V2EX - 技术 |
- 请问 类似 B 站这样的 大网站 他们关注模块是怎么设计的?
- 大家有有搭建过旁路由的吗?可以实现流量管理,限制 IP 等功能吗?有什么推荐方案?
- 坐标上海 stackoverflow 503 了
- 关于前端代码逻辑的保护, sablejs 你值得拥有
- 大家平时在家里是如何各个电脑以及移动设备之间共享文档、视频等的
- 各位前辈,可以分享一下前端在中小厂的生存现状吗?
- Android Socket 通信网问题
- 接口接收稿件数据批量入库,接口和数据库(类似 hbase)之间用什么做中转比较好
- GMail 批量导出为 EML
- windows 下用 powershell 和用 cmd 运行 Python 有什么区别吗
- Go timer 是如何被调度的?
- 你们用 get/set 吗?
- Xcode 13 adds Vim mode
- emm.目前团队缺少一些小伙伴,欢迎关注,团队偶尔佛系偶尔鸡血!
- 关于笔记本 Linux 上的双显示器
- 推上看到的一道题
- 问个 ceph pg 的问题
- Linux 上有没有这样一种“写时复制”的文件系统或者工具?
- 如何处理多副本下的状态管理?
- 有没有人有空能接一些单子
- pam- Python 的 Python 解释器是哪里设置的,可以设置其他解释器吗?
- windows 的 remote desktop connection 有没有办法,在全屏的时候,使用键盘切换回原 windows?
- 平铺桌面 awesome 配置
- Titanium Backup 跟安卓 11 不兼容吗?明明给了 root 却说拿不到 root 权限
- Apple 规定同一个身份证只能注册一个开发者账号,如果我之前用的一个苹果开发账号过期后不续费,多久后可以用另一个 Apple ID 申请开发账号?
- IPTABLES UDP 端口转发疑惑
| 请问 类似 B 站这样的 大网站 他们关注模块是怎么设计的? Posted: 08 Jun 2021 05:28 AM PDT 这样的大网站 他们的关注列表数据量肯定非常大 , 那他们是怎么存储呢? 是 NOSQL 吗? 有哪些选型? |
| 大家有有搭建过旁路由的吗?可以实现流量管理,限制 IP 等功能吗?有什么推荐方案? Posted: 08 Jun 2021 04:56 AM PDT |
| Posted: 08 Jun 2021 04:53 AM PDT 看了下不止上海。 |
| Posted: 08 Jun 2021 04:53 AM PDT 如果按照提升破解成本的目标,自定义字节码执行是一条很靠谱的路径,有需要的可以参考: https://github.com/sablejs/sablejs |
| 大家平时在家里是如何各个电脑以及移动设备之间共享文档、视频等的 Posted: 08 Jun 2021 04:38 AM PDT 目前自己有两台电脑两台手机,比如有时候在电脑上的视频,想躺在床上看,总不能每次都把视频 down 到手机里看把 还有就是 mac 跟 win 之间文件,虽然可以通过搭个 ftp 服务或者 Samba 这种直接共享文件夹的方式查看,但是移动端就没法直接访问了,不还得用个简易的文件浏览器,各端也不统一 还有就是两三台电脑的时候,有时候感觉文件散乱,是时候想在家搞个既可以存储、备份文件又可以随时随地,只要连上了家里的网络,就能查看文件 有没有类似实现了功能的软件,如果没有的话,自己搞个是不是挺好的(虽然工作量挺大的)。查看的话,我感觉初版可以通过网页输出,因为基本上大部分文件现在的网页都支持 |
| Posted: 08 Jun 2021 04:35 AM PDT 不好意思,可能前几天创建了一个有点相似的主题,见谅。这次更清楚自己想问的问题了,各位互联网的前辈们,可以分享一下在你们公司里前端的地位吗?比如话语权,职位晋升,前端和后端的比例之类的吗?感谢各位的回复。 |
