V2EX - 技术 |
- [信息安全] 开放几个课程 ��
- 尴尬的面试题,没有解决,估计面试官在后台偷笑
- 新手求问, swiftui 的文档应该怎么去阅读理解?救命啊。。
- 想再买个手机玩玩,魅族还是一加
- 大容量硬盘成为新的理财产品
- 很想吐槽一下目前的前端同事
- 脑洞一下,房子除出租外,如何创造收入?
- 大家有没有分析过红帽系 Linux 内核崩溃日志?
- MySQL 大表有性能问题,但如果只查最近的数据呢?
- HTML、CSS、JS 要掌握到什么程度才可以学习 Vue?
- @Transactional VS @Transactional(rollbackFor = Exception.class)
- [再硬核 | 5 千字长文+ 30 张图解 | 陪你手撕 STL 空间配置器源码]
- 关于风格迁移的全栈学习路线
- 有没有短视频(抖音/小红书)知识管理的工具
- [超硬核 | 2 万字+20 图带你手撕 STL 序列式容器源码]
- [硬核 | 万字长文炸裂!手撕 STL 迭代器源码与 traits 编程技法]
- 异步 MySQL 库 databases 的 Table 结构怎么从经典模式转成 ORM?
- NodeJs 中 代理、转发相关的问题?
- 伪装 User-Agent 后 respnse 302
- 没学过 Java 和 Spring Boot 该怎样学习 Nest.js 框架?
- 诸君帮看看这样的需求用哪个框架好做。。。
- edge 安卓版版本已经跟上节奏了
- 如何通俗易懂的阐述一下所有工具所扮演的角色和具体职责
- 大家有没有 Kubernetes Operator 教程推荐?
- vue 项目,开发预览和构建后的页面不一致,求助
- 如何优雅的实现千万级以上数据存储与读取?
- 请教各位关于 requests timeout 的问题,有小伙伴设置了 timeout,但是还是导致卡死的情况吗?其根源问题到底是什么?求大佬帮忙
- Android 应用程序如何缩小体积?
- cURL 为什么会把十进制数字转为 IP?
- MySQL 转码问题。
| Posted: 17 Apr 2021 05:44 AM PDT |
| Posted: 17 Apr 2021 04:56 AM PDT 给定链表的头指针和一个结点指针,在 O(1)时间删除该结点。不删除头尾结点 typedef struct LNode{ int data; LNode *next; }LNode, *List; 函数的声明如下: void DeleteNode(ListNode* pListHead, ListNode* pToBeDeleted); 我没有找出解决办法一直在纠结怎么直接下标索引。结果真是想多了 |
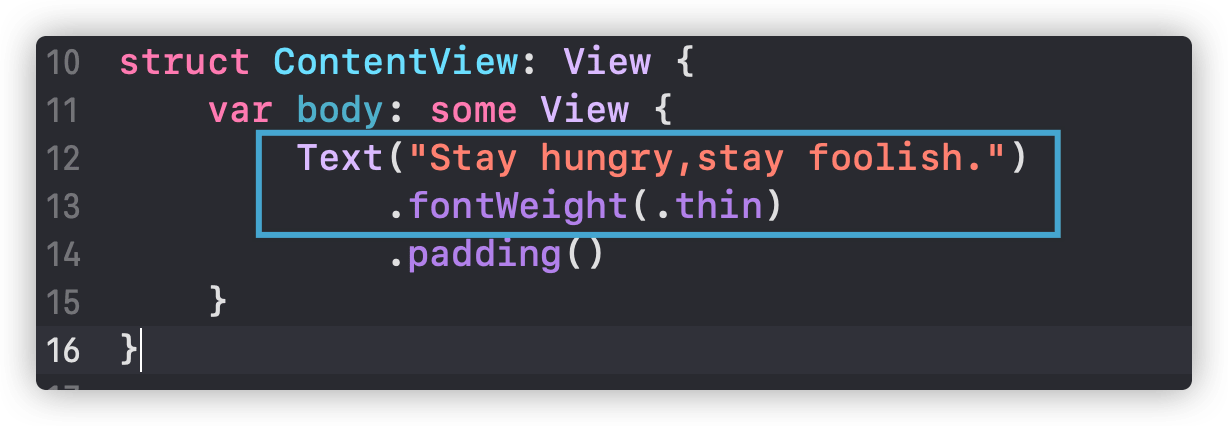
| 新手求问, swiftui 的文档应该怎么去阅读理解?救命啊。。 Posted: 17 Apr 2021 04:54 AM PDT 提问背景:学习了 swift 语法,但没有实际做 APP 的经验,所以对实际 APP 成型,以及面向对象编程的理解比较模糊,对于文档只阅读过 python 的 beautifulsoup,但感觉和 swiftui 的文档差别很大,swift 的文档真的看不懂,下面我贴了代码和文档的对比,求大神解答,真的 真的要疯了。 如下图:
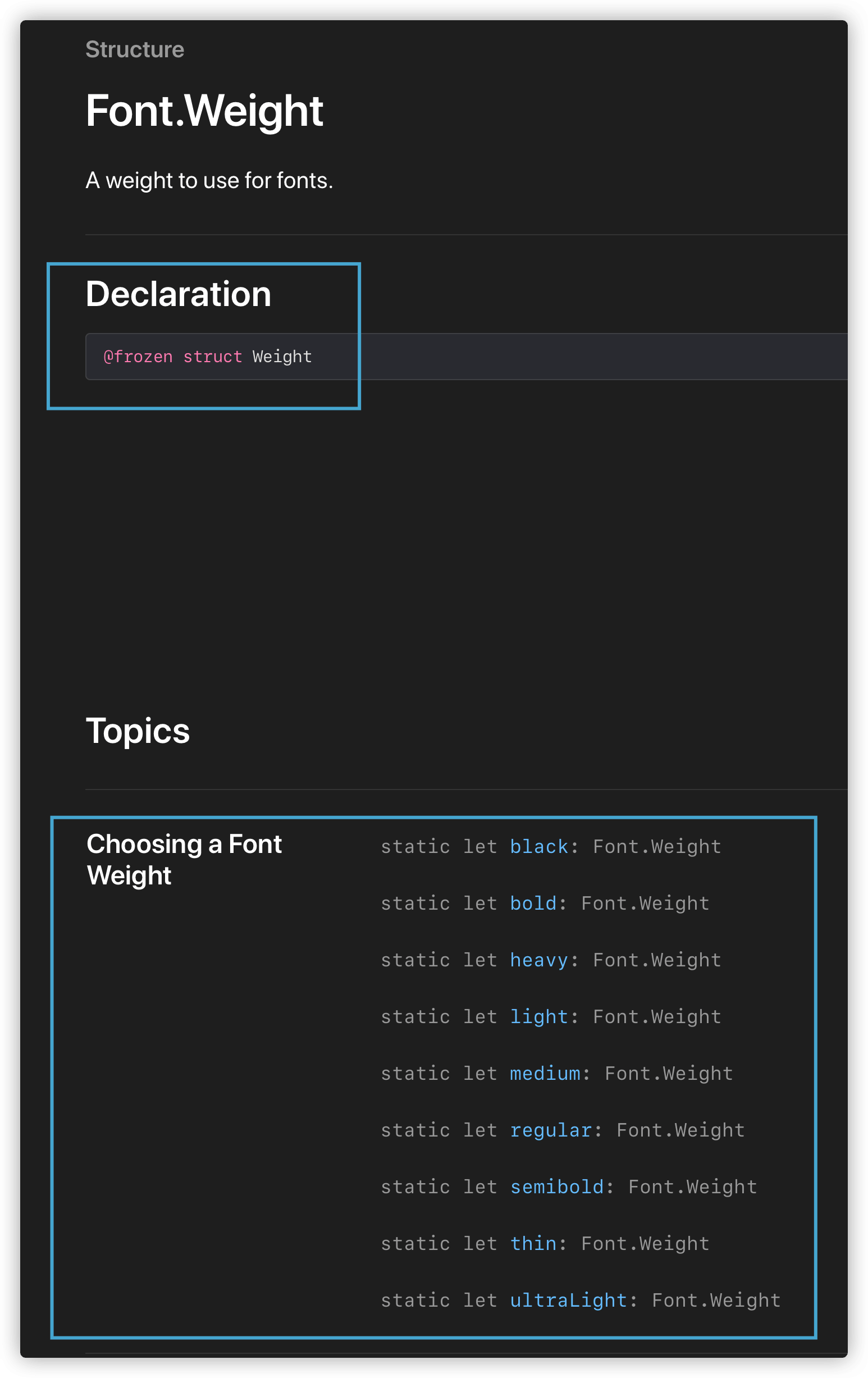
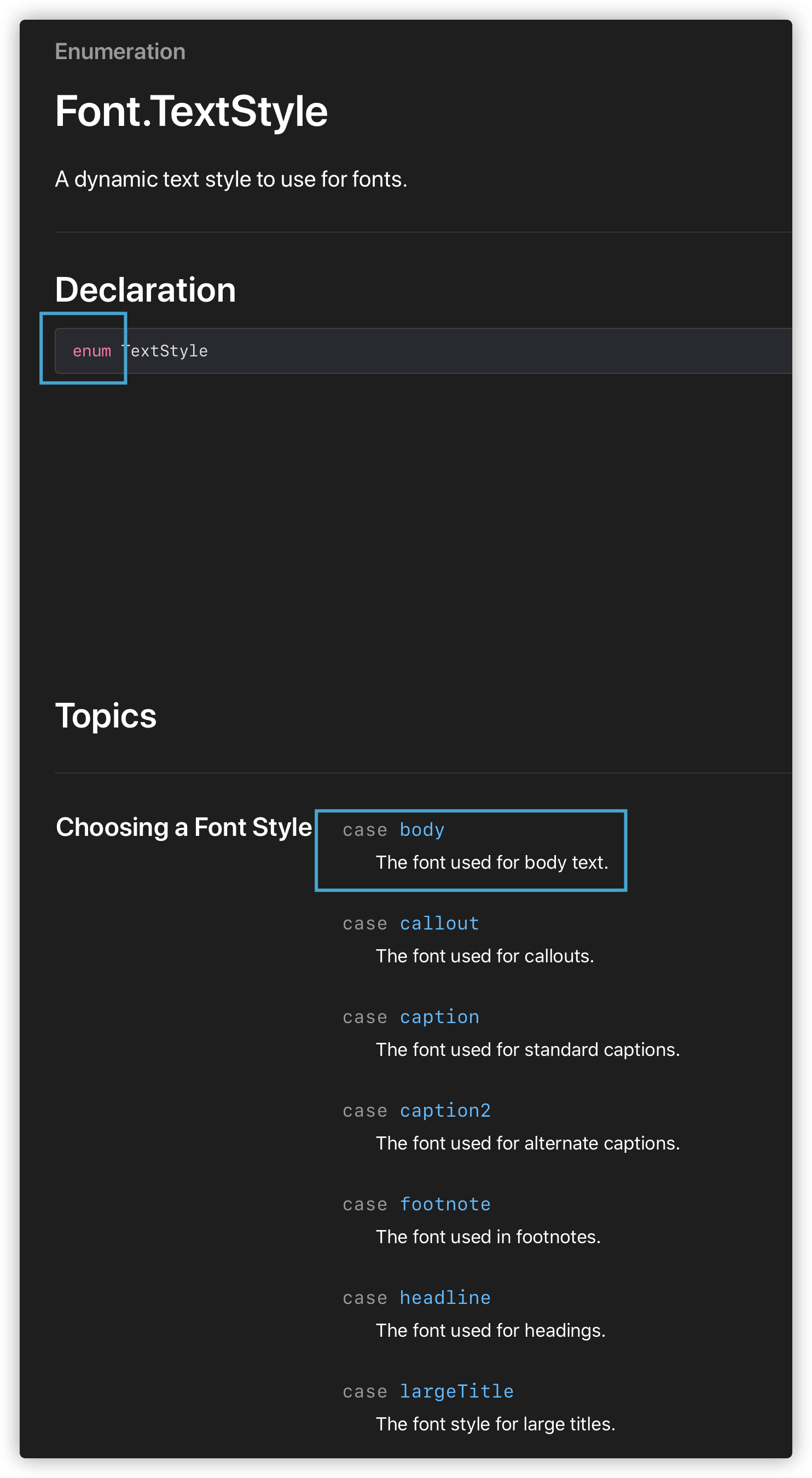
代码本身的疑问:第一张图的代码是按照书中教程说的写的,但疑惑很多,从上至下: 1 、struct 结构不是不能继承的吗?为什么会有个 View 在后面。 2 、var body 后面花括号一大段,这个变量是计算变量吗?计算变量不应该是通过计算返回一个值吗。 3 、Text.fontWeight(.thin)该如何理解,我的理解是对 Text 对象的属性 /方法调用,为何里面又有个.thin,这到底是属性还是什么,直接通过点号就能设置属性吗。 4 、Text 对象先用点号调用了 fontWeight,然后直接接着后面又点号调用了 padding(),这个 padding 是在 fontWeight 的基础上调用的吗,padding 应该不属于 fontWeight 吧?他们可以混在一起调用的吗 上图代码与文档结合后,理解文档的疑问:第二张图,是上图代码调用的 fontWeight 。 1 、首先,这个 Declaration 声明是如何理解的,没看懂要怎么使用;其次,下面全部是常量属性,比如名为 thin 的 Font.Weight (类型?结构?),这又该如何使用。。。 2 、同样的,下图是 TextStyle 的文档,怎么又变成了一个枚举,这个 Declaration 和 case 又是要人怎么用。。。
