 间隙锁的危害场景
- Foxmail 邮箱拖拽保存附件、右键另存附件的 MD5 不一致
- 在非 main 分支上使用 continuous deployment,真的好吗?
- 当有一个 PR 被 merged 到 A git repo 后,如何触发 B git repo 的 build,等等?
- amd mxgpu 云主机 安装了 win10 系统,安装 amd 官网驱动后,虚拟 GPU 没有成功驱动
- 为什么 leetCode 不能用 BigDecimal ?
- 系统二次验证大佬们有什么解决方案吗?
- 求大佬们推荐一个钉钉个人号的 API
- 如何使用 k8s 对外暴露 pods 的任意端口?
- 有什么方法可以取消在 Windows 里面 ctrl+鼠标滚轮 缩放的功能?
- Google 搜索这是发生甚么事了?
- 麻了, gdb 远程调试连不上
| Posted: 15 Apr 2021 04:33 AM PDT 包括但可能不限于 google 搜索、youtube,有时是其中一个阻断,有时是两个。直接 sorry,没有人机验证。同时被全球最大的搜索引擎和视频网站拒绝,这就很难受。 小心巨头。 |
| 数据库表设计是否需要在字段前标注字段的所属对象,比如用户表的名字是 user_name,学校表的名字字段是 school_name Posted: 15 Apr 2021 04:32 AM PDT 这样写法会不会过于冗余。 |
| Posted: 15 Apr 2021 04:31 AM PDT 前情提要 /t/770575 不知道为啥,其他国内 DNS 比如阿里腾讯都能解析的域名,该 DNS 无法解析 排查了一遍各种设备都没有问题,后来发现每次都是第一次响应解析失败、之后的响应几乎都能成功,第三次响应失败。想起 dnsmasq 一共配置了三个上游 DNS,第一个是 1.2.4.8,于是去 dig 了一下。 发现果然是 1.2.4.8 的问题。很多域名都无法解析了。更换上游 DNS 解决了这个问题。 顺便吐槽一下,为啥我前情提要的主题发在 Q&A 被移动到 Chrome 节点了,看的人都没有。 |
| 有人 idea 升级到 2021.1 遇到无法 import 的 bug 吗 Posted: 15 Apr 2021 04:31 AM PDT 如题,springboot 项目 idea 不能自动 import,即使我手动 import 了 idea 也爆红,但是项目是可以正常启动的。 |
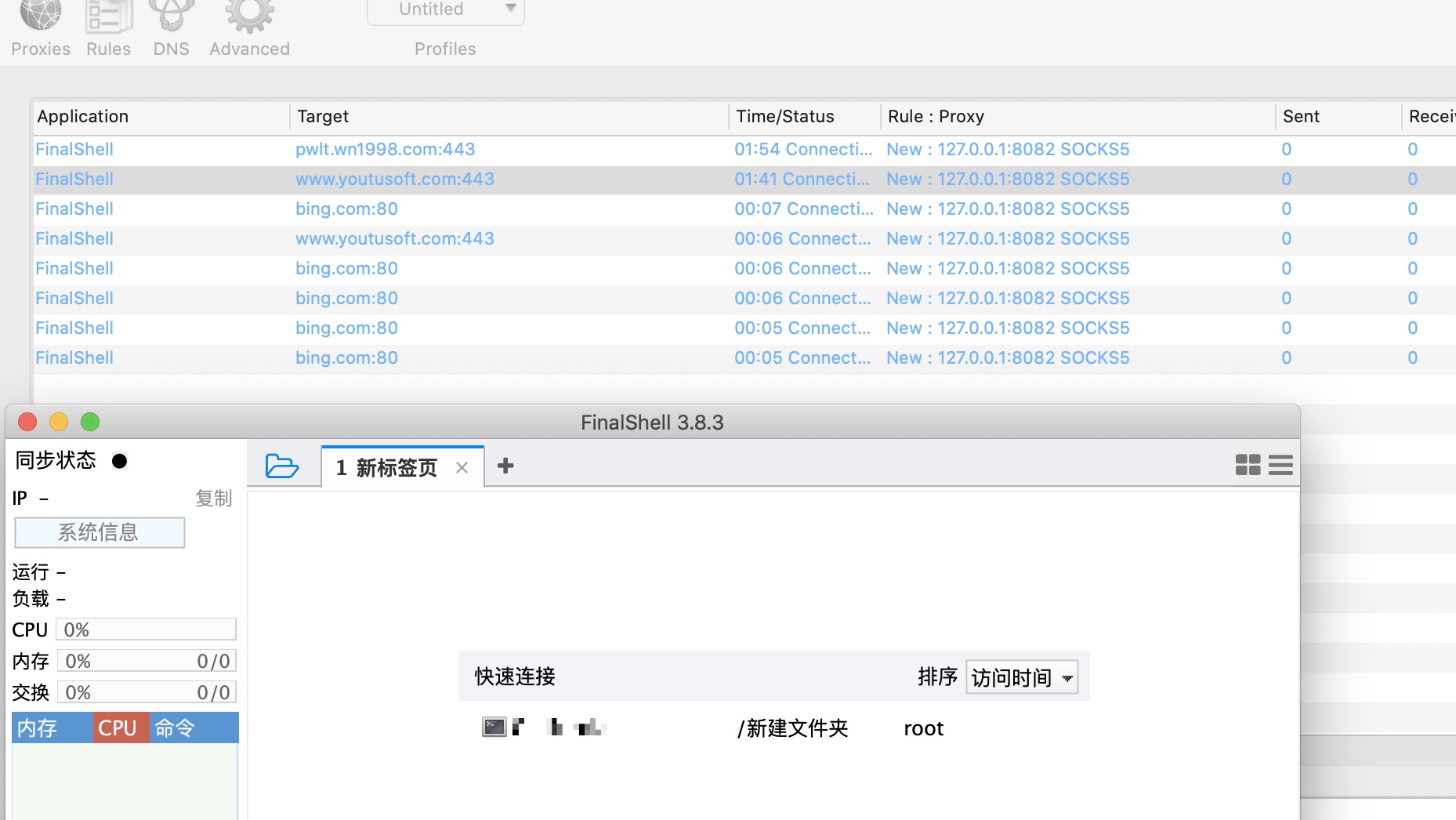
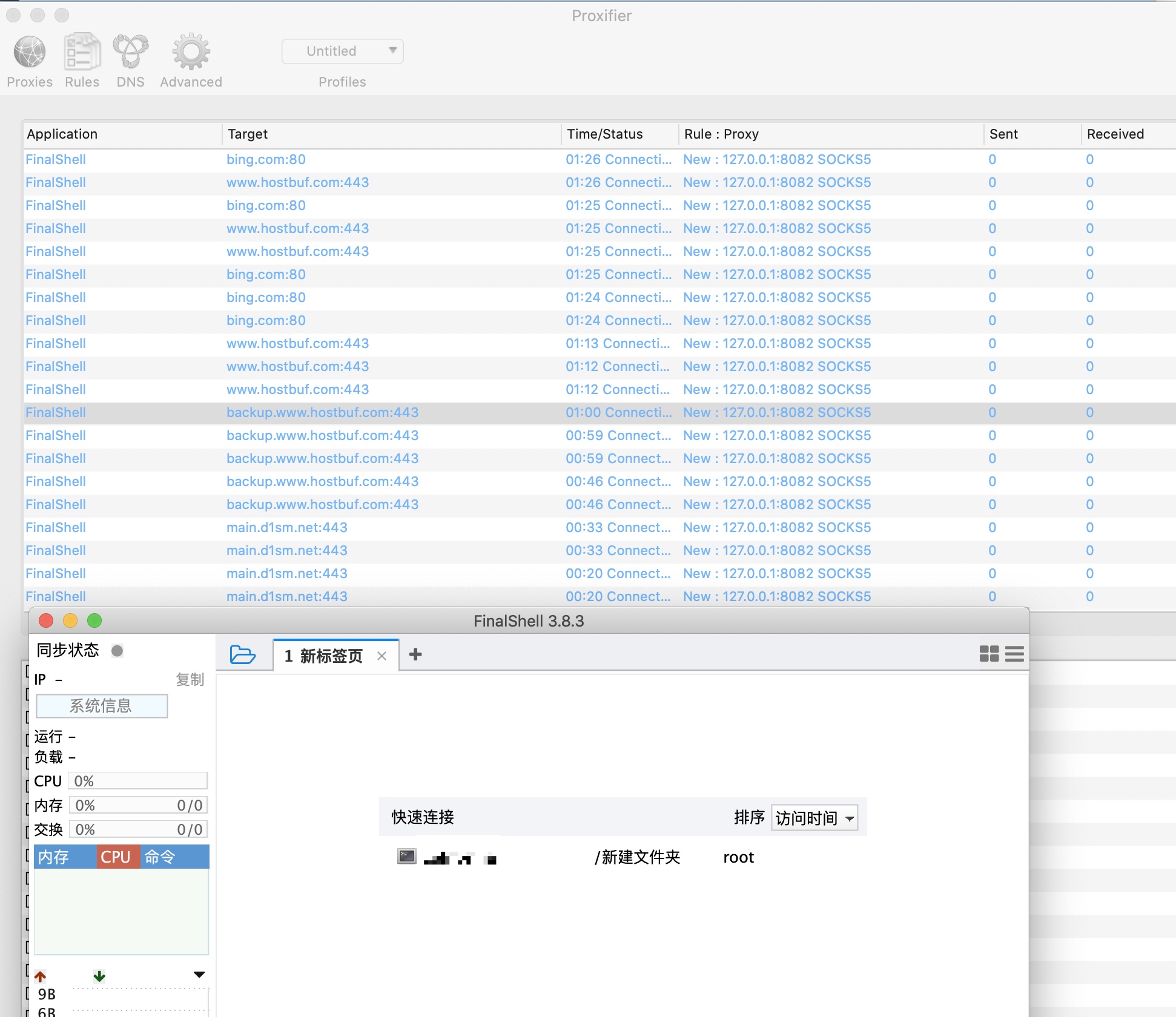
| 唉,有点可怕,这开发者好像还在论坛的。还是官网下载的.....FinalShell..... Posted: 15 Apr 2021 04:29 AM PDT 直接看图吧。。