| Posted: 08 Jun 2021 04:34 AM PDT 我想直接实现两个 Android 客户端之间的大量的消息通信,直接使用 Socket 连接,我知道是可以的。 我有两个问题
Any Suggestion will help!高通信量之间的直接使用 Android socket 端口,会不会无法满足高通信量? |
| 接口接收稿件数据批量入库,接口和数据库(类似 hbase)之间用什么做中转比较好 Posted: 08 Jun 2021 04:09 AM PDT 目前有个需求是提供一个稿件的入库接口,然后入到一个闭源的类似 hbase 的数据库中,由于某些原因,接口和入库过程要解耦,所以需要中转一下,一种方案是接口端把 json 写入文件,logstash 读取,然后 output 输出到一个 http 接口,然后入库。另一种是接口把稿件数据扔到 kafka 里,然后接口端拉数据入库。 总体量大概一天 1~2w 篇,不算大,但是字段比较多,正文会大一点。领导要求尽量保证数据不丢失。 感觉走 logstash,如果 output 对应的接口挂掉,容易大量重试,比较麻烦。然后走消息队列,感觉作为消息体似乎有点大,而且不知道会不会被撑爆导致里面数据丢失(做持久化可解决?) 想求教一下,哪种方案合适一点,或者说有啥更合适的方案更好。 谢谢诸位。 |
| Posted: 08 Jun 2021 04:02 AM PDT 请问有没有什么办法可以把 Gmail 邮箱中的邮件批量导出为 EML 格式的文件保存在本地啊。 在 Gmail 查看单个邮件的,在右上角的三个点里面有个下载邮件,下载出来时 eml 文件,但是只能下载这一个。通过 Google takeout 功能的话,可以批量导出,但是导出格式是 mbox,所有邮件合并为一个 mbox 文件。这个格式需要专门的 mbox 查看软件打开,一般的邮箱客户端好像不行,我下载了一个叫 MboxViewer 的软件查看,发现里面有很多内容出现了乱码,而且邮件时间混乱,2020 年的邮件可能在 2019 年的邮件之前,也可能在之后。 |
| windows 下用 powershell 和用 cmd 运行 Python 有什么区别吗 Posted: 08 Jun 2021 03:49 AM PDT 是这样的。在同一个 python 虚拟环境下(安装有 PyYAML 包),在 cmd 中 import yaml 一切正常,在 powershell 下 import yaml 就会提示 No module named 'yaml' 请教一下是什么问题 |
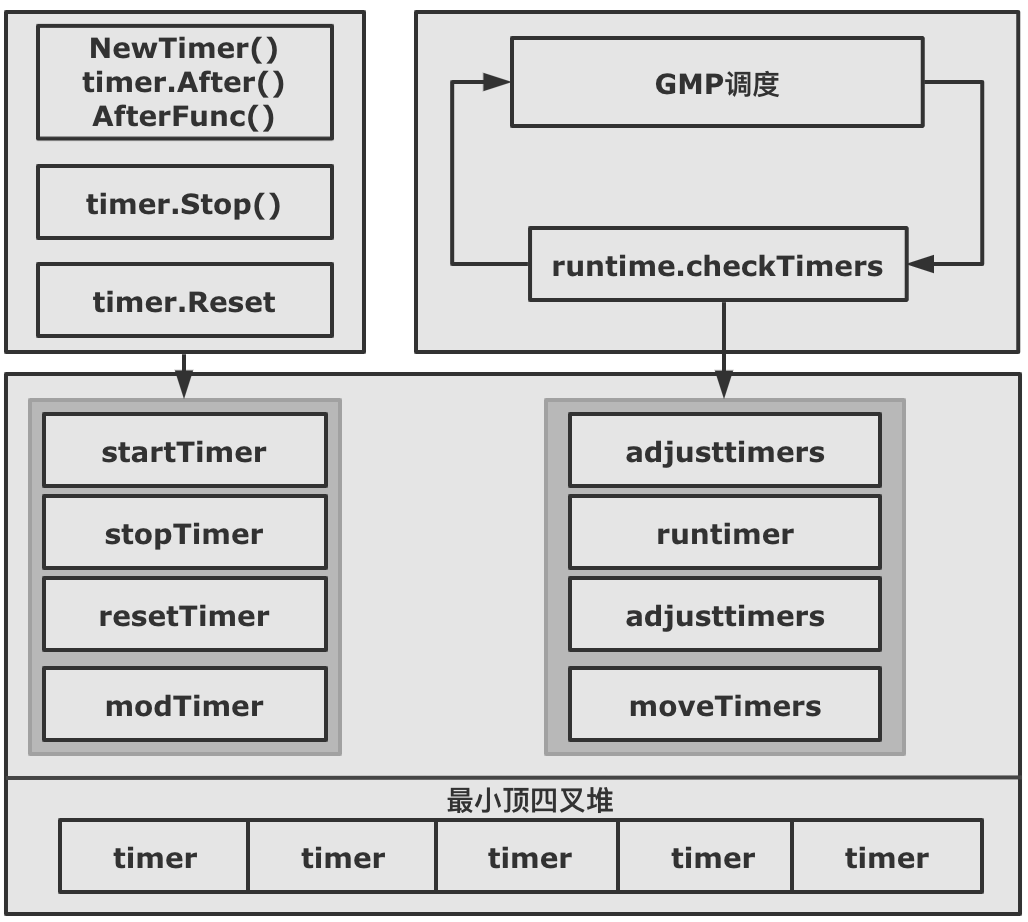
| Posted: 08 Jun 2021 03:15 AM PDT hi,大家好,我是 haohongfan 。 本篇文章剖析下 Go 定时器的相关内容。定时器不管是业务开发,还是基础架构开发,都是绕不过去的存在,由此可见定时器的重要程度。 我们不管用 NewTimer, timer.After,还是 timer.AfterFun 来初始化一个 timer, 这个 timer 最终都会加入到一个全局 timer 堆中,由 Go runtime 统一管理。 全局的 timer 堆也经历过三个阶段的重要升级。
Go 1.14 以后的 timer 性能得到了质的飞升,不过伴随而来的是 timer 成了 Go 里面最复杂、最难梳理的数据结构。本文不会详细分析每一个细节,我们从大体来了解 Go timer 的工作原理。 1. 使用场景Go timer 在我们代码中会经常遇到。 场景 1:RPC 调用的防超时处理(下面代码节选 dubbogo) 场景 2:Context 的超时处理 2. 图解源码2.1 四叉堆原理timer 的全局堆是一个四叉堆,特别是 Go 1.14 之后每个 P 都会维护着一个四叉堆,减少了 Goroutine 之间的并发问题,提升了 timer 了性能。 四叉堆其实就是四叉树,Go timer 是如何维护四叉堆的呢?
