Recent Questions - Unix & Linux Stack Exchange |
- How is "fifty million man-years" development effort inside <The Art of Unix Programming>
- How to recover Data after "mdadm zero-superblocks"
- Disagreement between glib and gcc after gcc downgrade
- Why qbittorrent and deluge can download the resource instead of transmission?
- different ways of disabling password logins on FreeBSD
- How can I disable (and later re-enable) one of my NVIDIA GPUs?
- bash multiline string variable assignment failing
- Applying simple string mappings on JSON files
- What is more efficient or recommended for reading output of a command into variables in Bash?
- How to assign a remote public ip (via wireguard) to lxc container
- Ensuring EXT4/BTRFS/other_journal_file_system guarantee backups even in power outages
- protection for duplicate sed replacements
- Flattening JSON lines arrays with JQ
- Have I put ZFS in a dangerous state by building against the wrong kernel headers?
- SSH Tunnel with automatic reconnect and password auth in Docker container
- unable to access Manjaro (kernel file not found)
- USB Created with dd will not boot
- ssh with separate stdin, stdout, stderr AND tty
- Can I install another Linux distribution to an extra HDD without rebooting?
- Virtualbox shared folders with symlinks
- Trouble selecting "Fully Preemptible Kernel (Real-Time)" when configuring/compiling from source
- When can a "cd" command fail in a shell script and what can I do to remedy it?
- Can I use Clonezilla to backup and restore a bootable USB volume?
- What to do if the owner of /usr/bin/* changes to a non-root?
- Apache - Allow access for folders starting with /
- How to stop the find command after first match?
| How is "fifty million man-years" development effort inside <The Art of Unix Programming> Posted: 13 Jun 2021 04:59 AM PDT I was reading the book <The Art of Unix Programming> There is one line claiming
That's 1.47 million man-year goes into Unix development during that period. It means 1.47 million developers worked on Unix system yearly. Personally I find the number a bit hard to believe. Or am I understanding the number in the wrong way? |
| How to recover Data after "mdadm zero-superblocks" Posted: 13 Jun 2021 05:16 AM PDT I wanted to swap from CentOS to Openmediavault. I had a RAID1 with mdadm in place and wanted to split it again into two separate disks. The Guide (Similar to ArchWiki) told me to do the following: Then I installed OMV5 and now I can not mount it because the superblock is gone(which I thought would not be a problem). I will provide more information if needed. Thanks in advance :) fdisk: blkid: mount: |
| Disagreement between glib and gcc after gcc downgrade Posted: 13 Jun 2021 04:34 AM PDT I updated my distro a week ago But need to work with I downgraded There is no problem with this but other thing get break like Firefox, Chromium etc and it gives the following error How can I downgrade gcc and coworker libs which I think its glib I don't know how to deal with glib Should I downgrade a glib thing belongs to them? |
| Why qbittorrent and deluge can download the resource instead of transmission? Posted: 13 Jun 2021 04:21 AM PDT I found that both qbittorrent and deluge can download the sample torrent which i have uploaded in the dropbox. It can't be downloaded with transmission,why? |
| different ways of disabling password logins on FreeBSD Posted: 13 Jun 2021 04:00 AM PDT What is the difference between:
and
They both accomplish the same thing: disabling password-based logins, but why would I pick one way over the other? |
| How can I disable (and later re-enable) one of my NVIDIA GPUs? Posted: 13 Jun 2021 05:19 AM PDT I'm working on a system with multiple NVIDIA GPUs. I would like disable / make-disappear one of my GPUs, but not the others; without rebooting; and so that I can later re-enable it. Is this possible? Notes:
|