官网下载。未登录账号。 打开工具后,首先访问官网:www.hostbuf.com/:443 ( ip: 101.32.72.254 ) 然后跟着访问 备份的域名: backup.www.hostbuf.com:443 (域名用了 cdn) 80 端口为 『免费内网穿透工具,无需公网 IP,无需设置路由器,100%穿透内网』 跟着访问 内网穿刺网站: main.d1sm.net/:443 ( ip: 101.32.72.254 ) 如果依然无网络,会访问 https://www.fcg51.com:443 其网站证书为:hostbuf.com 最后会访问 bing.com:80 ...... 那么问题来了,一个 Shell 管理工具,我刚打开,你就访问这么多东西.最后还访问 bing 。。 官网无备案,服务器在 HK,官网是三无产品。你是做啥的呢? |
| Posted: 15 Apr 2021 04:25 AM PDT Hangouts 环聊不能用了吗?发不出消息 会是下面这个样子 |
| Posted: 15 Apr 2021 04:23 AM PDT 前言笔者最近写了本关于可视化搭建方向的掘进小册,直接放链接: https://juejin.cn/book/6930553086918262798 同时为大家准备了 50 个 5 折 优惠码,数量有限,先到先 小册介绍在当下业务需求迭代飞快的互联网环境下,如何助力业务,为业务快速试错、迭代提供基础支持是不可规避的挑战之一。这其中最重要的一环就是"快"。有的时候为了满足业务诉求,我们不得不重复去开发一些活动页。所以你可能和我一样,非常想通过一款可以由运营自主组装页面的工具来自动生成页面,规避掉重复、无技术含量的劳动。 相比业界现状,不管在阿里还是腾讯等大厂都有适配自己内部业务诉求场景的一套可视化搭建体系。实现细节虽然有着出入但是核心思想都是希望把原本由开发人肉堆代码的活,通过可视化的方式表达给运营同学使用。或者通过 笔者希望借这本小册,一方面为没有接触过可视化搭建的同学提供一个解决问题的思路和方法。 另一方面本小册将会从背景到架构设计再到技术实现细节来一步步介绍如何落地一个围绕业务场景的可视化搭建需求。 作者介绍muwoo,前端攻城狮。之前在 51 信用卡 搞过一年的可视化搭建平台鲁班,半年内发布了 1000+ 活动页。后面辗转反侧去了蚂蚁集团,接触到内部的云凤蝶项目,对自己的可视化搭建理念产生了一定的影响。现在团队内也落地了一套可视化搭建体系,也是踩过了颇多的坑。 你可以在这里找到我 Github: https://github.com/muwoo 知乎: https://www.zhihu.com/people/monkey-wang- 小册目录
你会学到什么?