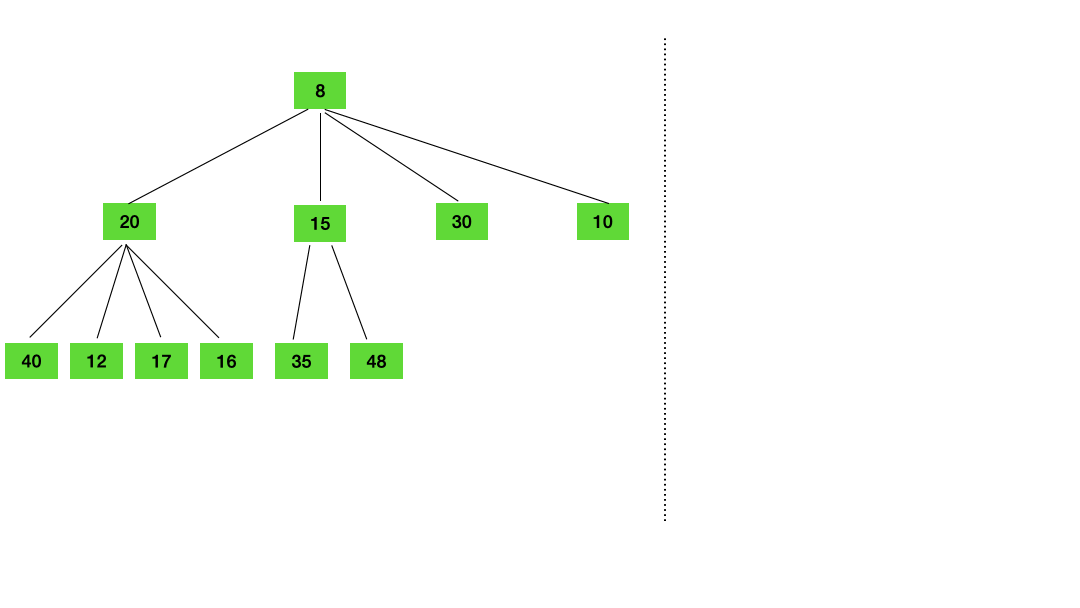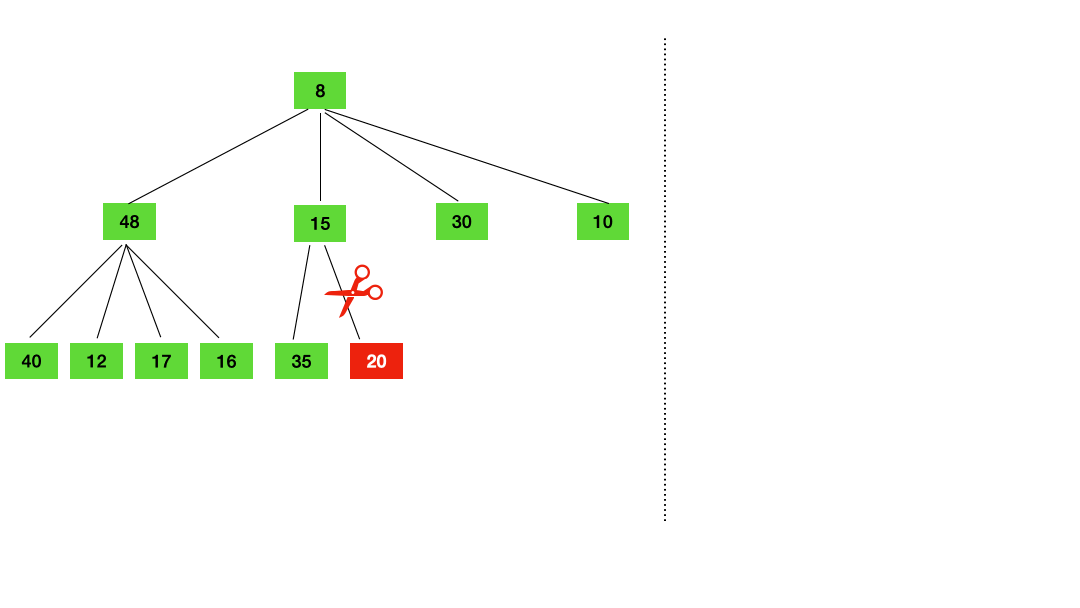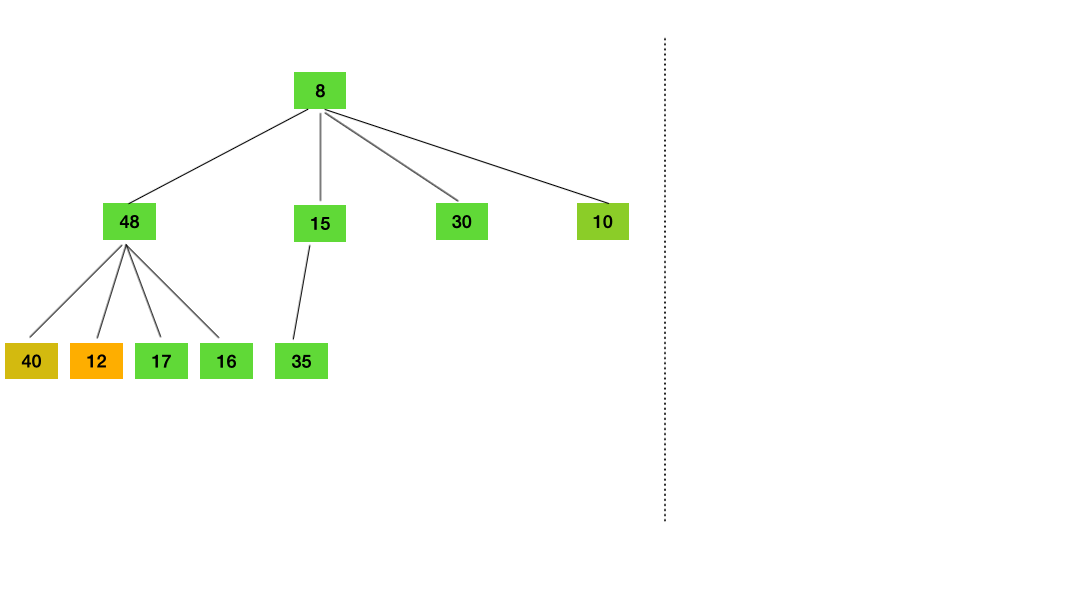