| bash multiline string variable assignment failing Posted: 13 Jun 2021 03:51 AM PDT in bash why does this work fine: but this fails I was expecting both |
| Applying simple string mappings on JSON files Posted: 13 Jun 2021 02:36 AM PDT Somehow I think there must be a one-liner to apply a simple mapping on the command line. In this case the keys in JSON will (as usual) provide context, ensuring that we don't foolishly replace strings that shouldn't. Suppose we are given a library catalog in a JSON file using the Dewey Decimal Classification as well as a mapping between Dewey and the Library of Congress call numbers and want to produce the output file: Does this still fit within the one-line set of transformations that |
| What is more efficient or recommended for reading output of a command into variables in Bash? Posted: 13 Jun 2021 03:32 AM PDT If you want to read the single line output of a system command into Bash shell variables, you have at least two options, as in the examples below:
and
Is there any difference between these two? What is more efficient or recommended? |
| How to assign a remote public ip (via wireguard) to lxc container Posted: 13 Jun 2021 02:04 AM PDT What I have: lxc host /etc/wireguard/wg1.conf lxc container Everything is ok, but: What I want: I want to do this without changing anything in the container. Upd. I want to assign a public ip (owned by my remote server) to my home lxc container. Looks like it's impossible... |
| Ensuring EXT4/BTRFS/other_journal_file_system guarantee backups even in power outages Posted: 13 Jun 2021 02:43 AM PDT I'm using RSYNC to do periodic backups of my data into an external hard disk formatted in EXT4. I'm using the "hard link option", thus files that haven't changed from the previous backup are just hard linked instead of fully copied, which reduces the used disk space. To guarantee that a power cut, a system hang, or other problem during backups doesn't pose a problem, I first do the backup into a temporary folder, run a SYNC to flush the disk cache, rename the temporary folder to the definitive name, and run another SYNC. This way I can guarantee that all the data is in the disk before committing the backup. The point is that now I want to use a NAS, but I can't order a SYNC command (to flush the remote cache), neither through SFTP, nor NFS, which means that a problem in the middle of a backup can leave it in an intermediate state (like a file with only part of the data). My question is: setting my NAS in "data=journal" mode would guarantee that there won't be incorrect data if I suffer a power loss, as long as I first do the backup in a temporary folder and then, after that, I rename it to the definitive name? Do other filesystems (like BTRFS or ReiserFS) have that mode and should it be set like in EXT4? And, of course, which NAS can you recommend me that allows to enable that mode? |
| protection for duplicate sed replacements Posted: 13 Jun 2021 01:58 AM PDT This is more of a architectural question: I have a script that does some in file sed replacements/additions like: which works fine but this is part of a fairly large script and someone may either which might not be expected. So my question is: what's the best way to avoid this? I came up with something like: which should work fine but I was wondering if there's a better/recommended way to go about it? The above could obviously be problematic if your files are significantly large and you may just want to |
| Flattening JSON lines arrays with JQ Posted: 13 Jun 2021 05:20 AM PDT I can write but if I do I get How do I flatten the Update Since null safety is quite fashionable in several modern languages (and justifiably so), it is perhaps fitting to suppose that the question as asked above was incomplete. It's necessary to know how to handle the absence of a value. If one of the values is we get a null in the output That may well be what we want. We could add a second step in the pipeline (watching out not to exclude |