|
| Posted: 17 Apr 2021 04:50 AM PDT 本人毕业开始就很喜欢体验电子设备,目前没有体验过的手机品牌剩下 vivo 、魅族还有一加。 目前在魅族 18 跟一加 9 两个徘徊,想听听建议 |
| Posted: 17 Apr 2021 04:46 AM PDT 基本翻倍,幸亏有个 nas |
| Posted: 17 Apr 2021 04:40 AM PDT 题主是 UI 转的前端开发,有差不多两年多的经验,趁着金三银四工作机会多夸大了经验面了几家发现自己水平还是太一般了,放低了要求入职了一非互联网公司开发内部 ERP 项目,技术栈是 React + Typescript,用的阿里的 UmiJS 。 同时入职的还有一位前端开发,刚入职问了一下也是 UI 转的前端,也差不多两年经验。因为想了解了解水平好配合后面的工作,所以就问了几句技术问题。 大概是这样问的:
在初步了解过后,题主觉得这个前端水平应该可以,后续合作应该不会有大麻烦。直到真正开始干活时,彻底暴露了。 在他接到第一个任务不久后,我就感觉有猫腻。问我子组件怎么改变父组件的 props 的, 我觉得可能是因为不是很熟悉 React,而且这个技术点不是很难,Vue 也有这样的使用情景,就找了 React 官方文档状态提升的案例给他看一下。他看了大约半个小时后,又折回问我,要如何实现这个功能。我问你知道什么是状态提升吗,他说知道,然后我粗略看了一下代码,好家伙,就多嵌套了一层组件,就不知道怎么状态提升了。无奈,题主只好一行一行代码手敲给他看。 之后发生的事就越来越离谱了。
后面当然是完不成任务了,从入职开始做了快一个月的功能,最后由我来花了一天半时间给他搽屁股。发这篇主题无他,就为了倒倒苦水,发泄发泄压抑的情绪。 |
| Posted: 17 Apr 2021 03:45 AM PDT 有一套闲置 50 平的小公寓,大约能租 3000 每月左右。 在不出租的情况下,有没办法创造跟月租相当的被动收入? 我脑袋笨,只想到把他变成机房挖矿,不过: 1. 没挖过,没经验,对设备投入等也不了解 2. 公寓电费贵,我这要 1.1 元 /度 大家有没其它好主意? |
| Posted: 17 Apr 2021 03:44 AM PDT 日志在 /var/crash/foo/bar_vmcore,是内核崩溃时系统运行时的 snapshot,文章讲的一般都是如何 bar_vmcore.txt ,而讲如何分析这个文件的的非常少,而且听说是比较难的,好像还得懂点 C 和汇编吧。不知道大家有啥经验没? |
| Posted: 17 Apr 2021 03:00 AM PDT 有个疑问,MySQL 在有索引的情况下,如果数据达到一定的量级,查询同样也会有性能问题,那么如果只查最近的数据呢?比如 id 是自增长的,只查最近几十条,这种情况是否查询比较快,还是说查询性能只跟数据量和索引有关,跟是否最近的数据没有关系。 谢谢! |
| HTML、CSS、JS 要掌握到什么程度才可以学习 Vue? Posted: 17 Apr 2021 02:40 AM PDT 菜狗运维开发,只会写点 Python Web,想学学 Vue 做个全栈能好找工作一点。但是我现在连最基本的 HTML CSS JS 都从来没学过,不知道这三门技术分别要掌握到哪种程度,才能学 Vue ?我觉得我能有能独立做个 xxx 管理平台的水平就够找工作了。我也试过直接写 Vue,结果只会抄代码,却不知道为啥,我连 div 都不明白干啥的。另外大家有啥学习资料能分享一下吗? |
| @Transactional VS @Transactional(rollbackFor = Exception.class) Posted: 17 Apr 2021 02:37 AM PDT 到底什么场景会使用到 额外阅读 |
| [再硬核 | 5 千字长文+ 30 张图解 | 陪你手撕 STL 空间配置器源码] Posted: 17 Apr 2021 02:33 AM PDT STL 源码剖析-空间配置器大家好,我是小贺。 1 、前言天下大事,必作于细。 源码之前,了无秘密。 你清楚下面这几个问题吗?