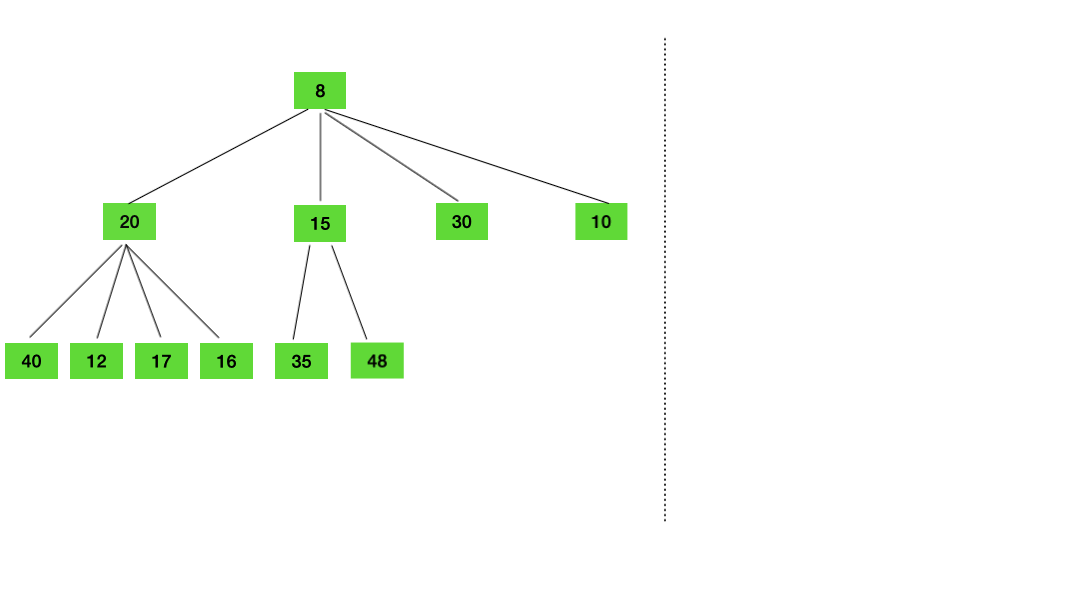
这里用两张动图简单演示下 timer 的插入和删除 把 timer 插入堆 把 timer 从堆中删除 2.2 timer 是如何被调度的?