| Have I put ZFS in a dangerous state by building against the wrong kernel headers? Posted: 13 Jun 2021 03:53 AM PDT I've reverted to an older kernel after discovering that OpenZFS does not have currently have DKMS packages for the latest 5.12 release of Fedora 33 after a I used Koji with the search term Kernel to download and install the necessary dependencies to revert to the latest 5.11 kernel, rebooted into it, and rebuilt ZFS without issue. But while removing packages from the newer kernel I found that only I then realized that the packages listed by Koji for the packages I'd selected for 5.11 did not include Everything appears to be running correctly but have I inadvertently put my system or ZFS into a dangerously undefined state as a result? The packages I plan to install the correct kernel headers and rebuild these packages but wanted to ask here first for advice. Also, why is |
| SSH Tunnel with automatic reconnect and password auth in Docker container Posted: 13 Jun 2021 03:50 AM PDT I want to forward a Socks5 proxy using SSH with password authentication inside a Docker container. YES, I know that SSH keys would be better. But since it's not my own server, I'm not able to use keys, they just offer user/password authentication. Both packages are installed in the This establishes the SSH tunnel to the Socks5 proxy. But after the internet connection got lost, the authentication fails: I also tried and build a loop myself since I thought that Both approaches doesn't work. Since my ISP does a reconnect every 24 hours, it's annoying to restart the container every day by hand. I couldn't figure out yet why at the last approach in the loop can' handle the reconnect properly |
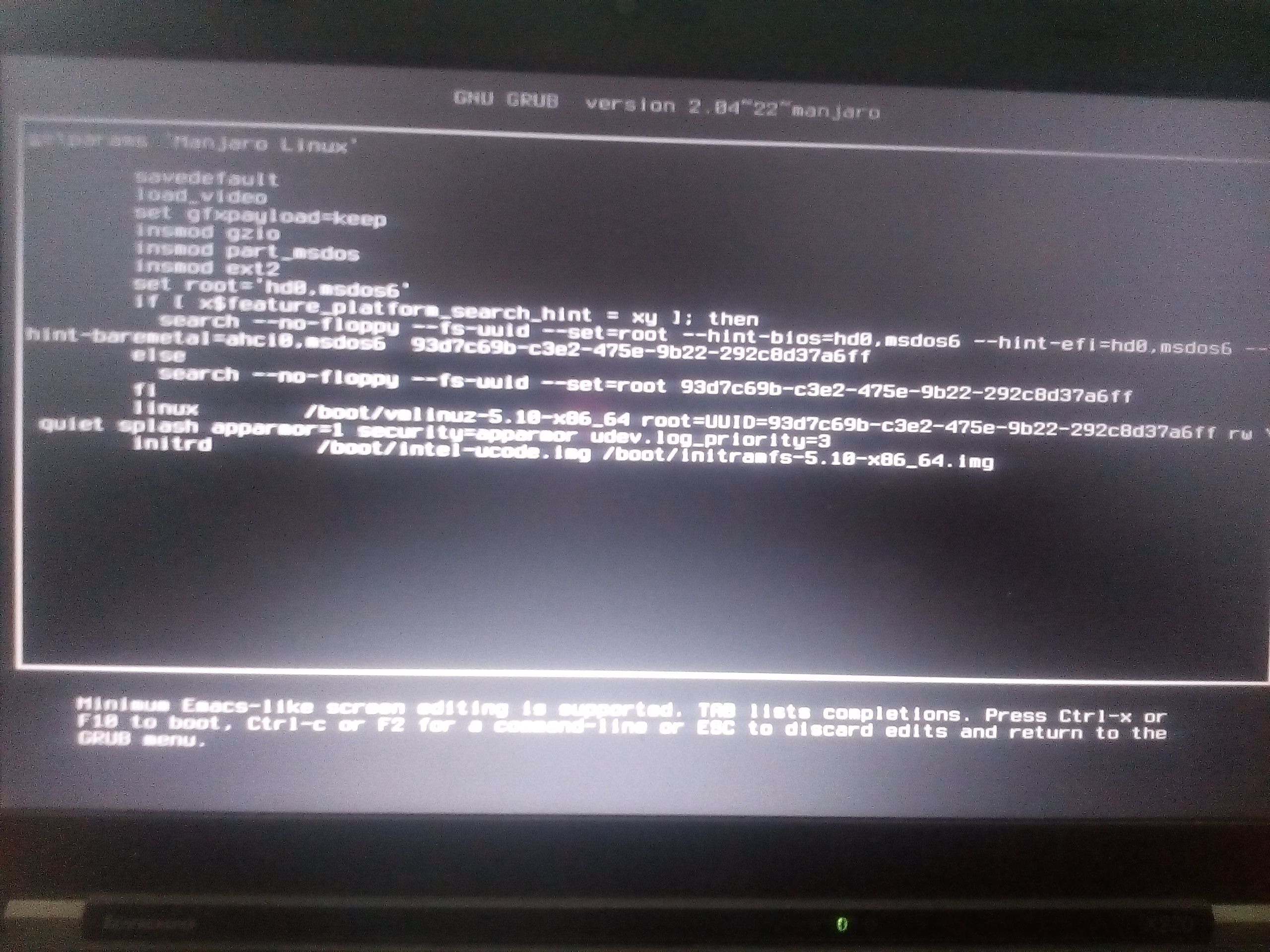
| unable to access Manjaro (kernel file not found) Posted: 13 Jun 2021 01:56 AM PDT I have Prime OS and Windows 10 alongside Linux Manjaro. I was using Prime OS nearly 2 hours. Then, I turned off my laptop for 30-60 minutes. Then, I turned my laptop on and I was using Windows 10 for 1 hours. After working on Windows 10, I had thought to work in Linux Manjaro. So, I turned my laptop off. Unfortunately, It was taking too much time to turn off my laptop that's why I had turned my laptop off by power button. Again, Windows 10 was automatically opening (without showing grub). So, I had again turned my laptop off by power button again. When I turned my laptop on and clicked on Linux Manjaro, I saw the following screen. I think that I can't access Manjaro's file from Windows or, Prime OS (I am not sure). How can I turn on Manjaro? Here's my grub info I have found following solutions
Currently, I don't have bootable USB. So, how can I deal with it from grub? I can move to grub command-line also. I had said what I did before starting Manjaro. After searching little bit, I remember that I had broke updating system. I had run following command Then, I had pressed on Ctrl+C. Since then, I am facing the problem. Currently what i am thinking that is searching for vmlinuz somehow in Manjaro from grub command line. I had tried with |
| USB Created with dd will not boot Posted: 13 Jun 2021 01:06 AM PDT I downloaded the newest RHEL 8 ISO (9 GB) and created a bootable USB with a Secondly I tried the
|
| ssh with separate stdin, stdout, stderr AND tty Posted: 13 Jun 2021 03:50 AM PDT ProblemConsider a command like this: where I used Research: the causeWith regular
Research: comparison to commands that work
Research: similar questionsI have found few similar questions:
My explicit questionIn the following command:
I imagine the ideal(?) solution will be a script/tool that replaces If it's possible, I prefer a client-side solution that does not require any server-side companion program. |
