V2EX - 技术 |
- ColorOS 和 OriginOS 这俩系统怎么样?想入一块安卓机。。。
- puppeteer 的实现原理
- eval()和 exec()这类语句存在的意义是什么?
- 我们离像乐高积木那样编程还有多远?
- 有程序员回老家 银行之类 的地方上班的吗
- 腾讯轻量云怎么安装其他系统,例如 Fedora?
- vim 配置出现乱码
- 关于 SD 卡文件同步复制到电脑的办法
- 同一主机内部两网卡互相通信如何强制过物理网卡?
- 请问 v 站、菜鸟教程、 github,他们用的什么工具来让 markdown 转 html 的呢?
- ICMP 报文包含 引起该 ICMP 报文首次生成的 IP 数据报的首部和前 8 字节?怎么验证
- qnap nas ts551. 插上硬盘不停的自动重启
- k8s CPU limit 和 throttling 的迷思
- 请问项目中修改第三方包的正确姿势是什么?
- MIUI 相册近 200GB 未知空间占用
- 请教一个关于安卓多设备适配问题
| ColorOS 和 OriginOS 这俩系统怎么样?想入一块安卓机。。。 Posted: 14 Nov 2021 03:11 PM PST |
| Posted: 14 Nov 2021 10:19 AM PST hi all ,分享一个 puppeteer 的 debug, 更多可以持续关注 🌟 github | blog 🌟
背景有同学吐槽整个 CI/CD 下来时间太长了, 其中 e2e 测试节点就花了 10 分钟 🐢 现在我们采用的是 puppeteer 进行的一个自动化 e2e 测试, 该节点是在正式发布前, 预发发布后。 作为一个所有项目都必须要通过的一个节点, 它主要的功能是读取项目中的所有路由页面进行一个白屏测试与检查是否有 console.error 、网络错误等。 排查收到反馈后首先是进行排查, 发现该 spa 项目共 96 个 ⚠️ 路由页面, 而只会开启 ⚠️ 一个 puppeteer browser 实例去逐个对页面测试导致了耗时过长。 一开始也没有着急去改, 而是问第一版开发 e2e 的大佬, 为何没有开启多个 browser 实例去并行完成这些路由页面的任务, 得到的反馈是当时项目还比较小, 就没有做这方面的优化了。 解决看样子多个实例不是因为有坑才没做, 当时可能只是不想 Overdesign 。解决这个问题比较简单把收到的若干个任务进行分组, 然后去开启多个 browser 实例去并行完成这些任务即可。
这里说明的一点分的组不是越多越好, 比如 96 个任务每组最大 20 个分为 5 组, 总时长并不会减少 5 倍。因为 browser 实例越多占用的系统资源也会越多。这有点像小学求最优解的题, 随着每组数量(x 轴)的增长, 总耗时(y 轴)会类似于一个抛物线。 puppeteer其实 puppeteer 已经应用在我们很多的前端领域, 如上面所说的 e2e 测试, 其他诸如爬虫、页面定时巡检、页面性能监控都是使用的 puppeteer 。 本次就很快解决了这个问题, 出于好奇也粗略的去学习了一下 puppeteer 的实现原理。 新的 browser 实例实现
browser 的启动流程
与 browser 通信上面 waitForWSEndpoint 函数获取到新打开的 chromium 进程的 WebSocket 监听的 url 后, 这里就通过 ws 这个 npm 包生成了一个 NodeWebSocket 。 到这里我们知道了提供若干个 api 的 puppeteer 原来是一个 WebSocket 客户端, 另一端是 chromium 进程进行真实的操作。 通信协议以浏览器新打开一个页面 newPage 函数的实现为例, 可知是通过 NodeWebSocket 发送了一个 'Target.createTarget' 事件, 可传参数见下面的 DevTools Protocol 这里用来操控 chromium 的协议都可以在这里查阅 Chrome DevTools Protocol
小结发现问题后最好先追本溯源, 以免走前人踩过的坑。其次有多余的时间也不妨探究一下其实现原理, 技术其实都是相通的, 看的多了总是能举一反三 ~ |
| Posted: 14 Nov 2021 09:44 AM PST |