这篇,我们就来回答这些问题。
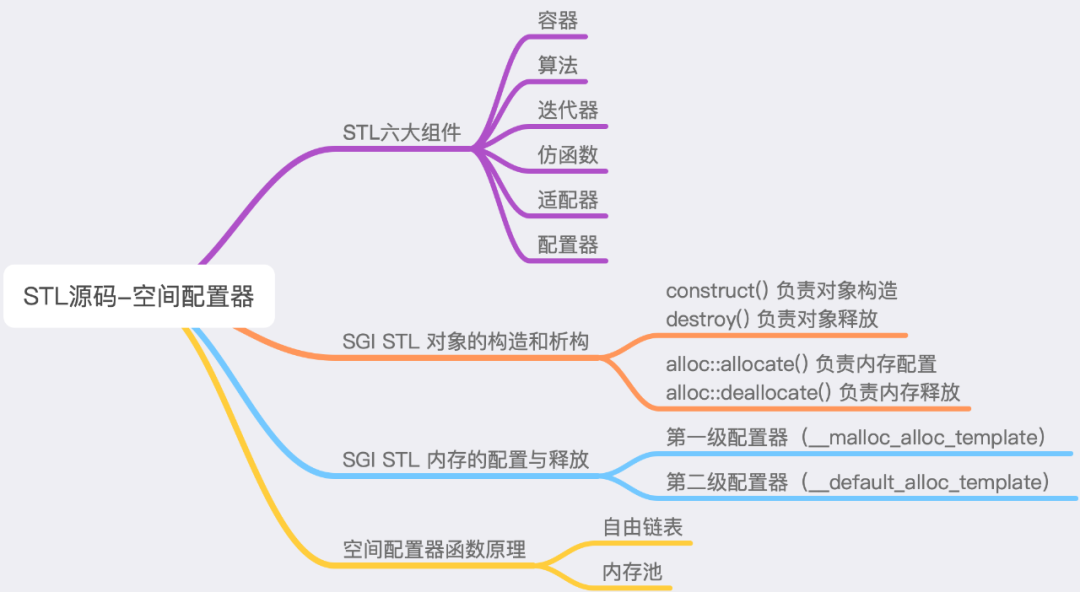
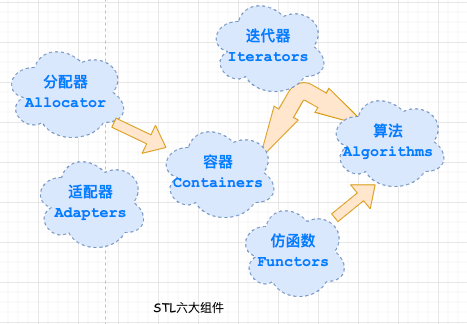
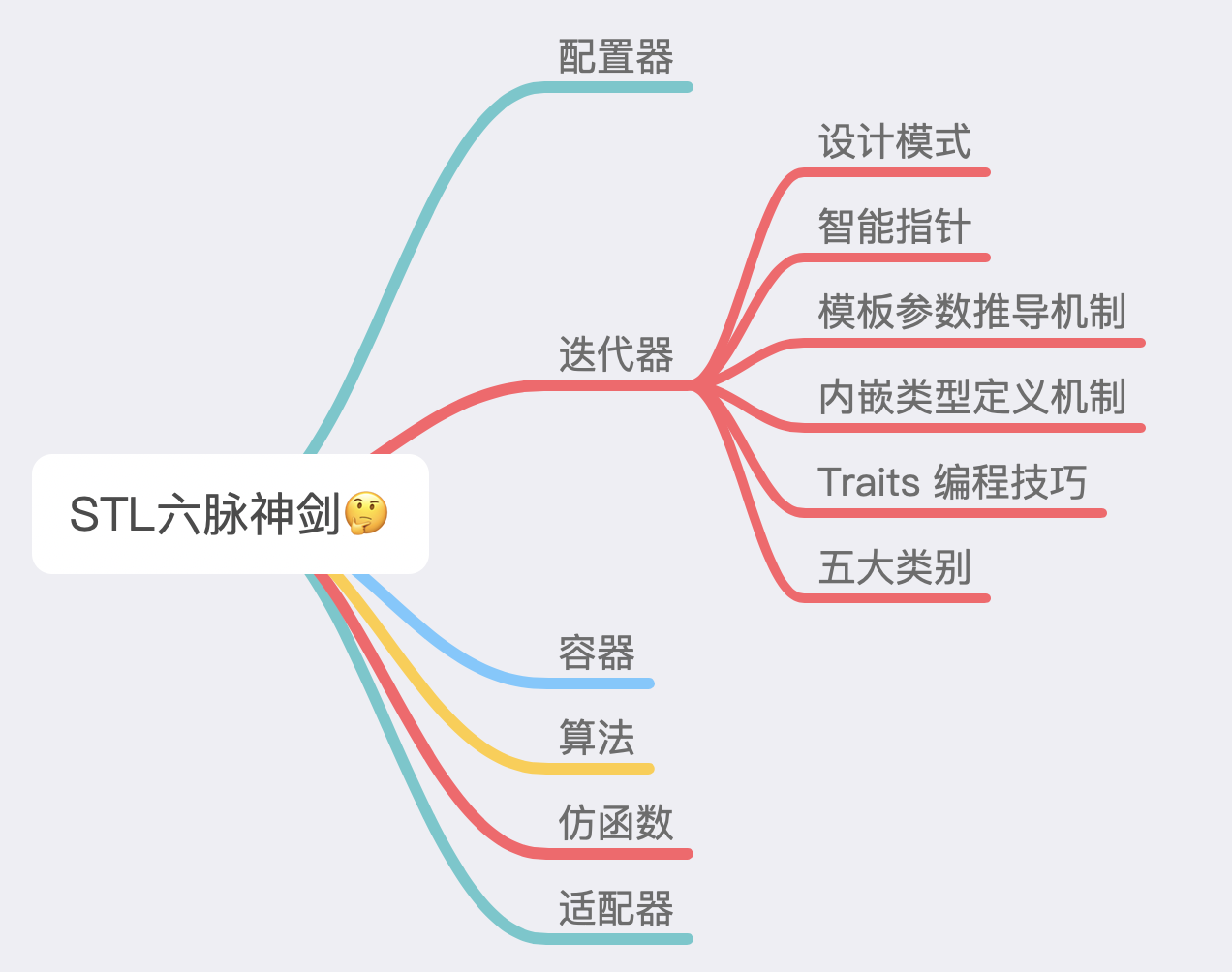
2 、STL 六大组件在深入配置器之前,我们有必要了解下 STL 的背景知识: 标准模板库(英文:Standard Template Library,缩写:STL ),是一个 C++ 软件库。 STL 的价值在于两个方面,就底层而言,STL 带给我们一套极具实用价值的零部件以及一个整合的组织;除此之外,STL 还带给我们一个高层次的、以泛型思维 (Generic Paradigm) 为基础的、系统化的"软件组件分类学"。 STL 提供六大组件,了解这些为接下来的阅读打下基础。
3 、何为空间配置器3.1 为何需要先了解空间配置器? 从使用 STL 层面而言,空间配置器并不需要介绍 ,因为容器底层都给你包装好了,但若是从 STL 实现角度出发,空间配置器是首要理解的。 作为 STL 设计背后的支撑,空间配置器总是在默默地付出着。为什么你可以使用算法来高效地处理数据,为什么你可以对容器进行各种操作,为什么你用迭代器可以遍历空间,这一切的一切,都有"空间配置器"的功劳。 3.2 SGI STL 专属空间配置器 SGI STL 的空间配置器与众不同,且与 STL 标准规范不同。 其名为 alloc,而非 allocator 。 虽然 SGI 也配置了 allocatalor,但是它自己并不使用,也不建议我们使用,原因是效率比较感人,因为它只是在基层进行配置 /释放空间而已,而且不接受任何参数。 SGI STL 的每一个容器都已经指定缺省的空间配置器是 alloc 。
在 C++ 里,当我们调用 new 和 delete 进行对象的创建和销毁的时候,也同时会有内存配置操作和释放操作: 这其中的 new 和 delete 都包含两阶段操作:
为了精密分工,STL allocator 决定将这两个阶段操作区分开来。
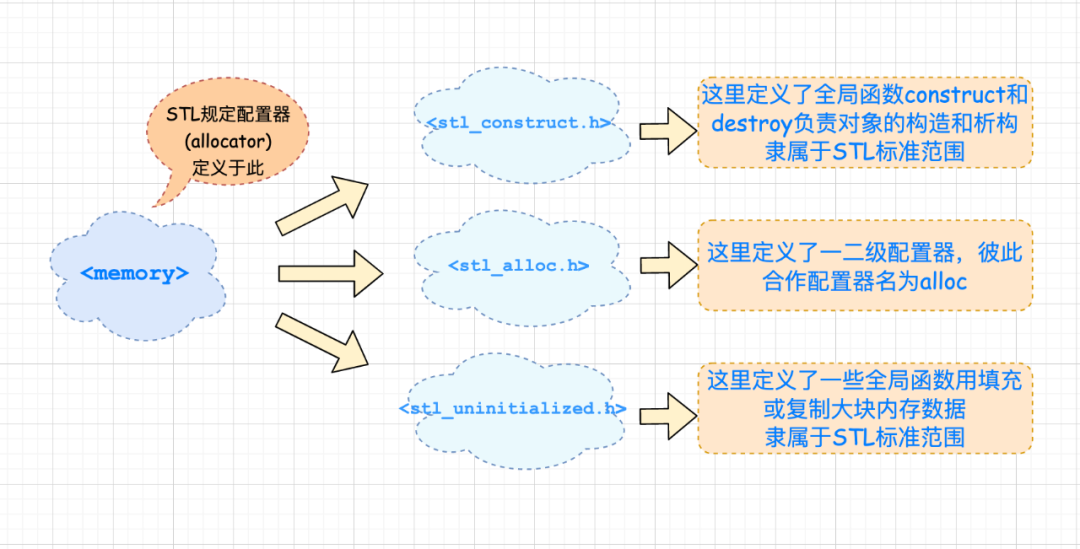
STL 配置器定义在头文件,如下图直观的描述了这一框架结构:
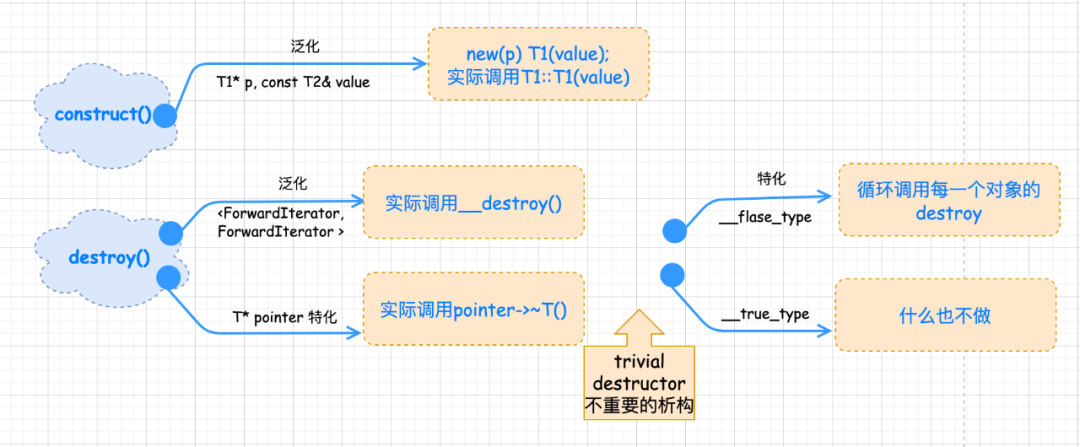
4 、构造和析构源码我们知道,程序内存的申请和释放离不开基本的构造和析构基本工具:construct() 和 destroy() 。 在 STL 里面,construct() 函数接受一个指针 P 和一个初始值 value,该函数的用途就是将初值设定到指针所指的空间上。 destroy() 函数有两个版本,第一个版本接受一个指针,准备将该指针所指之物析构掉。直接调用析构函数即可。 第二个版本接受 first 和 last 两个迭代器,将[first,last)范围内的所有对象析构掉。
其中 destroy() 只截取了部分源码,全部实现还考虑到特化版本,比如判断元素的数值类型 (value type) 是否有 trivial destructor 等限于篇幅,完整代码请参阅《 STL 源码剖析》。 再来张图吧,献丑了。