适宜人群
|
| Posted: 15 Apr 2021 04:21 AM PDT 本文首发于 刘星的个人网站 www.liuxing.io
简介RESTful API 是目前最流行的 API 设计规范,它用于 Web 数据接口的设计。它允许包括浏览器在内的各种客户端与服务器进行通信。因此正确是设计我们的 RESTful 是相当重要的!我们的 API 必须安全、高性能、同时易于使用。 在本文我们将探讨如何设计出易于使用并且安全快速的的 RESTful API 。 RESTful API 即是基于 Rest 构建的 API 。那么在开始之前,我们先来看看 REST 是什么? REST 与技术无关,它代表的是一种软件架构风格,REST 它是 Representational State Transfer 的简称,中文的含义是: 表现层状态转移(转移:通过 HTTP 动词实现)。即 URL 定位资源,HTTP 动词操作( GET,POST,PUT,DELETE )描述操作。 确保接受并响应 JSON 数据格式RESTful API 应该接受 JSON 格式的请求,并返回的响应体也应该是 JSON 格式的。JSON 是一种数据传输标准,主流编程语言几乎都能很好的支持它。同时在浏览器中我们的 JavaScript 也能很轻松方便的操作这些数据。所以,以 JSON 格式编写的 RESTful API 具有简单、易读、易用的特点。 为了确保当我们的 RESTful API 服务使用 JSON 格式响应,我们应该将其响应头的 让我们来看一个接收 JSON 数据并返回 JSON 数据的 API 示例。本示例使用 Node.js 的 Express 框架。我们使用了 body-parser 中间件来解析 JSON 请求体,然后使用 在本示例中 在 API 路径中使用名词代替动词RESTful API 是面向资源的 API,HTTP 动词操作( GET,POST,PUT,DELETE )描述操作。 我们不应该在 URL 路径中使用动词。我们应该使用要操作的实体的名词作为路径名。因为我们的 HTTP 请求方法本身就是动词,就能描述要进行的操作,如常见的方法包括 GET,POST,PUT 和 DELETE,这些请求方法即可完成 CRUD。
例如,我们有个文章(/articles/)资源。我们对其进行 CRUD 的 RESTful API 如下:
我们通过 Express 来实现上面这个增删改查的例子,如下所示: 在上面的示例代码中,我们定义了 API 来操作文章(articles)资源。如我们所见,API URL 路径中使用的都是名词,作为动词的请求方法说明了 API 的操作意图。 使用名词复数我们应该使用复数名词来命名集合。 通常,我们想要取得的数据都是一个集合,而不是单个项目。同时数据库中的表也是具有多个条目的。所以我们的 API 也应该使用复数名词,这样更合乎情理。 嵌套分层的资源对象在处理嵌套资源的 API 时,应该将嵌套资源附加到父资源的路径之后。 例如一个文章有评论列表,获取某个文章的评论列表的 API 则为: 我们可以使用 express 来做个示范: 使用标准的 http 状态码为了消除 API server 发生错误时用户的困惑,我们应该优雅地处理错误,并返回指示发生了具体错误的 HTTP 响应代码以及明确的错误信息。这可以很好的为 API 使用者提供了足够的信息来了解所发生的问题。 常见的错误 HTTP 状态代码包括:
我们应该抛出服务错误相对应的错误码。例如,如果我们要拒绝客服端发起的请求,则应在 Express API 中返回如下所示的 在上面的示例中,用户尝试创建一个已经存在的 user,将获得 400 响应状态代码,并带有一条 通常错误代码需要附带明确错误消息,以便用户有足够的信息来了解自己遇到了什么问题。 每当我们的 API 未成功调用时,都应通过发送明确的错误信息来帮助用户采取纠正措施来完成操作。 添加过滤,排序和分页功能通常我们的数据都会非常庞大。我们不可能一次全部返回,这会非常慢也可能导致系统崩溃。因此,我们需要有过滤,分页数据的方式。过滤和分页都可以通过减少消耗服务器资源来提高性能。这些功能相当基础且重要。 分页、过滤、排序查询都功能都应该使用查询参数来实现。如: 下面这就是一个带有过滤查询的示例: 保持良好的安全意识客户端和服务器之间的大多数通信应该是私有的。因此,必须使用 SSL/TLS 进行安全保护。现在加载 SSL 成本是相当低的。我们没有理由不使用它。 同时,不同的用户具有不同的数据访问权限。例如,普通用户不应该能够访问其他用户的信息。他们也不应该能够访问管理员的数据。 适当缓存数据以提高性能可以适当添加缓存服务,从缓存中返回常用数据,而不是每次都从数据库去读取。缓存的好处是可以更快地获取数据,但是也让我们获取最新的数据变得复杂。缓存方式有很多如:Redis 、内存缓存( in-memory cache)等等,我们应该根据自己的应用具体情况来选择是不是该用缓存,使用哪种缓存机制。 