2.3 timer 是如何加入到 timer 堆上的?把 timer 加入调度总共有下面几种方式:
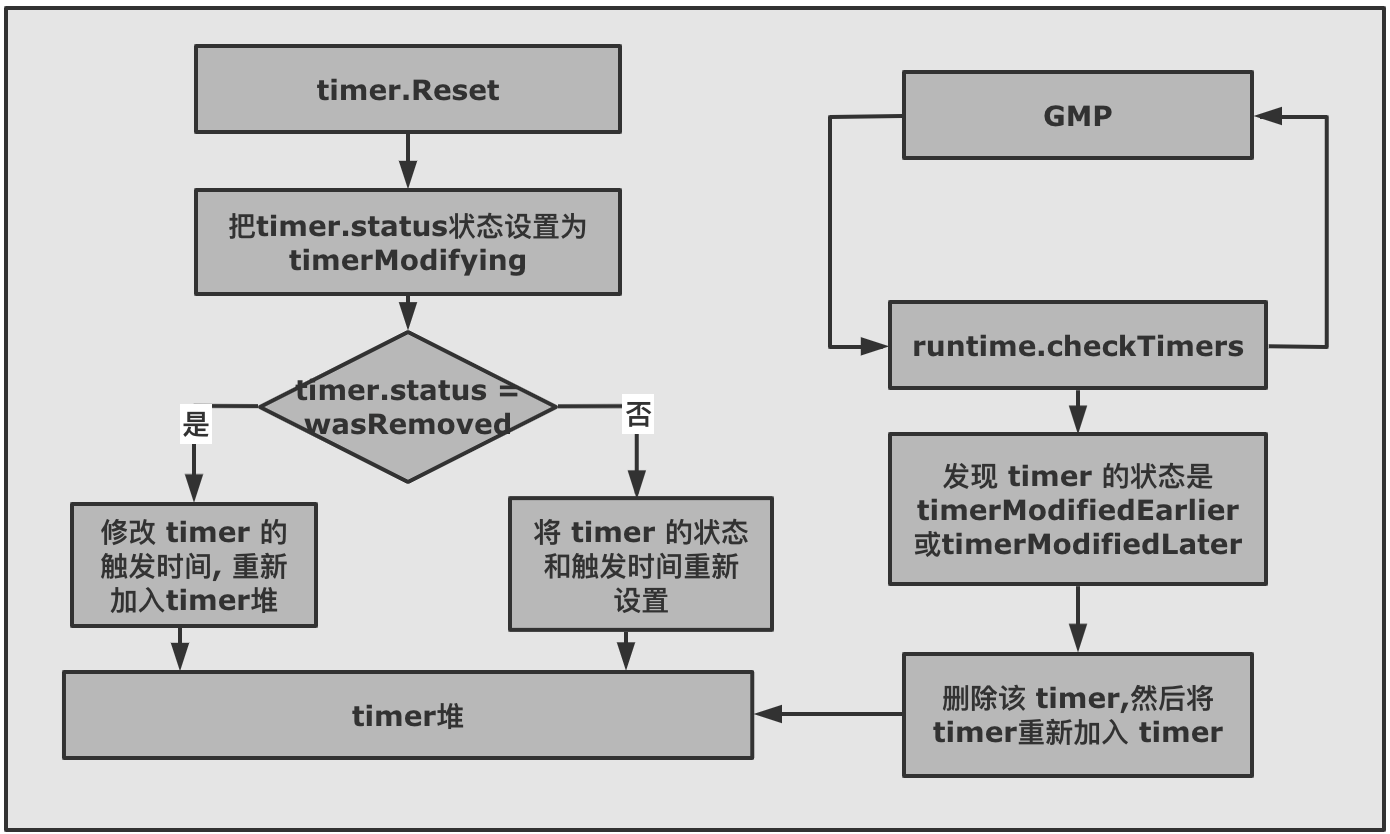
2.4 Reset 时 timer 是如何被操作的?Reset 的目的是把 timer 重新加入到 timer 堆中,重新等待被触发。不过分为两种情况:
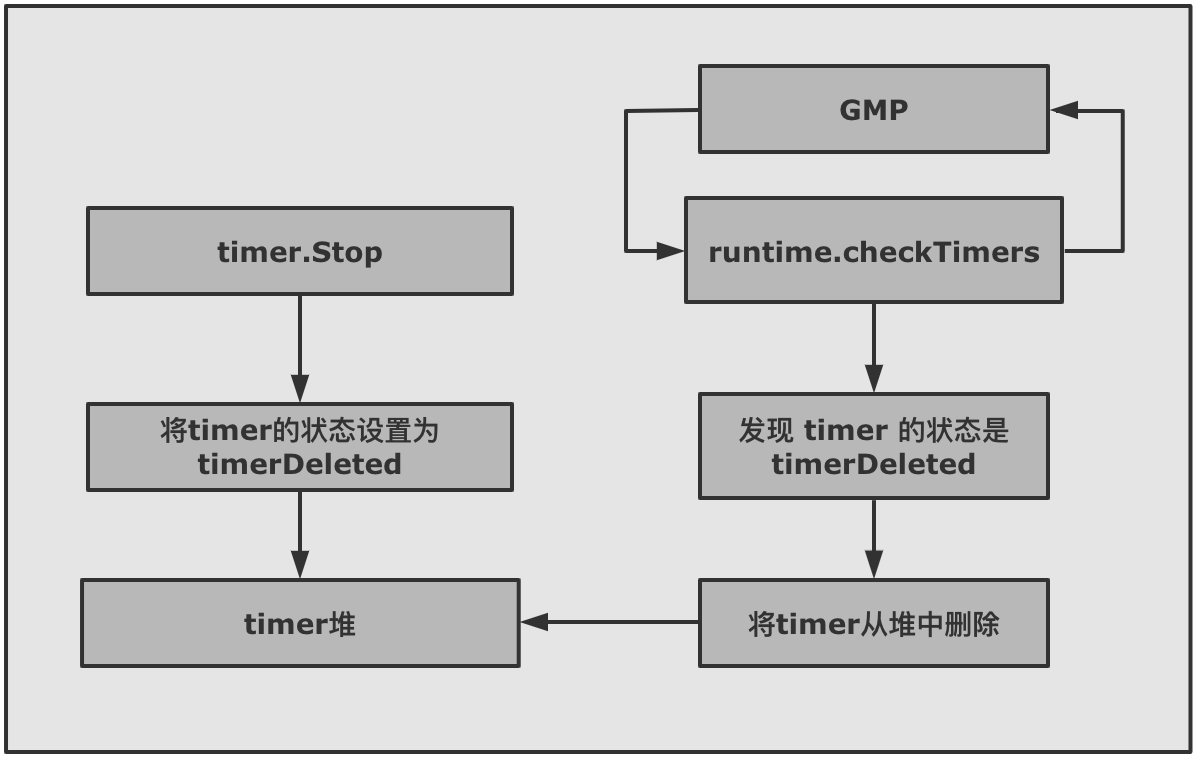
2.5 Stop 时 timer 是如何被操作的?time.Stop 为了让 timer 停止,不再被触发,也就是从 timer 堆上删除。不过 timer.Stop 并不会真正的从 p 的 timer 堆上删除 timer,只会将 timer 的状态修改为 timerDeleted 。然后等待 GMP 触发的 adjusttimers 或者 runtimer 来执行。 真正删除 timer 的函数有两个 dodeltimer,dodeltimer0 。
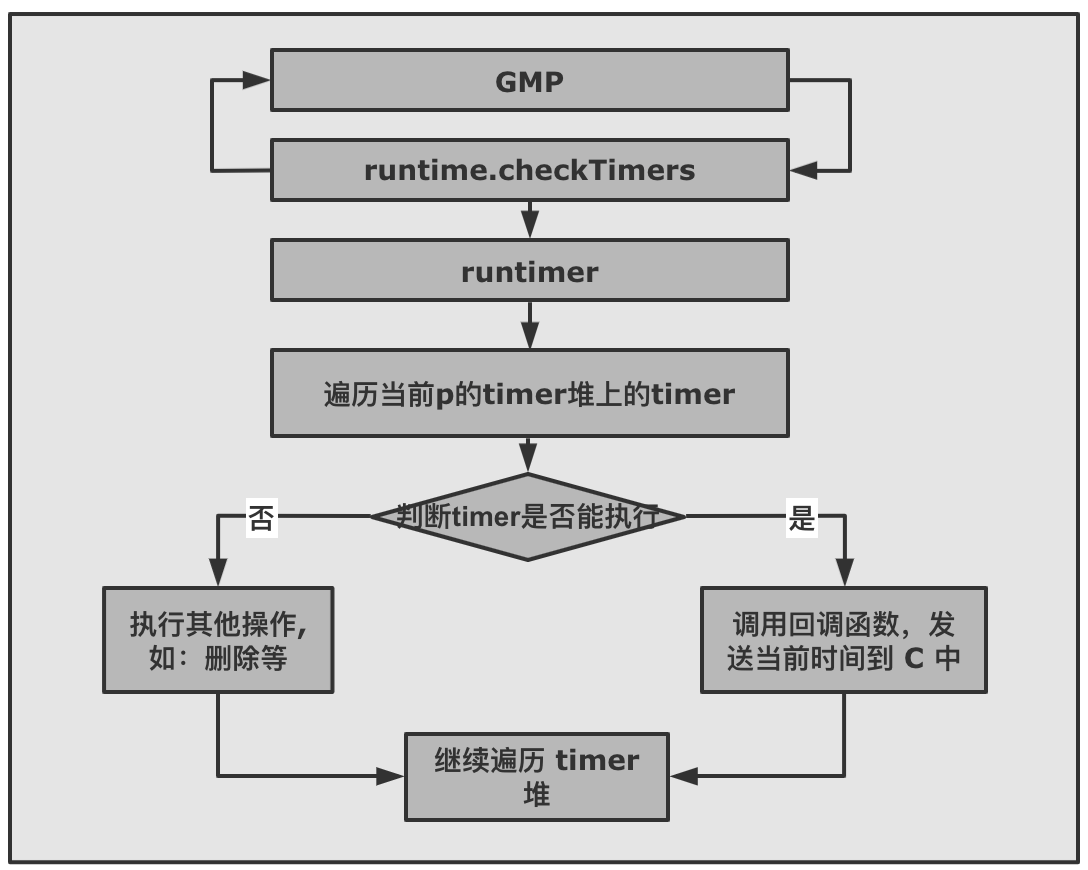
2.6 Timer 是如何被真正执行的?timer 的真正执行者是 GMP 。GMP 会在每个调度周期内,通过 runtime.checkTimers 调用 timer.runtimer(). timer.runtimer 会检查该 p 的 timer 堆上的所有 timer,判断这些 timer 是否能被触发。 如果该 timer 能够被触发,会通过回调函数 sendTime 给 Timer 的 channel C 发一个当前时间,告诉我们这个 timer 已经被触发了。 如果是 ticker 的话,被触发后,会计算下一次要触发的时间,重新将 timer 加入 timer 堆中。
3. Timer 使用中的坑确实 timer 是我们开发中比较常用的工具,但是 timer 也是最容易导致内存泄露,CPU 狂飙的杀手之一。 不过仔细分析可以发现,其实能够造成问题就两个方面:
3.1 错误创建很多 timer,导致资源浪费上面这段代码是造成 timer 异常的最常见的写法,也是我们最容易忽略的写法。 造成问题的原因其实也很简单,因为 timer.After 底层是调用的 timer.NewTimer,NewTimer 生成 timer 后,会将 timer 放入到全局的 timer 堆中。 for 会创建出来数以万计的 timer 放入到 timer 堆中,导致机器内存暴涨,同时不管 GMP 周期 checkTimers,还是插入新的 timer 都会疯狂遍历 timer 堆,导致 CPU 异常。 要注意的是,不只 time.After 会生成 timer, NewTimer,time.AfterFunc 同样也会生成 timer 加入到 timer 中,也都要防止循环调用。 解决办法: 使用 time.Reset 重置 timer,重复利用 timer 。 我们已经知道 time.Reset 会重新设置 timer 的触发时间,然后将 timer 重新加入到 timer 堆中,等待被触发调用。 3.2 程序阻塞,造成内存或者 goroutine 泄露上面的代码可以看出来,只有等待 timer 超时 "done" 才会输出,原理很简单:程序阻塞在 <-timer1.C 上,一直等待 timer 被触发时,回调函数 time.sendTime 才会发送一个当前时间到 timer1.C 上,程序才能继续往下执行。 