5 、内存的配置与释放前面所讲都是对象的构造和析构,接下来要讲的是对象构造和析构背后的故事—(内存的分配与释放),这块是才真正的硬核,不要搞混了哦。 5.1 真· alloc 设计奥义 对象构造和析构之后的内存管理诸项事宜,由 <stl_alloc.h> 一律负责。SGI 对此的设计原则如下:
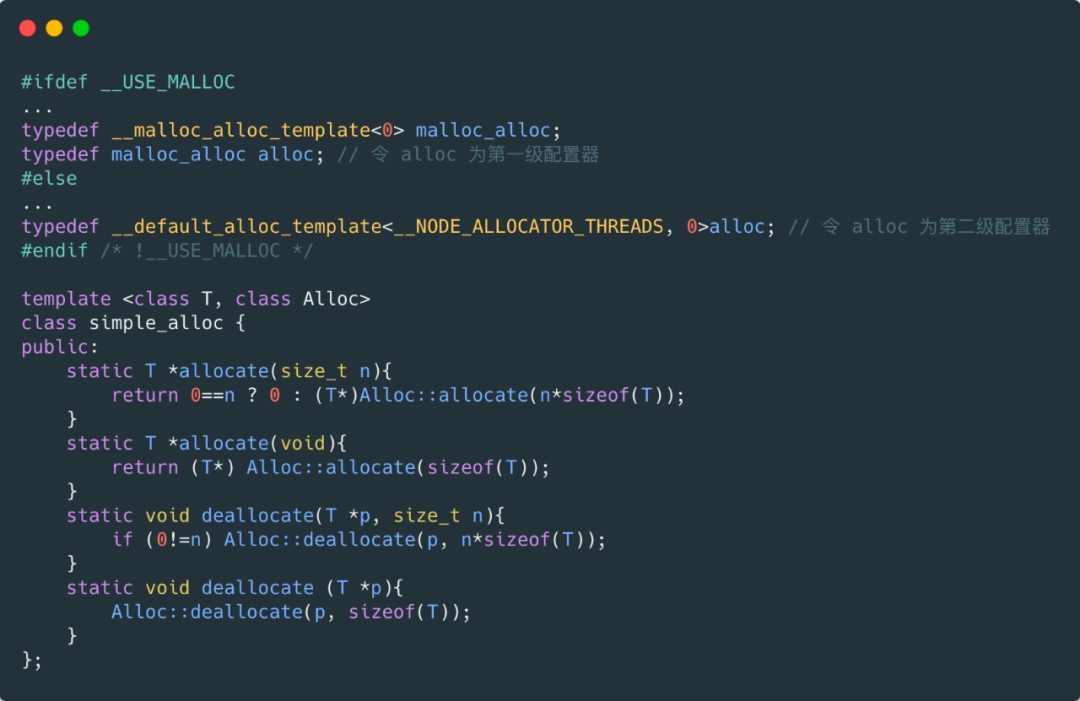
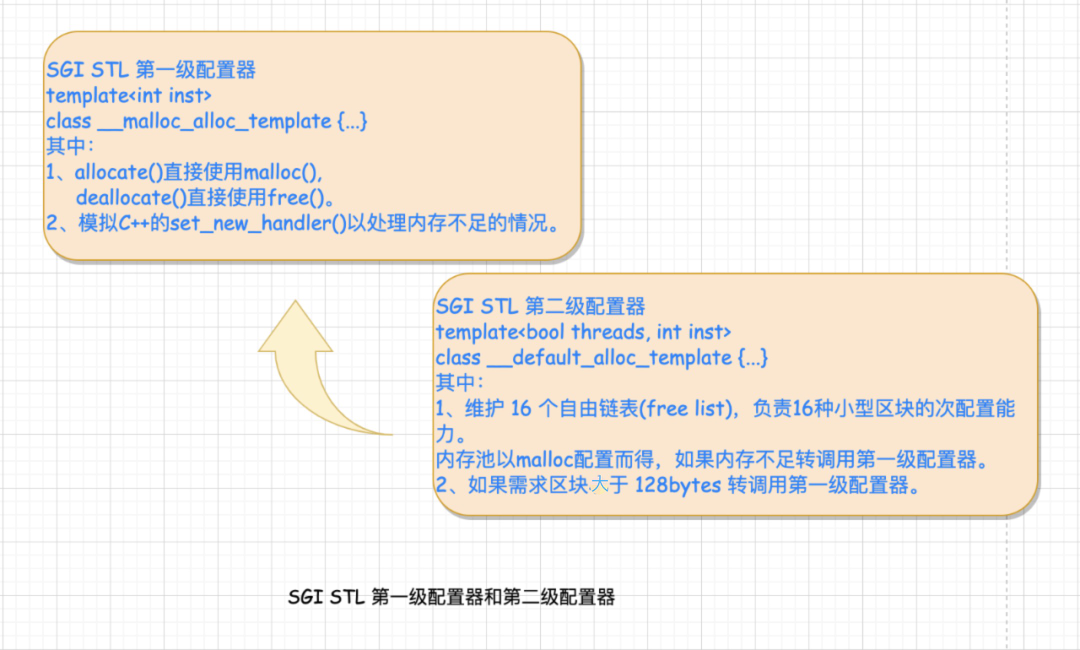
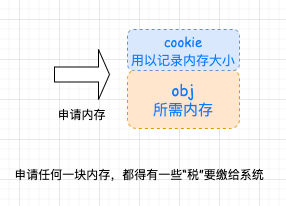
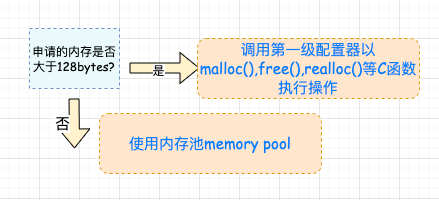
考虑到小型区块可能造成的内存破碎问题,SGI 为此设计了双层级配置器。当配置区块超过 128bytes 时,称为足够大,使用第一级配置器,直接使用 malloc() 和 free()。 当配置区块不大于 128bytes 时,为了降低额外负担,直接使用第二级配置器,采用复杂的 memory pool 处理方式。 无论使用第一级配接器(__malloc_alloc_template )或是第二级配接器(__default_alloc_template ),alloc 都为其包装了接口,使其能够符合 STL 标准。 其中, __malloc_alloc_template 就是第一级配置器; __default_alloc_template 就是第二级配置器。 这么一大堆源码看懵了吧,别着急,请看下图。
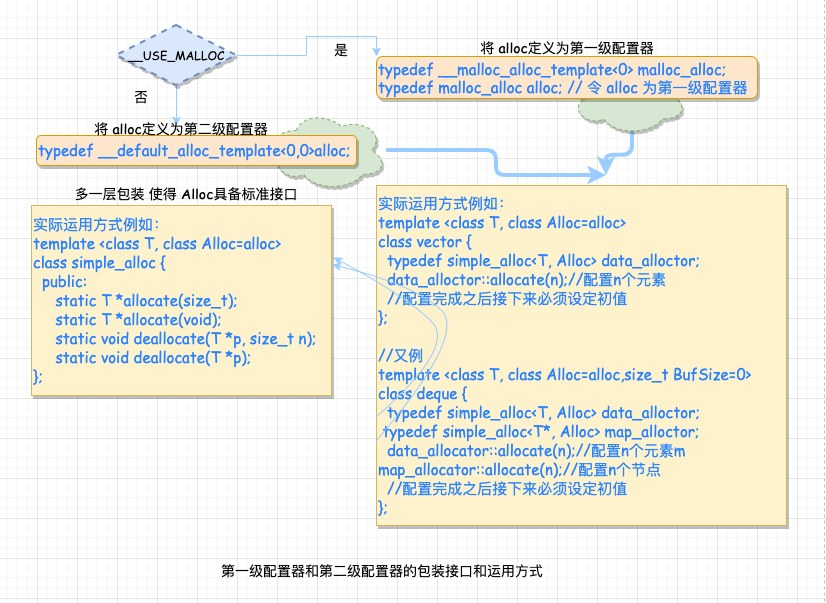
其中 SGI STL 将配置器多了一层包装使得 Alloc 具备标准接口。
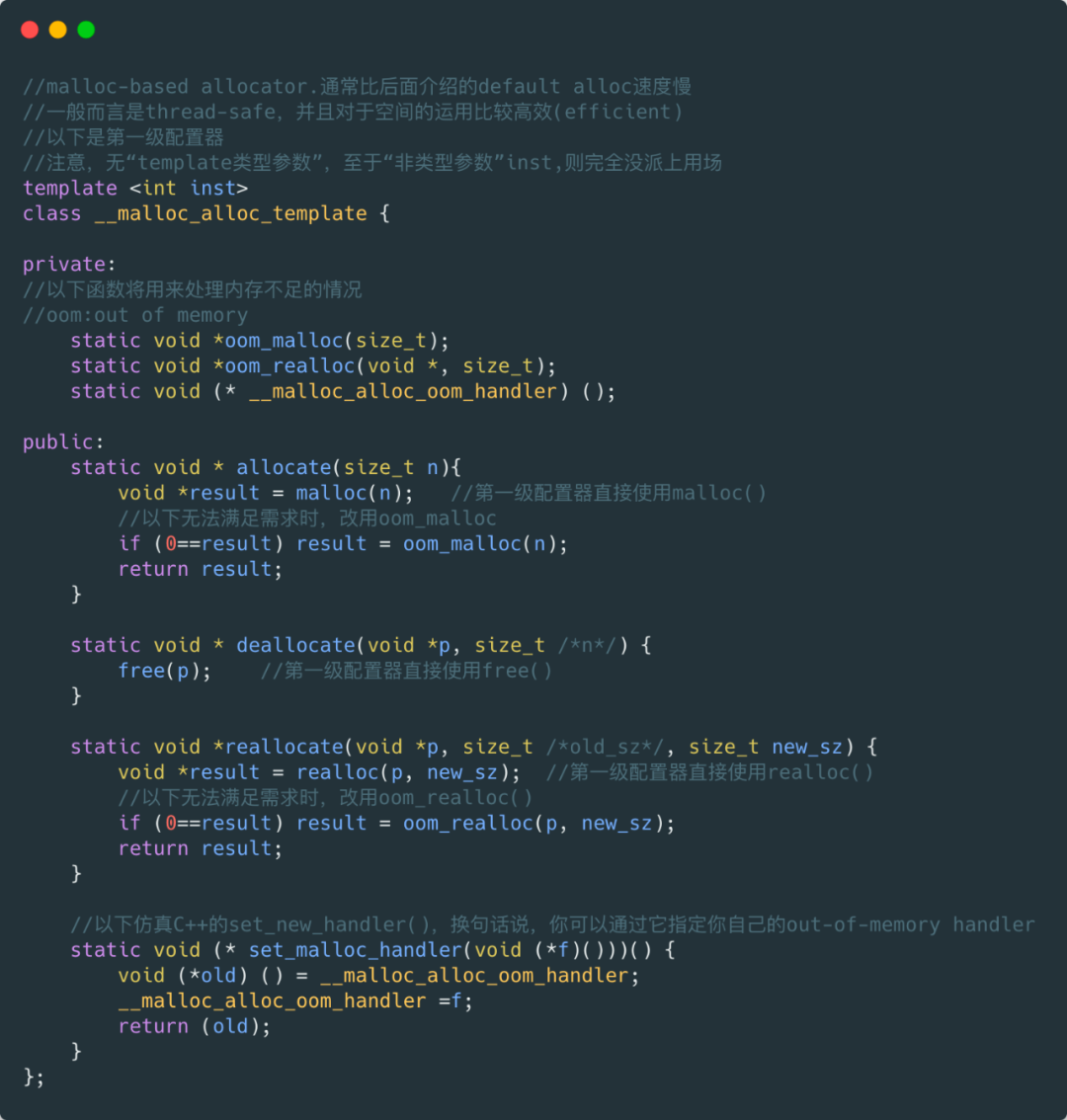
6 、alloc 一级配置器源码解读这里截取部分(精华)解读 ( 1 )第一级配置器以 malloc(), free(), realloc() 等 C 函数执行实际的内存配置、释放和重配置操作,并实现类似 C++ new-handler 的机制(因为它并非使用 ::operator new 来配置内存,所以不能直接使用 C++ new-handler 机制)。 ( 2 ) SGI 第一级配置器的 allocate() 和 reallocate() 都是在调用 malloc() 和 realloc() 不成功后,改调用 oom_malloc() 和 oom_realloc()。
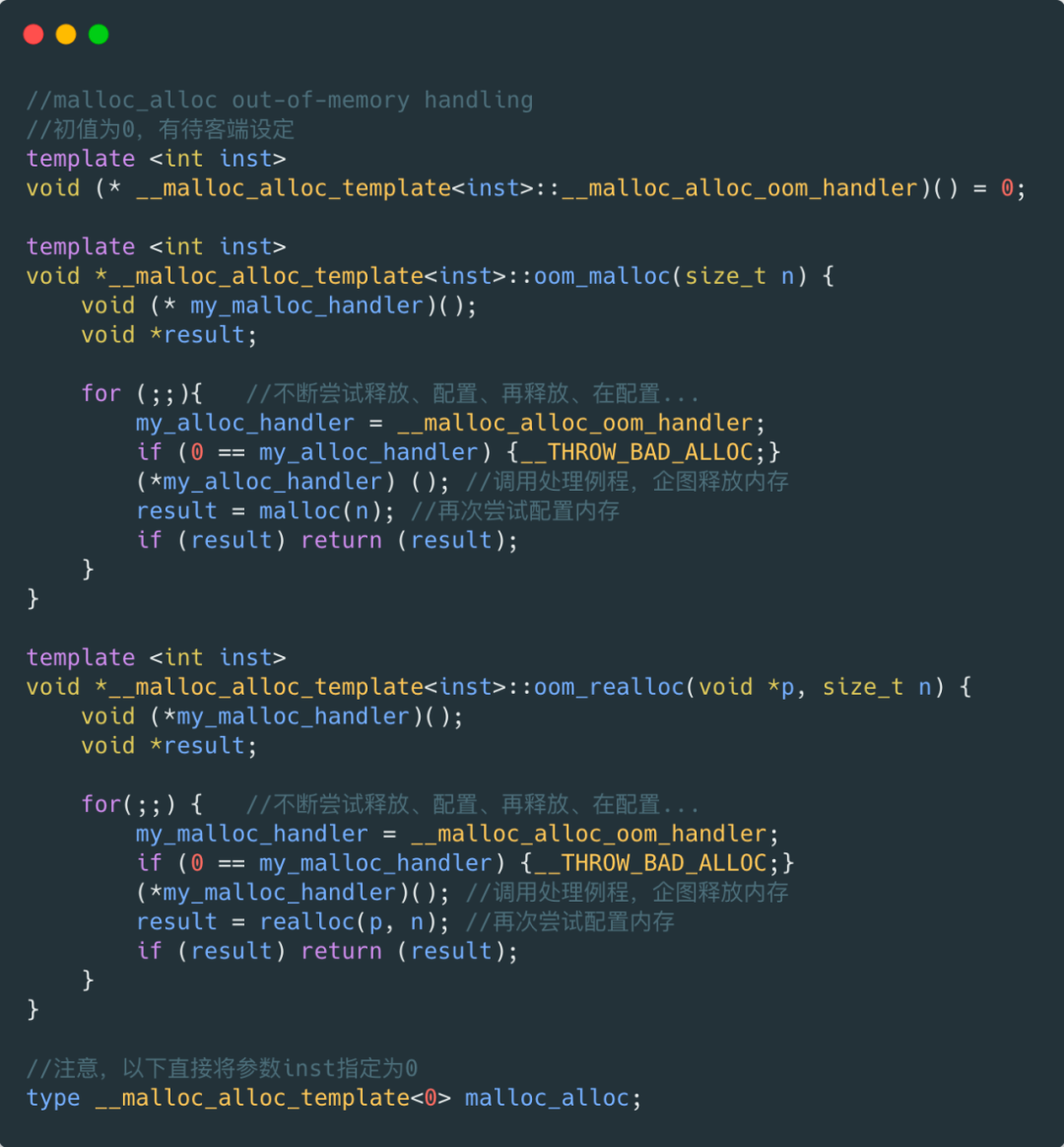
( 3 ) oom_malloc() 和 oom_realloc() 都有内循环,不断调用"内存不足处理例程",期望某次调用后,获得足够的内存而圆满完成任务,哪怕有一丝希望也要全力以赴申请啊,如果用户并没有指定"内存不足处理程序",这个时候便无力乏天,真的是没内存了,STL 便抛出异常。或调用 exit(1) 终止程序。
7 、alloc 二级配置器源码解读照例,还是截取部分(精华)源码解读。看累了嘛,远眺歇会,回来继续看,接下来的这部分,将会更加的让我们为大师的智慧折服! 第二级配置器多了一些机制,专门针对内存碎片。内存碎片化带来的不仅仅是回收时的困难,配置也是一个负担,额外负担永远无法避免,毕竟系统要划出这么多的资源来管理另外的资源,但是区块越小,额外负担率就越高。