这儿我们来使用 Express 的apicache中间件来实现一个简单的内存缓存: 版本化我们的 API原则上我们应该尽量让 API 避免破坏性变更,保持向后兼容。但是经常有些时候破坏性的变更是不可避免的,这时版本化的 API 就派上用场了。当我们发布了不兼容或重大更改变,则可以将其发布在新版本中的 API 。 我们通常通过 URL 来实现版本化,及添加版本号在我们 API 路径的开头,例如: 我们可以在 express 很简单的实现版本化的 RESTful API: 总结设计高质量 RESTful API 的最重要的一点是遵循 Web 标准和约定以保持一致性。JSON 、SSL/TLS 和 HTTP 状态代码都是现代 Web 的标准。性能也是重要的考虑因素。我们可以使用分页、缓存等手段来提升性能。可维护性可扩展性也是我们需要考虑的。 更多推荐本文完 欢迎可以关注我的公众号,一起玩耍。有技术干货也有扯淡乱谈 左手代码右手砖,抛砖引玉 |
| Sony 新机 Xperia 1 III 能否在 Android 阵营站起来? Posted: 15 Apr 2021 04:19 AM PDT 6.5 吋 21:9 CinemaWide™ 4K HDR OLED 120Hz 刷新率 |
| JetBrainsIDE 升级到 2021.1 大家有遇到 git 提交面板偶尔无法输入中文的情况吗? Posted: 15 Apr 2021 04:16 AM PDT 前两天升级 WebStorm 到 2021.1,发现 git 提交的时候偶尔会无法输入中文,微软拼音,百度输入法在这个面板都默认是英文的状态,无法切换到中文。但是在代码面板又是正常的。 |
| 最近个人抽空写的一个网页版的 SSH & SFTP 服务器连接工具,欢迎大家提建议(目前内测中) Posted: 15 Apr 2021 03:55 AM PDT 目前是测试版本,暂时只支持密码连接 关于密码存储安全
欢迎大家提建议和需求!!! 下面是一些截图
|
| Posted: 15 Apr 2021 03:53 AM PDT 前几年还在鼓吹大前端,最近 rn, weex 都凉了,flutter 目测也快了,跨平台真的是昙花一现的伪需求吗,移动端的未来是什么? |
| Posted: 15 Apr 2021 03:48 AM PDT pdm 很好用,但是每次字段改动都要两边同步 |
| golang plugin mac 平台下交叉编译 生成 .so 文件 报错 Posted: 15 Apr 2021 03:41 AM PDT |
| mongodb 查询返回 value 而不是返回 key:value Posted: 15 Apr 2021 03:36 AM PDT 问一下,mongodb 支持只返回 value,而不是返回 key:value 这样子格式的吗? 比如下面的表
但我希望返回的直接是 目前我查阅的资料都是不支持的,有没有人有其他的操作
我希望可以返回的是关于 age 的列表,比如{ age:[25,26,...] } 或者直接是[25,26,...] 这个可以实现嘛?还是只能从上面的结果进行处理生成数组
目前我使用 spring-boot-starter-data-mongodb 操作 mongodb 的,主要使用 MongoTemplate 我想了解下 MongoTemplate 有没有对其封装有实现上面两个需求的,目前我看文档也是没有找到 没有的话是不是只能查询出 List<User>,再编历读取构建 age 的数组了
|
| Posted: 15 Apr 2021 03:12 AM PDT 二胖菜鸡一枚,在运营商业务某公司做 JAVA,主要一些内部系统,偏维护类。现在拿到某家制造业厂岗位.net 语言,降薪三千。目前工作这家公司涨薪很少 [听说需要自己和老板提] ,且是办事处,人数 100 左右。早九晚 7+,基本双休。厂里面 8.30 55,如果加班平日两倍,节假日三倍,目前看是按年涨薪 7%-11%。且后续厂离家近,3 公里内,现在这家离家大约 20 公里。 厂 15-16 薪,当前这家 13-14 。有大手子知道怎么选不,或者怎么合适?大厂太菜本人进不去。工作 5 年快到,都是没啥技术,想转型了。 |
| Android 有没有可以升降 key、加减速播放的音乐播放器? Posted: 15 Apr 2021 03:05 AM PDT |
| Posted: 15 Apr 2021 02:36 AM PDT 项目背景:需要实现的功能:尝试与疑问:备注:
|
| Posted: 15 Apr 2021 02:31 AM PDT |