| Posted: 14 Nov 2021 09:34 AM PST 记得刚学编程的时候,老师都说要低耦合高内聚 后面接触了 OO ,好像也讲了很多模块化的设计方法,比如依赖反转 工作后,又有了微服务等划分系统模块的方法 但实际上,各个模块间的集成并非像拼积木那么简单,现在我们离像乐高积木那样编程更近了吗 在使用一些 vim 、emacs 插件的时候,偶尔会有一种积木组合的感觉,不知大家还见过哪些模块化编程、构造的软件呢 |
| Posted: 14 Nov 2021 08:06 AM PST |
| Posted: 14 Nov 2021 07:51 AM PST 如题。 |
| Posted: 14 Nov 2021 06:05 AM PST macbook 按网上教程配置 vim ,然后右下角这个命令栏出现乱码该怎么办啊 https://imgur.com/a/Vs3ZSvT |
| Posted: 14 Nov 2021 05:54 AM PST 日常拍照后, 有从 SD 卡等外部存储中复制到电脑硬盘的需求, 手动复制过程中文件多了容易出现问题(比如文件名冲突、比如只复制新增的照片和视频时需要肉眼对比) ,有没有能解决如下需求的同步复制工具? 基于文件的 md5 同步。解决如下两种场景:
|
| Posted: 14 Nov 2021 05:39 AM PST rt ,一张网卡( ip 为 192.168.3.11 )做网关,监听来自另一个网卡( ip 为 192.168.3.5 ) mac 地址的包,但是由于两网卡处于同一 linux ,可能( 192.168.3.5 )的包经过操作系统的优化,没有过物理网卡就发给了 192.168.3.11 ?导致我部署在 192.168.3.11 上监听 mac 地址( 192.168.3.5 所在网卡)的程序失效,请教大佬如何让"内部两张网卡或者说两 ip 互相通信如何强制过物理网卡"? |
| 请问 v 站、菜鸟教程、 github,他们用的什么工具来让 markdown 转 html 的呢? Posted: 14 Nov 2021 04:16 AM PST |
| ICMP 报文包含 引起该 ICMP 报文首次生成的 IP 数据报的首部和前 8 字节?怎么验证 Posted: 14 Nov 2021 02:15 AM PST
另外,"以便发送方能确定引发该差错的数据报",这句话看起来好像很合理,但是我没有从抓包得到验证 上一句的证据,所以这句话也有点疑惑。
我只发现,每一对 ICMP 请求和回应里,它们的 ICMP 的 payload 都是什么 61 62 63 ... 这样的无意义的东西。 |
| Posted: 14 Nov 2021 12:51 AM PST 刚买的 qnap nas ts551 ,才把系统弄好,第二天就出问题。具体表现是 插上硬盘不停的自动重启。试过把硬盘拆下来放到电脑上可以识别 大家遇过类似的问题没? 感觉这 nas 太不稳定了,出了问题又难以 debug |
| k8s CPU limit 和 throttling 的迷思 Posted: 13 Nov 2021 11:53 PM PST 各位好。 很长一段时间,我一直在疑惑 k8s CPU limit 该如何设置,太小的值会给程序带来额外的、无意义的延迟( CPU throttling ),太大的值会带来过大的爆炸半径,削弱集群的整体稳定性。更让人纠结的是内核版本低于 4.18 的 Linux 还有个 bug 会造成不必要的 CPU 限流。 最近我算是搞明白了这个问题,记录了下来,希望能帮到与我一样为 CPU limit 和 throttling 纠结过的朋友。 欢迎讨论交流,谢谢。 |
| Posted: 13 Nov 2021 10:32 PM PST 有一个第三方包,我需要进行一些小的修改才能使用,我目前知道 2 个方法
提 PR 的话我觉得期待得到及时合并不太现实,你们遇到这样的问题都是怎么解决的呢? |
| Posted: 13 Nov 2021 06:04 PM PST 发现 MIUI 的小米相册占用了近 200GB 空间, 但存储的照片视频总共才 5GB, 回收站也是空的. 扫描发现 日用手机没有 root, 对于这额外的空间占用各位有头绪吗? 不 root 的情况下可以消除吗?