不过使用 timer.Stop 的时候就要特别注意了,比如: 程序就会一直死锁了,因为 timer1.Stop 并不会关闭 channel C,使程序一直阻塞在 timer1.C 上。 上面这个例子过于简单了,试想下如果 <- timer1.C 是阻塞在子协程中,timer 被的 Stop 方法被调用,那么子协程可能就会被永远的阻塞在那里,造成 goroutine 泄露,内存泄露。 Stop 的正确的使用方式: 到此,Go timer 基本已经结束了,有想跟我讨论的可以在留言区评论。
|
| Posted: 08 Jun 2021 02:55 AM PDT getName()/setName(value) 和 name()/name(value) 你们习惯用哪种? |
| Posted: 08 Jun 2021 02:50 AM PDT |
| emm.目前团队缺少一些小伙伴,欢迎关注,团队偶尔佛系偶尔鸡血! Posted: 08 Jun 2021 02:43 AM PDT 目前团队在做一些加解密相关的业务,大部分小伙伴都是 90 后,氛围比较 Nice,人不多十几个人,胶原蛋白和青春气息感觉还是有的。缺个做 C++或者 Golog 或者 Rust 以及 Android 小伙伴,要求有些密码学经验,动手能力,自生自灭类。目前团队都比较有自驱力,佛系类技术,有产品和设计小姐姐。年度会举行远游团建,加班不是特别多,想来想去优点就是 比较团结 像一家人吧。市场不怎么愁,做不完的客户,几年内公司业绩无忧。感兴趣的请发邮了解 Base64:emhhaW1lbmc4NjFAZ21haWwuY29t |
| Posted: 08 Jun 2021 01:46 AM PDT 对于双显卡笔记本外接显示器,在 linux 并不是十分很直接方便,想求一个解决方案 目前是 debian+xfce,使用 nvidia-xrun 来进行显卡切换(关闭独显),要接显示器时需打开独显,配置 X11,重启电脑(可嗯不要重启也行?),用 xrandr 开启第二屏才行。方案来源于一个 nvidia form 的一个帖子 想知道有无更加方便的方案 |
| Posted: 08 Jun 2021 01:32 AM PDT 替换 ... 的内容,实现第一次打印 true 第二次打印 false,JDK 11 以上环境。 其他备注:
目前只知道从 hashcode 入手,Stringbuilder 不可继承不好弄。 |
| Posted: 08 Jun 2021 01:20 AM PDT 求大佬前来搭救。 集群是这样配置的: node-0,node-1,node-2,node-3 上 HDD 硬盘,pool name:storage 。 Node-4,node-5,node-6 上 SDD 硬盘,pool name:cache, 做成缓存。 # ceph osd lspools 4 storage 5 image-storage_data 6 image-storage_metadata 8 cache 查看 pool 8 ( cache )的情况,可以看到每个 osd 有 64 个 pg, 集中在 4,5,6 三个 node 上。没问题。 # osdmaptool osdmap --import-crush ./crushmap --test-map-pgs --pool 8 osdmaptool: osdmap file 'osdmap' osdmaptool: imported 1839 byte crush map from ./crushmap pool 8 pg_num 64 #osd count first primary c wt wt osd.0 0 0 0 9.09419 1 osd.1 0 0 0 10.9131 1 osd.2 0 0 0 9.09419 1 osd.3 0 0 0 14.5527 1 osd.4 64 27 27 0.872299 0.950012 osd.5 64 21 21 0.872299 0.950012 osd.6 64 16 16 0.872299 0.950012 in 7 avg 27 stddev 31.6747 (1.17314x) (expected 4.84873 0.179583x)) min osd.4 64 max osd.4 64 size 3 64 osdmaptool: writing epoch 4682 to osdmap 但是看 pool 4 ( storage ), 为什么每个 osd 上都有属于 pool storage 的 pg 呢? 4,5,6 结点上没有 hdd 呀。 # osdmaptool osdmap --import-crush ./crushmap --test-map-pgs --pool 4 osdmaptool: osdmap file 'osdmap' osdmaptool: imported 1839 byte crush map from ./crushmap pool 4 pg_num 128 #osd count first primary c wt wt osd.0 93 28 28 9.09419 1 osd.1 100 30 30 10.9131 1 osd.2 75 27 27 9.09419 1 osd.3 88 35 35 14.5527 1 osd.4 15 6 6 0.872299 0.950012 osd.5 10 2 2 0.872299 0.950012 osd.6 3 0 0 0.872299 0.950012 in 7 avg 54 stddev 40.1639 (0.743777x) (expected 6.85714 0.126984x)) min osd.6 3 max osd.1 100 size 3 128 |
| Linux 上有没有这样一种“写时复制”的文件系统或者工具? Posted: 07 Jun 2021 11:59 PM PDT 需求:
|
| Posted: 07 Jun 2021 11:28 PM PDT 我有服务 A 和服务 B 。服务 A 在请求服务 B 时,服务 B 会将请求作为一个任务,并将其状态(执行中,成功,失败等)存放在 Redis 中执行。现在所有服务都在 K8S 上并每个服务有多个副本,
现在的想法是在 Redis 中用副本的 name 作为前缀来区分副本,但是副本重启后该 name 会变化。在不引入新组件的情况下,有什么方案可以解决这些问题吗? |
| Posted: 07 Jun 2021 11:23 PM PDT 公司单子有点多,做不过来,有擅长 Python,网站开发,还有 C++,JAVA 方面的可以加一下我,可以长期合作 V DeepRedTech |