| Posted: 15 Apr 2021 02:15 AM PDT 公司自研一款基于 Mybatis-Generator 的 CRUD 代码生成工具,能够自动生成 Controller-Business-Service-Mapper 四层。生成各层的出入参数和转换类(基于 JSON )。 使用下来非常快,CRUD 几乎不用再添加新代码。 大多数 Java 程序员开发工作避免不了 CRUD,故打算花些时间开源,不知道会不会有人用以及是否有类似的开源产品。 约定数据库表结果必有 ID/DELETED/CREATED_AT/CREATED_BY/MODIFIED_AT/MODIFIED_BY 6 个字段,且 DELETED 字段类型同 ID 字段( bigint ),deleted=0 表示未删除,deleted=id 值表示删除。 PS:尝试过 Mybatis-Plus 和 单纯 Mybatis-Generetor,还是要写部分代码。 PPS:分层模型各有各的习惯和说法,但用 CRUD 工具后基本不在有争论,无形消弭。 |
| Posted: 15 Apr 2021 01:57 AM PDT 为什么执行的是父类方法?如果父类改为非箭头函数,又是执行子类方法。 |
| Posted: 15 Apr 2021 01:38 AM PDT 最近使用 QQ,发现只要打开 QQ,cpu 就会上升,相对的温度也会升高.每次打开 QQ,我那个风扇就会乌拉乌拉的响.这 QQ 是干了什么 |
| Posted: 15 Apr 2021 01:04 AM PDT 目前只收到腾讯 pcg 的 ios 开发 offer,但也知道现在很多人在劝退,想看看大家怎么说 |
| Posted: 15 Apr 2021 01:02 AM PDT
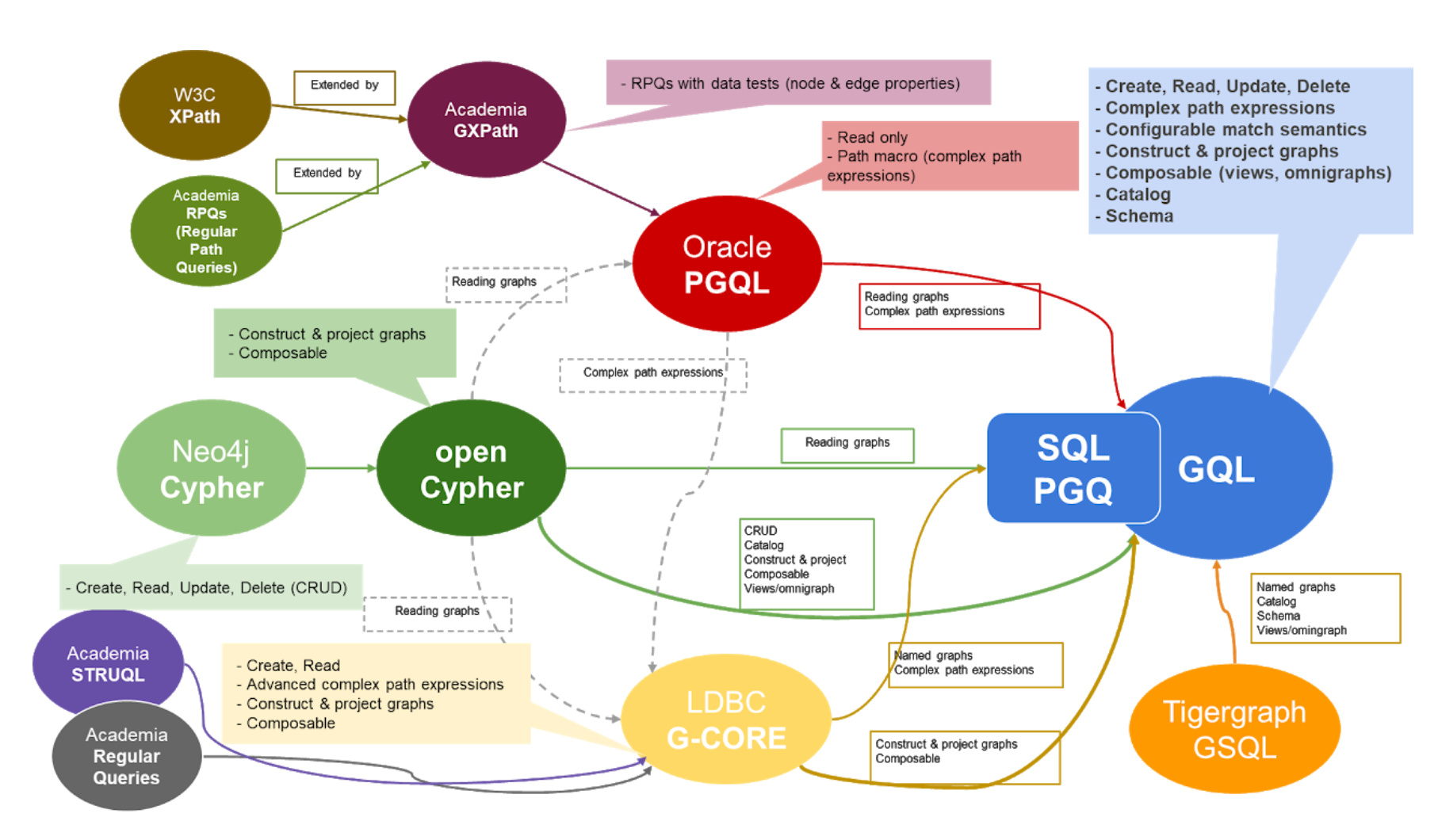
本文首发于 Nebula 公众号:图查询语言的历史回顾短文 前言最近在对图查询语言 GQL 和国际标准草案做个梳理,调研过程中找到下面这篇 mark 了没细看的旧文(毕竟收藏就是看过)。做个简单的记录。 摘要本短文会涉及到的图查询语言有 Cypher 、Gremlin 、PGQL 和 G-CORE 。 背景本文主要摘录翻译自 [Tobias2018] (见参考文献),并未涉及到 SPARQL 和 RDF,只讨论了属性图。 文章撰写的时间是 2018 年,可以看做 GQL ( Graph Query Language )的一些前期准备。GQL 有多个相关的起源,参见下面这张图。
因为 Cypher 的历史和 Neo4j 紧密相关,本文会提一些 Neo4j 早期的历史。[Angles2008](见参考文献)和 [Wood2012](见参考文献)是两个不错的关于图模型和图查询语言的总结。 年表简述
Gremlin 、Cypher 、PGQL 和 G-CORE 的演进Neo4j 的早期历史Neo4j 和属性图这种数据模型,最早构想于 2000 年。Neo4j 的创始人们当时在开发一个媒体管理系统,所使用的数据库的 schema 经常会发生重大变化。为了支持这种灵活性,Neo4j 的联合创始人 Peter Neubauer,受 Informix Cocoon 的启发,希望将系统建模为一些概念相互连接的网络。印度理工学院孟买分校的一群研究生们实现了最早的原型。Neo4j 的联合创始人 Emil Eifrém 和这些学生们花了一周的时间,将 Peter 最初的想法扩展成为这样一个模型:节点通过关系连接,key-value 作为节点和关系的属性。这群人开发了一个 Java API 来和这种数据模型交互,并在关系型数据库之上实现了一个抽象层。 虽然这种网络模型极大的提高了生产力,但是性能一直很差。所以 Neo4j 联合创始人 Johan Svensson 花精力,为这种网络模型实现了一个原生的数据管理系统。这个就成为了 Neo4j 。 在最初的几年,Neo4j 作为一个内部产品很成功。在 2007 年,Neo4j 的知识产权转移给了一家独立的数据库公司。 Neo4j 的第一个公开发行版中,数据模型由节点和有类型的边构成,节点和边都有 key-value 组成的属性。Neo4j 的早期版本没有任何的索引,应用程序只能从根节点开始自己构造查询结构( search structure )。因为这样对于应用程序非常笨重,Neo4j 2.0 ( 2013 年 12 月发布)引入了一个新概念——点上的标签( label )。基于点标签,Neo4j 可以为一些预定义的节点属性建立索引。 节点、关系、属性、关系只能有一个标签、节点可以有零个或者多个标签,以上这些构成了 Neo4j 属性图的数据模型定义。后来增加的索引功能,让 Cypher 成为了与 Neo4j 交互的主要方式。因为这样应用开发者只需要关注于数据本身,而不是上段提到的那个开发者自己构建的查询结构( search structure )。
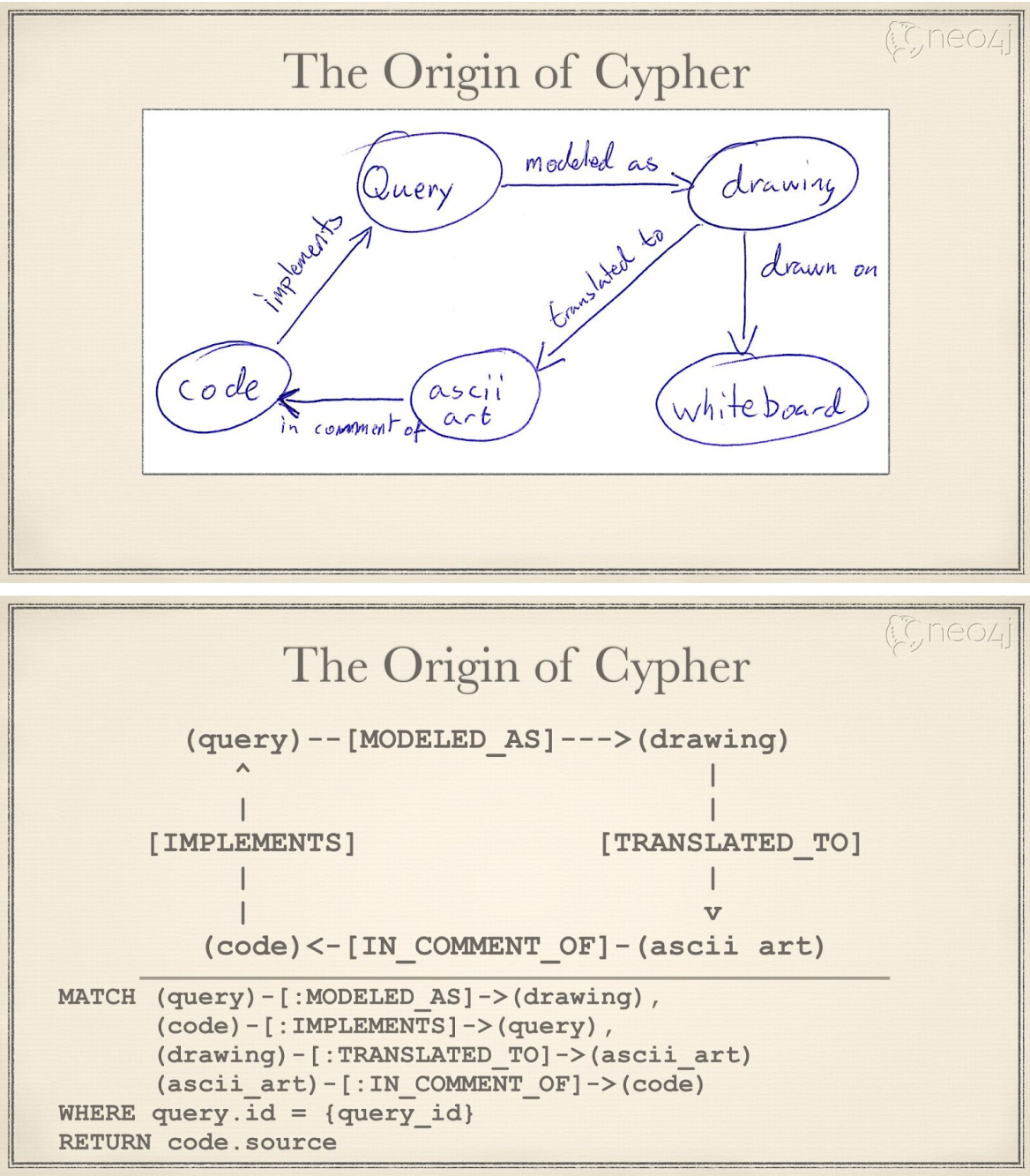