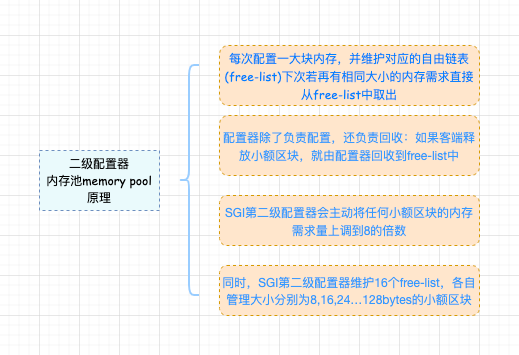
7.1 SGI 第二级配置器到底解决了多少问题呢? 简单来说 SGI 第二级配置器的做法是:sub-allocation (层次架构): 前面也说过了,SGI STL 的第一级配置器是直接使用 malloc(),free(), realloc() 并配合类似 C++ new-handler 机制实现的。第二级配置器的工作机制要根据区块的大小是否大于 128bytes 来采取不同的策略:
继续跟上节奏,上面提到了 memory pool,相信程序员朋友们很熟悉这个名词了,没错,这就是二级配置器的精髓所在,如何理解?请看下图:
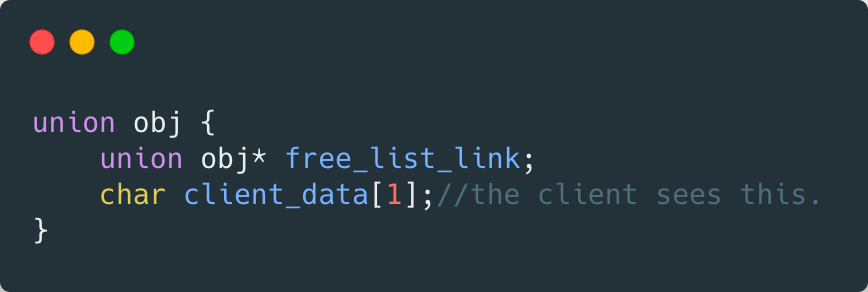
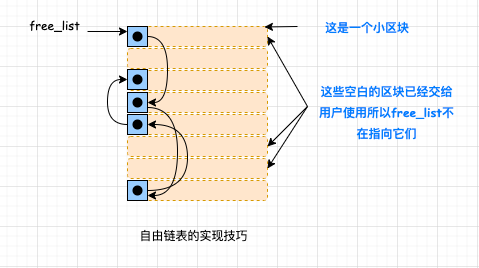
有了内存池,是不是就可以了,当然没有这么简单。上图中还提到了自由链表,这个又是何方神圣? 我们来一探究竟! 7.2 自由链表自由在哪?又该如何维护呢? 我们知道,一方面,自由链表中有些区块已经分配给了客端使用,所以 free_list 不需要再指向它们;另一方面,为了维护 free-list,每个节点还需要额外的指针指向下一个节点。 那么问题来了,如果每个节点有两个指针?这不就造成了额外负担吗?本来我们设计 STL 容器就是用来保存对象的,这倒好,对象还没保存之前,已经占据了额外的内存空间了。那么,有方法解决吗?当然有!再来感受一次大师的智慧! ( 1 )在这之前我们先来了解另一个概念——union (联合体 /共用体),对 union 已经熟悉的读者可以跳过这一部分的内容;如果忘记了也没关系,趁此来回顾一下: ( a )共用体是一种特殊的类,也是一种构造类型的数据结构。 ( b )共用体表示几个变量共用一个内存位置,在不同的时间保存不同的数据类型和不同长度的变量。 ( c )所有的共用体成员共用一个空间,并且同一时间只能储存其中一个成员变量的值。例如如下:
一个 union 只配置一个足够大的空间以来容纳最大长度的数据成员,以上例而言,最大长度是 double 类型, 所以 ChannelManager 的空间大小就是 double 数据类型的大小。在 C++ 里,union 的成员默认属性页为 public 。union 主要用来压缩空间,如果一些数据不可能在同一时间同时被用到,则可以使用 union 。 ( 2 )了解了 union 之后,我们可以借助 union 的帮助,先来观察一下 free-list 节点的结构
来深入了解 free_list 的实现技巧,请看下图。
在 union obj 中,定义了两个字段,再结合上图来分析: 从第一个字段看,obj 可以看做一个指针,指向链表中的下一个节点; 从第二个字段看,obj 可以也看做一个指针,不过此时是指向实际的内存区。 一物二用的好处就是不会为了维护链表所必须的指针而造成内存的另一种浪费,或许这就是所谓的自由奥义所在!大师的智慧跃然纸上。 7.3 第二级配置器的部分实现内容 到这里,我们已经基本了解了第二级配置器中 free_list 的工作原理了。附上第二级配置器的部分实现内容源码:
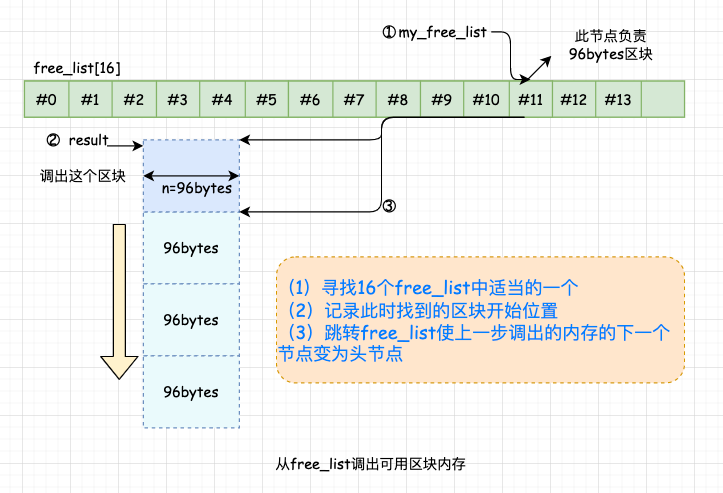
太长了吧,看懵逼了,没关系,请耐心接着往下看。 8 、空间配置器函数 allocate 源码解读我们知道第二级配置器拥有配置器的标准接口函数 allocate()。此函数首先判断区块的大小,如果大于 128bytes –> 调用第一级配置器;小于 128bytes–> 就检查对应的 free_list (如果没有可用区块,就将区块上调至 8 倍数的边界,然后调用 refill(), 为 free list 重新填充空间。 8.1 空间申请 调用标准接口函数 allocate():
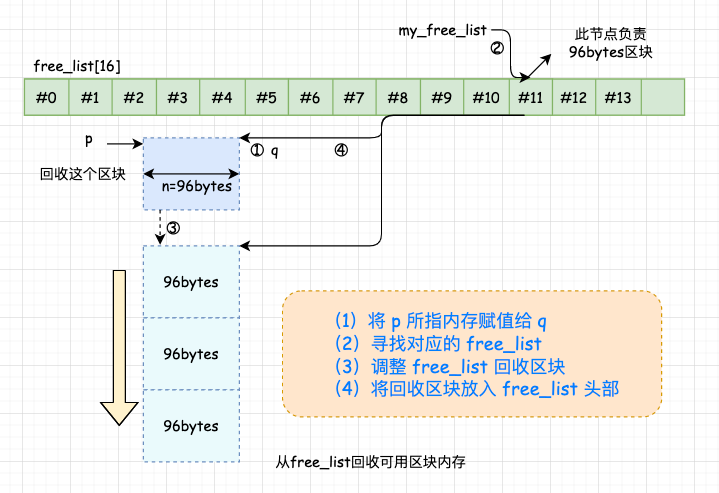
NOTE:每次都是从对应的 free_list 的头部取出可用的内存块。然后对 free_list 进行调整,使上一步拨出的内存的下一个节点变为头结点。 8.2 空间释放 同样,作为第二级配置器拥有配置器标准接口函数 deallocate()。该函数首先判断区块大小,大于 128bytes 就调用第一级配置器。小于 128 bytes 就找出对应的 free_list,将区块回收。
NOTE:通过调整 free_list 链表将区块放入 free_list 的头部。 区块回收纳入 free_list 的操作,如图所示: 8.3 重新填充 free_lists ( 1 )当发现 free_list 中没有可用区块时,就会调用 refill() 为 free_list 重新填充空间; ( 2 )新的空间将取自内存池(经由 chunk_alloc() 完成); ( 3 )缺省取得 20 个新节点(区块),但万一内存池空间不足,获得的节点数可能小于 20 。
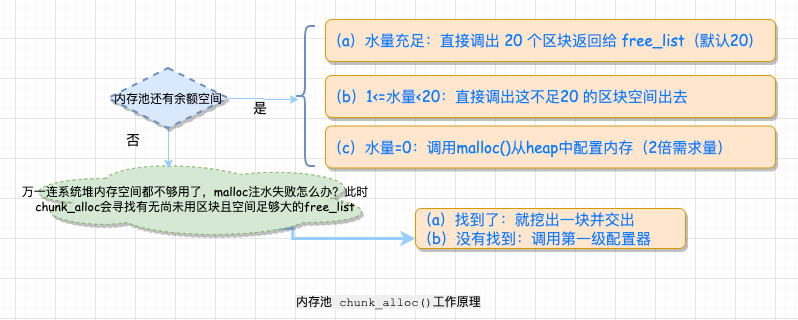
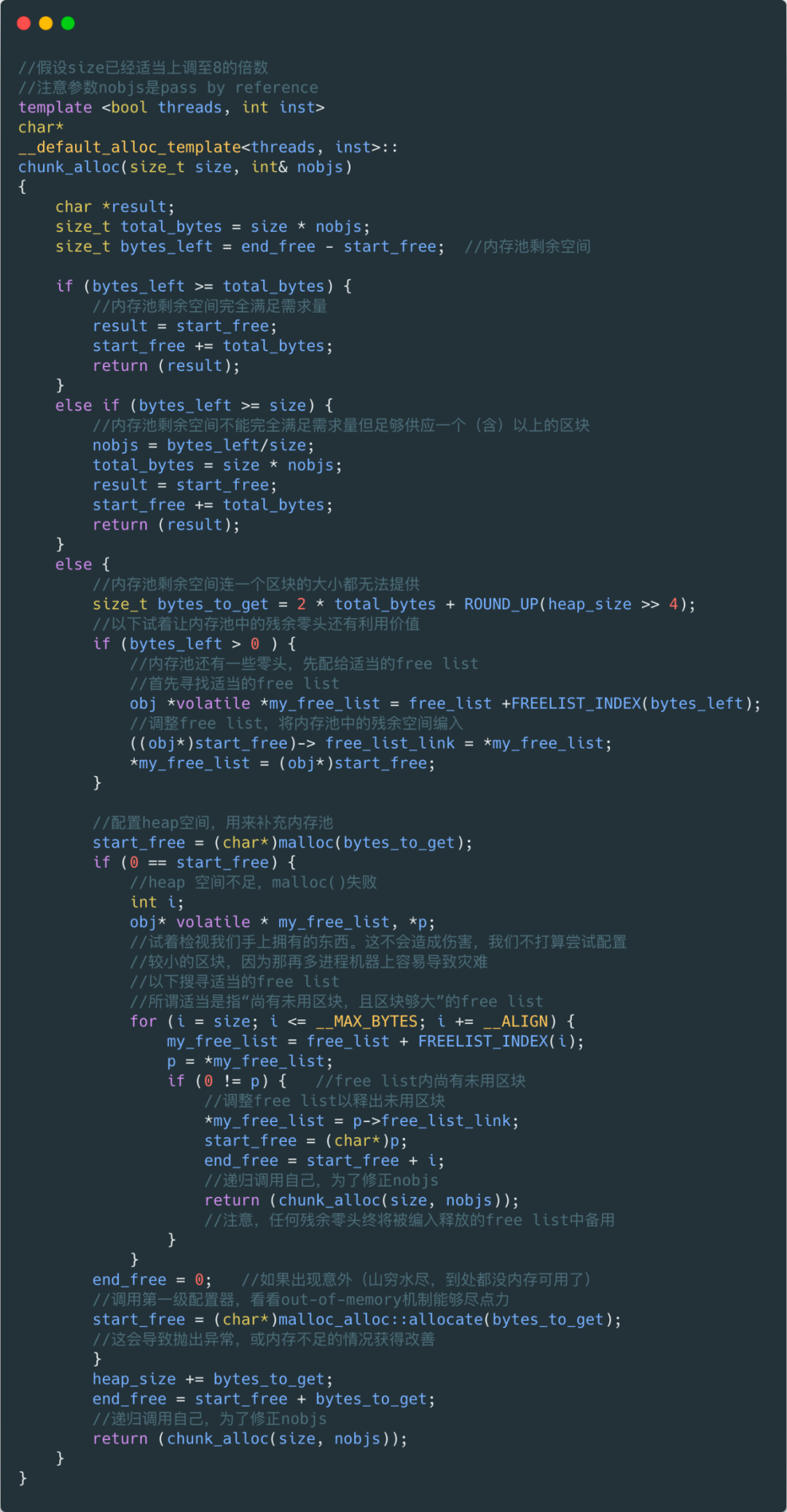
8.4 内存池( memory pool ) 唔…在前面提到了 memory pool,现在终于轮到这个大 boss 上场。 首先,我们要知道从内存池中取空间给 free_list 使用,是 chunk_alloc() 在工作,它是怎么工作的呢? 我们先来分析 chunk_alloc() 的工作机制: chunk_alloc() 函数以 end_free – start_free 来判断内存池的"水量"(哈哈,很形象的比喻)。 具体逻辑都在下面的图里了,很形象吧。
如果第一级配置器的 malloc() 也失败了,就发出 bad_alloc 异常。 说了这么多来看一下 STL 的源码吧。
NOTE:上述就是 STL 源码当中实际内存池的操作原理,我们可以看到其实以共用体串联起来共享内存形成了 free_list 的实质组成。 9 、本文小结STL 源码本身博大精深,还有很多精妙的设计等着大家去探索。 小贺本人才疏学浅,在这里也只是从自己的角度去写出自己的理解,不足之处希望对大家多多指出,互相讨论学习。 这篇肝了一个礼拜的文章,在周日的晚上终于写完了,文中所有的图都是自己一个个亲手画的,不画不知道,画完之后真心感觉不容易啊。 