| pam- Python 的 Python 解释器是哪里设置的,可以设置其他解释器吗? Posted: 07 Jun 2021 10:38 PM PDT 因为我使用了其他库,结果提示没有那个库,所以来问问 参考 |
| windows 的 remote desktop connection 有没有办法,在全屏的时候,使用键盘切换回原 windows? Posted: 07 Jun 2021 09:02 PM PDT 现在有两台机器,都是 windows 。本地 A,远程 B 在 A 上面打开 remote desktop connection,连接到 B 。连接时,有个选项: local resources-> keyboard -> apply windows key combinations -> "only when using the full screen" OR "on the remote computer" 因为,我希望远程到 B 机器上时,还能够使用 alt+tab, win+D 切换机器 B 上面的应用和窗口,等等。 但是,这样就有一个问题,我没有办法使用键盘上的快捷键,切回机器 A 了。只能用鼠标点击 remote desktop connection 最上面那个控制栏的最小化按钮。 大家有什么办法? |
| Posted: 07 Jun 2021 08:55 PM PDT rc.lua 可以支持很多自定义的,不会 lua,有木有从入门到入土的一系列参考,或者主题推荐。 |
| Titanium Backup 跟安卓 11 不兼容吗?明明给了 root 却说拿不到 root 权限 Posted: 07 Jun 2021 07:05 PM PDT 想试一下最新的 Titanium 是不是能备份 /还原工作空间里的 app,在安卓 11 上安装了最新的谷歌市场下载的版本,但是明明给了 root 权限,运行的时候却提示错误说拿不到 root,见图:i.imgur.com/sN1WkLC.png ,这什么原因? |
| Apple 规定同一个身份证只能注册一个开发者账号,如果我之前用的一个苹果开发账号过期后不续费,多久后可以用另一个 Apple ID 申请开发账号? Posted: 07 Jun 2021 11:36 AM PDT |
| Posted: 07 Jun 2021 08:08 AM PDT 在 centos7 拉取 github 源码编译经常连不上,找了许多资料发现透明代理比较合适。 一番折腾 TCP 终于正常转发,UDP 如果配置 PREROUTING 就没任何转发效果,配置成 OUTPUT 可以转发不过报文不对: 求大佬帮忙 |


{kind=link}
| You are subscribed to email updates from V2EX - 技术. To stop receiving these emails, you may unsubscribe now. | Email delivery powered by Google |
| Google, 1600 Amphitheatre Parkway, Mountain View, CA 94043, United States | |
No comments:
Post a Comment