| Can I install another Linux distribution to an extra HDD without rebooting? Posted: 13 Jun 2021 04:38 AM PDT I have a computer with a Linux distribution installed on partitions in drive I want to install Linux to the second physical drive - to later run either on the same computer or another one. I know the planned hardware configuration of the target machine, and I have an installer for my new Linux distribution (say on a third drive, Can I perform the installation without rebooting? That is, other than in the usual way of booting from an installation medium? If this question is too general, then - can I do so with Debian Buster/Devuan Beowulf? Note: You may make any reasonable assumption about the system, but please state it explicitly. |
| Virtualbox shared folders with symlinks Posted: 13 Jun 2021 01:58 AM PDT I want to configure 1 shared folder Is there a way to use symlinks between the host & guest VMs in Virtualbox? |
| Trouble selecting "Fully Preemptible Kernel (Real-Time)" when configuring/compiling from source Posted: 13 Jun 2021 02:00 AM PDT I am trying to compile the 5.4 kernel with the latest stable PREEMPT_RT patch (5.4.28-rt19) but for some reason can't select the Fully Preemptible Kernel (RT) option inside make nconfig/menconfig. I've compiled the 4.19 rt patch before, and it was as simple as copying the current config (/boot/config-4.18-xxx) to the new And if I press F4 to "ShowAll", I do see the option: But cannot select it. I've tried manually setting it in But it never shows. I just went ahead and compiled it with With 4.19,
or something like that, but now it will just say:
Anyone know what I'm missing here? OS: CentOS 8.1.1911 Kernel: 4.18.0-147.8.1 -> 5.4.28-rt19 |
| When can a "cd" command fail in a shell script and what can I do to remedy it? Posted: 13 Jun 2021 05:06 AM PDT I have a shell script that failed to finish last week; it was a failed " The script is a Can you please list all the reasons a script would not be able to successfully execute a |
| Can I use Clonezilla to backup and restore a bootable USB volume? Posted: 13 Jun 2021 05:02 AM PDT I have this external USB HDD that I've installed Lubuntu 16.04 and Windows 10 on as a dual boot. They are portable installations that I can take around with me and use on a variety of computers and have all my apps and configurations with me. It's a real installation of Lubuntu, not a persistent live USB. Windows 10 was done through WinToUSB. Can I use Clonezilla to make a backup of this drive? And if I then restore that image to another drive, will that second drive also be bootable in the same way? |
| What to do if the owner of /usr/bin/* changes to a non-root? Posted: 13 Jun 2021 04:00 AM PDT It would be the right thing to say that I messed up! Accidentally, I changed the owner of all files in /usr/bin to 'dev' from 'root'. Now, sudo does not work! If I use sudo with any command, I get -
I cannot use Because this is a Virtual Machine, I cannot access the Recovery Console. Infact, even the Experts, please help me in getting control of the OS without having to re-image. Thanks! P.S - Possibly a duplicate but reposting as his solution was to start afresh. More info -
I am able to create a new user using the GUI. It accepted the root password. How do I grant the new user with root access without using visudo. |
| Apache - Allow access for folders starting with / Posted: 13 Jun 2021 02:07 AM PDT I'm running apache in a linux environment. I've to serve files whose directory structure have "/." in it. Now, apache by default won't allow files with /. To remove the constraint, I've included the following entry in httpd conf. |
| How to stop the find command after first match? Posted: 13 Jun 2021 01:26 AM PDT Is there a way to force the |




| You are subscribed to email updates from Recent Questions - Unix & Linux Stack Exchange. To stop receiving these emails, you may unsubscribe now. | Email delivery powered by Google |
| Google, 1600 Amphitheatre Parkway, Mountain View, CA 94043, United States | |
No comments:
Post a Comment