Gremlin 的创造最初与 Neo4j 的查询方式是通过 Java API 。应用程序可以将查询引擎作为库嵌入到应用程序中,然后使用 API 查询图。如果是自定义查询引擎,然后应用程序远程访问服务器,这样就比较困难。 就在这段时间,NOSQL 这个概念开始出现。NOSQL 型的数据库引擎一般用 REST 和 HTTP 来交互和查询。Neo4j 的早期员工 Tobias Lindaaker (和 Ivarsson )考虑用 HTTP 的方式访问 Neo4j 会是一种更好的办法。他们观察到很多的查询语句可以表达为:图到树的投影映射( projection )。典型的,从根节点开始遍历一个扩张树( spanning tree ),然后返回叶子节点。基于这样的观察,并参考一些树结构的查询语句,比如 XPath,也许可以作为一种图的查询方式。而且,XPath 的语法和一般 URI 的语法很像。这样 XPath 查询可以很自然的作为 HTTP GET 中 URI 的一部分。Neo4j 的联合创始人 Peter Neubauer 喜欢这个想法,找了一个朋友 Marko Rodriguez 来干。两天后,Marko 做了一个原型,用 XPath 作为图查询,Groovy 提供循环结构,分支,和计算。 这个就是 Gremlin 最初的原型。2009 年 11 月发布了第一个版本。 后来,Marko 发现同时用两种不同的解析器( XPath 和 Groovy )有很多问题,就将 Gremlin 改为基于 Groovy 的一种内置的领域特定语言( DSL )。 Cypher 的创造Gremlin 和 Neo4j 的 Java API 一样,最初用于表达如何查询数据库的一种过程( Procedural )。它允许更短的语法来表达查询,也允许通过网络远程访问数据库。Gremlin 这种过程式的特性,需要用户知道如何采用最好的办法查询结果,这样对于应用程序开发人员来说仍旧有负担。基于声明式语言 SQL 的成功:SQL 可以将获取数据的声明方式和引擎如何获取数据分开,Neo4j 的工程师们希望开发一种声明式的图查询语言。 2010 年,Andrés Taylor 作为工程师加入 Neo4j,在此之前他是 SQL DBA 。他开始了一个项目,受 SQL 启发,其目标是开发图查询语言,而这种新语言 Cypher 于 2011 年 Neo4j 1.4 发布。 Cypher 的语法基础,是用 "ascii 艺术(ascii art)" 来描述图模式。这种方式最初来源于 Neo4j 工程师团队在源代码中评注如何描述图模式。可以看下图的例子:
Cypher 第一个版本实现了对图的读取,但是需要用户说明从哪些节点开始查询。只有从这些节点开始,才可以支持图的模式匹配。
在后面的版本,2012 年 10 月发布的 Neo4j 1.8 中,Cypher 增加了修改图的能力。但查询还是需要指明从哪些节点开始。 2013 年 12 月,Neo4j 2.0 引入了 label 的概念,label 本质上是个索引。这样,查询引擎就可以利用索引,来选择模式所匹配到的节点,而不需要用户指定开始查询的节点。
随着 Neo4j 的普及,Cypher 有着广泛的开发者群体 ,和各行各业的使用。
openCypher - 一种推进和标准化 Cypher 的开源过程2015 年 9 月,Neo4j 开放了 Cypher 查询语言,通过开源的方式来治理。这个新主体的治理主体是 openCypher Implementors Group ( oCIG )。 2016 年,openCypher 项目发布 EBNF 和 ANTLR4,Neo4j 也贡献了很多基于 Apache 2.0 的语言功能测试集( openCypher Technology Compatibility Kit, TCK )。将这些作为语言标准定义,任何人都可以为该语言提交新的提议。2016 年,SAP HANA Graph 发布了基于 Cypher 的查询部分的实现,Agens Graph 和 Redis Graph 在 2017 年支持了 Cypher 。2017 年 oCIG 也进行了一系列线上线下的会议,讨论语言功能扩展等。
oCIG 发布 openCypher,采用英语语言作为规范,对应了 Neo4j 3.3.0 版本中的 Cypher 。 PGQL 的创建2015 年,Oracle 为 PGX 引擎开发了图查询语言 PGQL 。PGQL 受 Cypher 的启发,也和 Cypher 很接近。 G-CORE 的创建Linked Data Benchmarking Council ( LDBC )定义了一种厂商无关的基准测试。在开发这个基准测试的过程中,他们发现市面上没有标准的查询语言来表达图查询。为了处理这个问题,成立了一个特别工作组,调研市面上已经存在的图查询语言和框架,定义图查询必须的功能,然后为现有语言提供修改建议。 2016 年,他们想设计一种新语言,而不是对于现有语言的修改。主要原因是不想受现有语言的模型的限制。 G-CORE 是由 LDBC 工作组设计的,但主要受 Cypher 的启发,采用一样的语义。 