|
| Posted: 13 Nov 2021 09:22 AM PST 现有几种设备分辨率的分别 1920*132 1920*480 1920*1080 等各种条形屏矩形屏。现在布局是几张卡片,然后要根据分辨率来自动排列,比如条形屏上就排成一行,矩形屏可以排成 2 行 5 列啥的(居中),然后还有竖屏(可能就排成 5 行 2 列),兼顾对齐美观。 现在产品要求写一个布局,然后会自动在不同设备上展示合理的排列,大佬们有什么方便的方案(产品要求要简单点实现,我直接内心 c 语言) 目前我想到的自定义个 viewgroup (经理说要搞这么复杂吗);弄个 recyclerview (每个卡片数据界面都不一样,多布局又是一堆代码) |



 就是上面这句话,ICMP 报文包含 引起该 ICMP 报文首次生成的 IP 数据报的首部和前 8 字节? 我试了一下 wireshark 抓包 ping 命令,
就是上面这句话,ICMP 报文包含 引起该 ICMP 报文首次生成的 IP 数据报的首部和前 8 字节? 我试了一下 wireshark 抓包 ping 命令,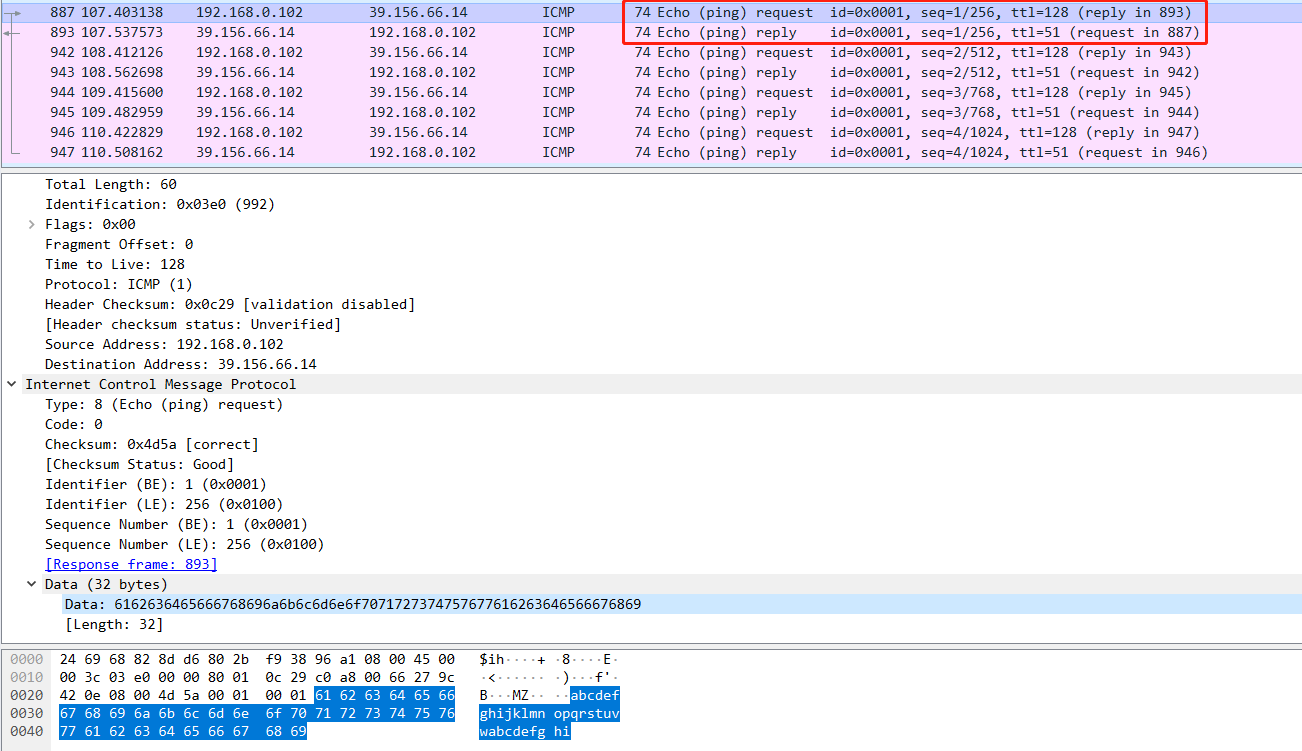


| You are subscribed to email updates from V2EX - 技术. To stop receiving these emails, you may unsubscribe now. | Email delivery powered by Google |
| Google, 1600 Amphitheatre Parkway, Mountain View, CA 94043, United States | |
No comments:
Post a Comment