第一次写这种图解的文章,不知道读者朋友们喜不喜欢。如果反馈还不错的话,后面有时间会继续更新类型的图解文章。 参考文章: 《 STL 源码剖析-侯捷》 https://cloud.tencent.com/developer/article/1686585 https://dulishu.top/allocator-of-stl/ 10 、结尾如果觉得文章对你有帮助,欢迎分享给你的朋友,一键三连,谢谢你们,给各位小姐姐小哥哥们比心了。 我是 herongwei,是男人,就该对自己狠一点,我们下期见。 更多精彩🔭 宇宙中心五道口狗厂程序员,爱生活,好读书 🌱 热爱分享: 公众号『 herongwei 』 🤔 个人博客:herongwei.com 📫 微信:icoredump
关注公众号 [ herongwei ] ,后台回复 [大礼包] 即可获取白嫖后端技术知识+算法电子书~ 为了回馈读者,本公众号不定期会有送礼活动,敬请关注~ |
| Posted: 17 Apr 2021 02:26 AM PDT 嗯…楼主是一个电信本科生(打算以后做云计算方面的?)是打算自己玩的一个小项目,大概想实现的功能如下,请问各位有经验的大手子能否提供一些学习建议和实现方法 1.目的是实现实时视频的风格迁移 2.客户端是一个树莓派(配有显示器和摄像头),用来接收视频输入和进行视频输出。接收到的视频通过网线传输到本地的配有 GPU 的服务器上进行风格迁移,处理完之后再传回树莓派进行播放。(也不一定是树莓派,也可以是低功耗机器,总之就是低功耗) 3.希望能实现 2 个以上的并行处理 emmmmmmmm 算法其实不是想专攻的重点,目前的想法是将算法封装成 API 直接调用,摄像头似乎可以挂载成网络摄像头被服务器使用,但是封装和视频如何处理并传回实时播放没有头绪=。= 学过 C++和 python,不过应该还要学更多的语言吧=。= 感谢大佬们!!如果有相关的资料也麻烦您们评论一下喔 |
| Posted: 17 Apr 2021 01:52 AM PDT 收藏了很多短视频平台上的知识类的视频, 可是很多视频 App 的收藏功能很鸡肋。 收藏多了,发现 [搜索] 很麻烦。 收藏夹中居然不带搜索框给我用,而且标签也只有一级,甚至没有标签功能。 我想打标签,分门别类放在一些子目录中。 或者有办法导入到我的电脑中吗? |
| [超硬核 | 2 万字+20 图带你手撕 STL 序列式容器源码] Posted: 17 Apr 2021 12:27 AM PDT 超硬核 | 2 万字+20 图带你手撕 STL 序列式容器源码大家好,我是小贺,继续更新 STL 源码剖析。 前言源码之前,了无秘密。 上一篇,我们剖析了 STL 迭代器源码与 traits 编程技法, 这一篇我们来学习下容器。 在 STL 编程中,容器是我们经常会用到的一种数据结构,容器分为序列式容器和关联式容器。 两者的本质区别在于:序列式容器是通过元素在容器中的位置顺序存储和访问元素,而关联容器则是通过键 (key) 存储和读取元素。 本篇着重剖析序列式容器相关背后的知识点。
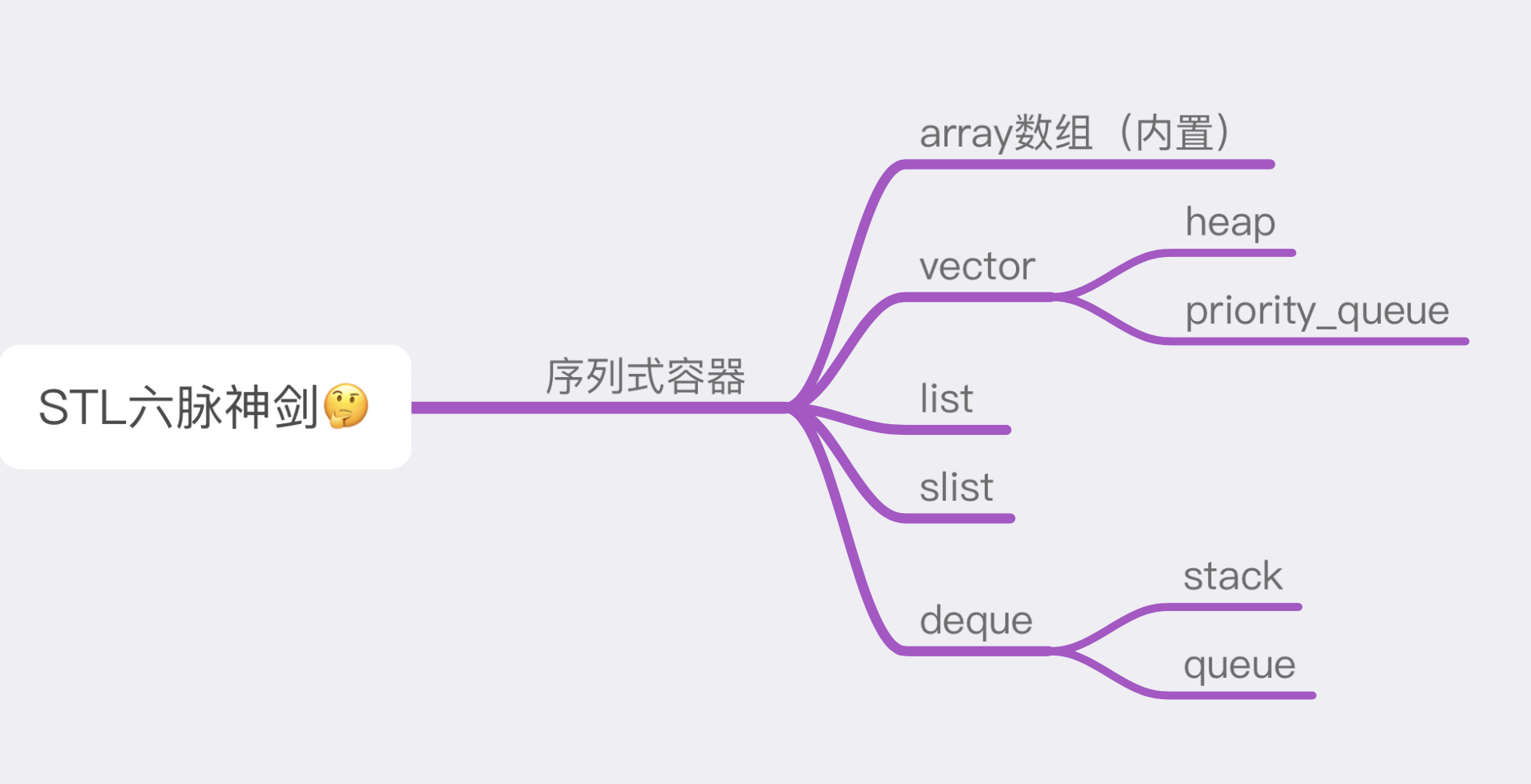
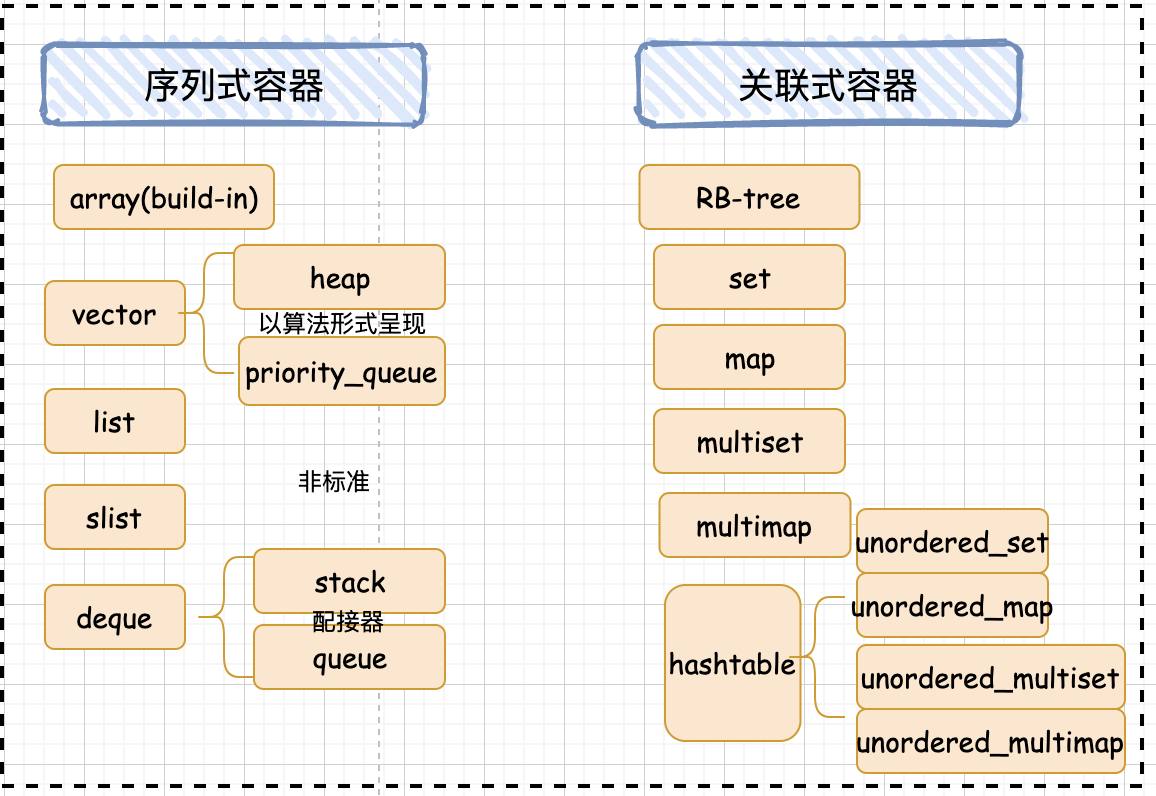