结论Cypher 是 PGQL 和 G-CORE 的共同祖先。这几个语言的语法和语义都非常的接近。PGQL 更接近一些早期的 Cypher,而 G-CORE 更期望语法和语义上都与 Cypher 兼容。 一些个人看法除去学术上的探索和一些零散的工程尝试,以 Cypher 作为主流属性图查询语言工程实践的历史基准,也就 10 年的时间。在前面的几年 2010-2013,Cypher 自身在基础图功能上还有不少缺失,比如索引、图模式,迭代到 2014 年才产生当前使用的一个主流版本,并且还在持续演化 [Nadime2018](见参考文献部分)。 重头全新设计一种图语言其实很难,很可能会把前人走过的路(坑)再走(掉)一遍( G-CORE 和 nGQL )。这是 GQL 第一个不容易的地方。 一个标准化组织中,有学术和商业机构,各自诉求也很不相同,商业机构已经各自有庞大的商业使用群体,这是第二个不容易的地方。 制定完的标准,最后是否会被市场所接受和采纳( vendor 、custormer 、developer 、goverment ),又需要多少的布道。这是 GQL 第三个不容易的地方。 除了核心基础的图操作以外的特性,比如 SQL 、pregel [Grzegorz2010](见参考文献部分)、GNN,每个语言 PGQL 、GSQL 甚至 Neo4j 自己都各自采用了完全不同的方式来支持这些特性,要不要考虑这些新出现的特性。这是 GQL 第四个不容易的地方。 再想想 GQL 和 Apache Tinkerpop/Gremlin 这两条完全不同的路,这是一个变化很快的时代,计算机又是一个更强调 de facto 标准的行业,GQL 并不容易。(打脸) 参考文献
交流图数据库技术?加入 Nebula 交流群请先填写下你的 Nebulae 名片,Nebula 小助手会拉你进群~~ 查看大厂实践案例?Follow Nebula 公众号:NebulaGraphCommunity 回复「 PPT 」掌握 [美团的图数据库系统] 、 [微众银行的数据治理方案] 以及其他大厂的风控、知识图谱实践。 推荐阅读 |
| Posted: 15 Apr 2021 12:39 AM PDT 想问下用过的 V 友们,这个是收费还是免费的? |
| Posted: 15 Apr 2021 12:11 AM PDT 几个月前公司 app 被腾讯报毒导致各种手机警告和平台下架,病毒详情说是有人举报欺诈, 而今天,新签名的 app 又被腾讯报毒了,这次理由更离谱, 这个"该软件可能不是您所需要的应用"看起来就像是新签名被识别成了盗版似的, 关键是搜都搜不到这案例,有没大佬支个招, |
| jboss, JavaEE 这套东西还有人用吗,值得投入太多精力下去吗 Posted: 14 Apr 2021 11:57 PM PDT 最近做一个单点登录项目,打算用 cas 或者 keycloak 二次开发。cas 用的是 spring 做的,我比较熟,但文档质量,功能都不如 keycloak 。问题是甲骨文早就弃坑,javaee 改名 jarkataee,甩给 eclipse 基金会,jboss 也改名 wildfly 。关键是这套过时玩意要学还要投入不少精力学习,以后想跳槽互联网公司这些经验有用吗 |
| Posted: 14 Apr 2021 10:20 PM PDT 2020.3.3 社区版... 可以设置如果代码里出现某个单词,那个单词高亮吗? 插件是可以实现...但是仅仅想要高亮某个单词,再搞个插件就太累了... 比如出现代码里面出现 Apple,那就 Apple 高亮 就和 todo 高亮那个效果似的。 |
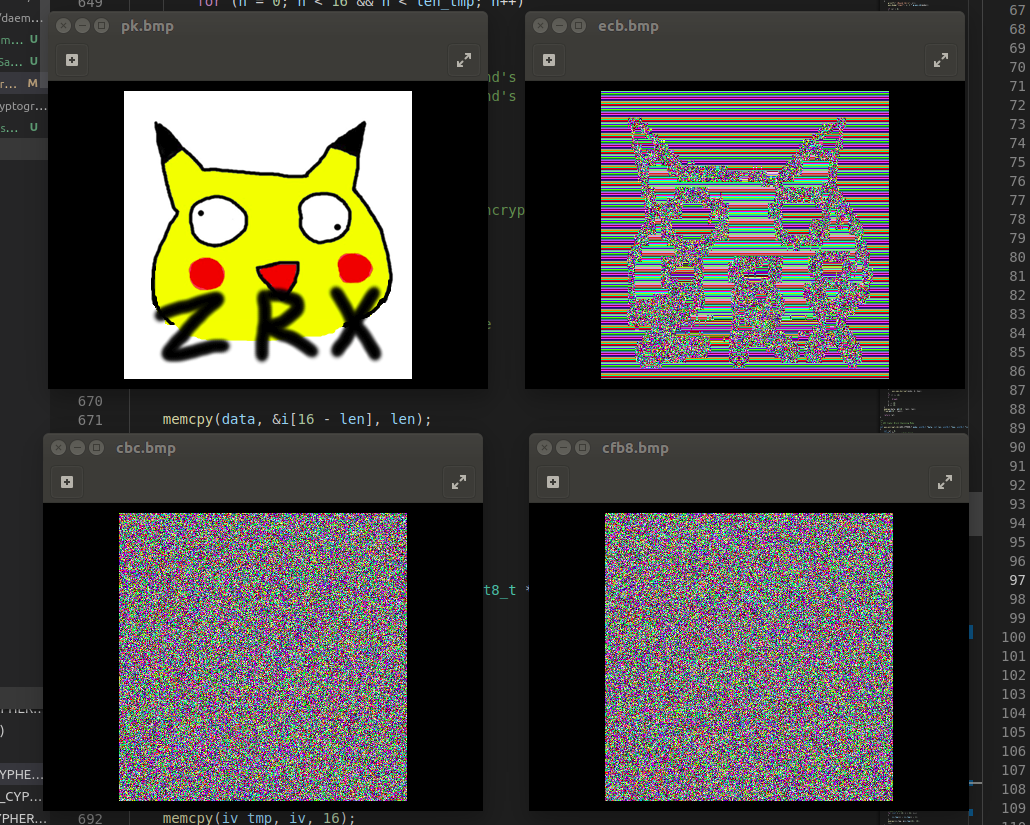
| Posted: 14 Apr 2021 09:53 PM PDT 当然,这是一个老生常谈的话题。之前在 v 站发过一篇关于 AES 原理的文章,当时就想通过图像的方式体现不同分组模式对明文结构产生的影响,以前上密码学实验课的时候也觉得缺少这么一个东西来直观对比模式之间的差别。可惜实在忙不过来,拖更一年终于填上,也顺手改了之前文章的一些错误。
⬆️像这个样子 这篇文章基于 NIST 800-38A 描述,因为也是 AES 复习系列,就特定了 AES 作为 underlying algorithm,自己大致实现了几个模式的主要代码以及用来做 bitmap 的脚本。<del>有时间重构一把</del> 写完自己扫了几遍。。文中的错误还请带佬们不吝指教_(:3 」∠ )_ |
| Posted: 14 Apr 2021 09:41 PM PDT 发生间隙锁危害的生产业务场景,能否说一说? |
| Foxmail 邮箱拖拽保存附件、右键另存附件的 MD5 不一致 Posted: 14 Apr 2021 09:40 PM PDT Foxmail 邮箱 Win 客户端拖拽保存附件、右键另存附件 MD5 不一致,客户端版本 7.2.20.259 。 右键另存的附件是原档,拖拽保存的附件 MD5 和原档不一致,且大概率导致 pdf 文件签名失效、有时导致 rar 文件 unexpected end of archive,这两个操作有什么区别? |
| 在非 main 分支上使用 continuous deployment,真的好吗? Posted: 14 Apr 2021 09:07 PM PDT |
| 当有一个 PR 被 merged 到 A git repo 后,如何触发 B git repo 的 build,等等? Posted: 14 Apr 2021 08:12 PM PDT 如题,现在有两个 git repo A & B A 主要是代码管理, B 则是相关的一些其它的,比如,打包,或者代码扫描等等。 我们使用 Jenkins 去管理任务 /jobs 现在希望 A 上面,当有一个 PR 被 merge 后,能够自动触发 B 上面的 job 有什么方法? hook ?还是 git actions? 有没有相关的介绍或者例子? 谢谢! |
| amd mxgpu 云主机 安装了 win10 系统,安装 amd 官网驱动后,虚拟 GPU 没有成功驱动 Posted: 14 Apr 2021 06:54 PM PDT 显卡:AMD FirePro S7150 加载开源 gim 模块后进行显卡切分,然后应用了 vfio 驱动透传给云主机 KVM 下 win10 1809 + AMD MXGPU(S7150V) 驱动安装后显卡驱动失败, 设备管理器显示 code 43 |
| Posted: 14 Apr 2021 02:22 PM PDT 编译失败 |
| Posted: 14 Apr 2021 01:48 PM PDT 系统二次验证大佬们有什么解决方案吗? 比如 OA 系统这种看到某些特定界面的时候要求二次验证用户身份才能进行访问这种的. |
| Posted: 14 Apr 2021 12:28 PM PDT 微信个人号 API 很多,但是钉钉的貌似木有啊 语言不限,Python 最佳~ |
| Posted: 14 Apr 2021 11:39 AM PDT 如何使用 k8s 在 对外暴露 pods 的任意端口? 现在想实现使用 self host kubernetes 的code-server进行 web preview,现在的用法是使用 yaml 文件里面写 services 和 ingress 进行暴露,但是 ports 是写死的,如果要打开新的端口就需要重新修改 ymal 。搜了半天也没找到办法,希望 v2 的大佬们指点一下。 example yaml: 期望实现: 比如说 gitpod.io 的 preview 就是根据需求打开端口 复现过程:
我想请教请教这个过程是如何实现的? ps:感觉是使用了什么神奇的 ingress controller,不知道有没有开源产品 |
| 有什么方法可以取消在 Windows 里面 ctrl+鼠标滚轮 缩放的功能? Posted: 14 Apr 2021 10:09 AM PDT 例如在浏览器里面会缩放页面,在桌面会缩放桌面图标。 因为在 mac 里用习惯了,在 Windows 里面讲 alt 和 ctrl 键位互换做了调整,左手大拇指习惯搭在换位后的"ctrl"键上,导致经常一不小心就把页面大小给缩放了,很是烦恼。 |
| Posted: 14 Apr 2021 07:50 AM PDT 怎么不是居中了? 佐田还是正常的,也没动它啊? |
| Posted: 14 Apr 2021 07:11 AM PDT 我有个 centos8 远程主机,ip 地址是学校分配的公网地址,在学校的教育网范围内可以任意访问,最近使用这个东西来远程调试 C++代码,发现 gdb 一直都连不上。 服务器端端开启 gdbserver 的命令和结果如下: 然后我从 MacOS BigSur 上用 gdb 命令来连接,结果如下: 简而言之就是死活都连不上去。但是奇怪的是我 ssh 可以连接到远程主机,而且使用远程主机上的 gdb 就可以连接上开启的 gdbserver 。如下是 ssh 到远程主机后,执行 gdb 调试的结果: 有没有大佬碰到过这种情况呀,一个人整了大半天,实在是整不明白。 |






{kind=link}
| You are subscribed to email updates from V2EX - 技术. To stop receiving these emails, you may unsubscribe now. | Email delivery powered by Google |
| Google, 1600 Amphitheatre Parkway, Mountain View, CA 94043, United States | |
No comments:
Post a Comment