容器分类前面提到了,根据元素存储方式的不同,容器可分为序列式和关联式,那具体的又有哪些分类呢,这里我画了一张图来看一下。
限于篇幅,这篇文章小贺会来重点讲解一下经常使用到的那些容器,比如 vector,list,deque,以及衍生的栈和队列其背后核心的设计和奥秘,不多 BB, 马上就来分析。 vector写 C++ 的小伙伴们,应该对 vector 都非常熟悉了,vector 基本能够支持任何类型的对象,同时它也是一个可以动态增长的数组,使用起来非常的方便。 但如果我问你,知道它是如何做到动态扩容的吗?哎,是不是一时半会答不上来了,哈哈,没事,我们一起来看看。 vector 基本数据结构基本上,STL 里面所有的容器的源码都包含至少三个部分:
vector 也不例外,其实看了源码之后就发现,vector 相反是所有容器里面最简单的一种。 因为 vector 需要表示用户操作的当前数据的起始地址,结束地址,还需要其真正的最大地址。所以总共需要 3 个迭代器分别指向:数据的头(start),数据的尾(finish),数组的尾(end_of_storage)。 构造函数vector 有多个构造函数, 为了满足多种初始化。
我们看到,这里面,初始化满足要么都初始化成功, 要么一个都不初始化并释放掉抛出异常,异常机制这块拿捏的死死的呀。 因为 vector 是一种 class template, 所以呢,我们并不需要手动的释放内存, 生命周期结束后就自动调用析构从而释放调用空间,当然我们也可以直接调用析构函数释放内存。 属性获取下面的部分就涉及到了位置参数的获取, 比如返回 vector 的开始和结尾,返回最后一个元素,返回当前元素个数,元素容量,是否为空等。 这里需要注意的是因为 end() 返回的是 finish,而 finish 是指向最后一个元素的后一个位置的指针,所以使用 end() 的时候要注意。 push 和 pop 操作vector 的 push 和 pop 操作都只是对尾进行操作, 这里说的尾部是指数据的尾部。 当调用 push_back 插入新元素的时候,首先会检查是否有备用空间,如果有就直接在备用空间上构造元素,并调整迭代器 finish 。
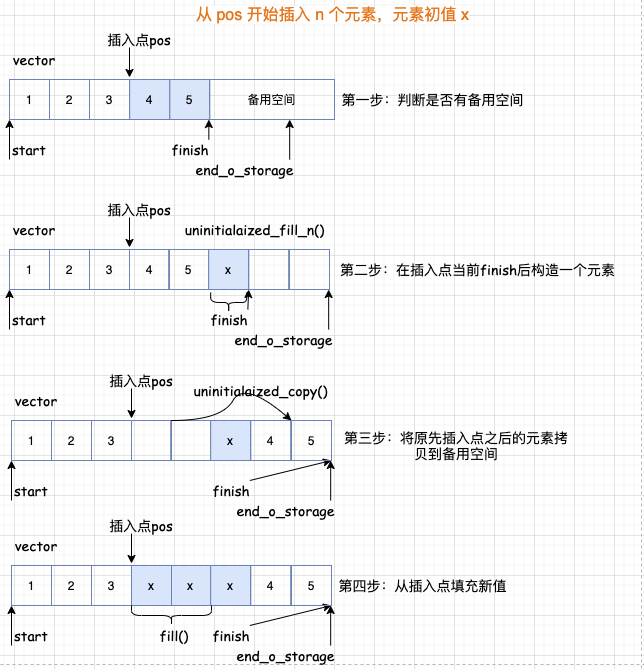
当如果没有备用空间,就扩充空间(重新配置-移动数据-释放原空间),这里则是调用了 insert_aux 函数。
在下面的 else 分支里面,我们看到了 vector 的动态扩容机制:如果原空间大小为 0 则分配 1 个元素,如果大于 0 则分配原空间两倍的新空间,然后把数据拷贝过去。
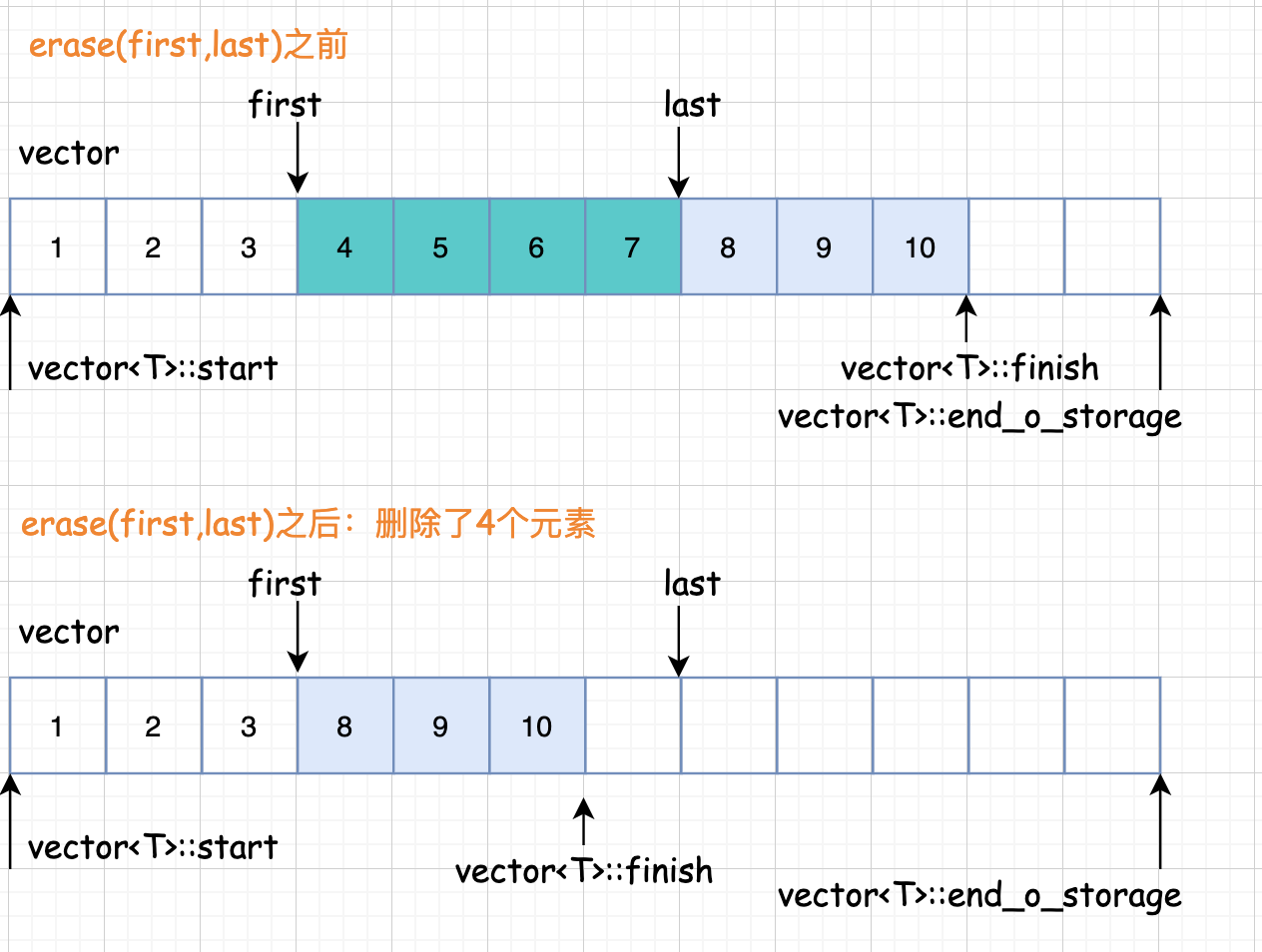
pop 元素 erase 删除元素erase 函数清除指定位置的元素, 其重载函数用于清除一个范围内的所有元素。实际实现就是将删除元素后面所有元素往前移动,对于 vector 来说删除元素的操作开销还是很大的,所以说 vector 它不适合频繁的删除操作,毕竟它是一个数组。 我们结合图解来看一下:
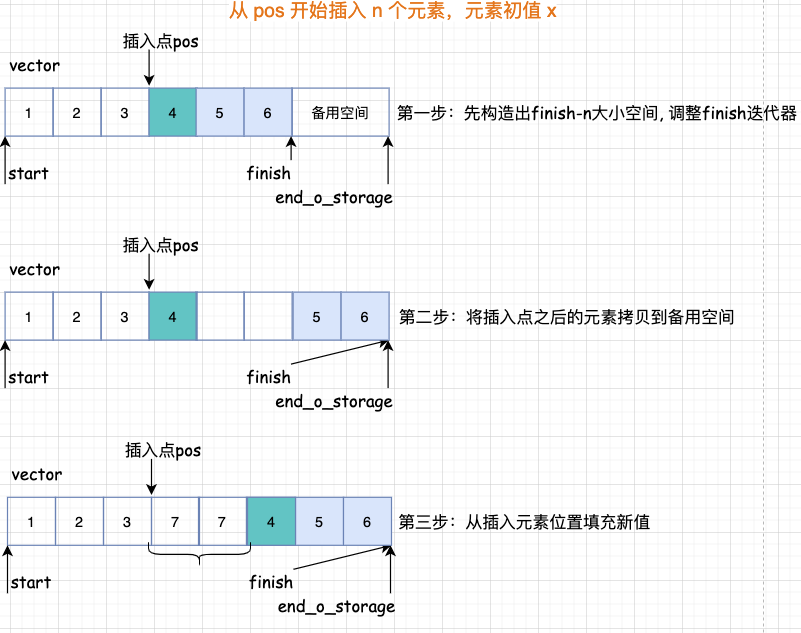
清楚范围内的元素,第一步要将 finish 迭代器后面的元素拷贝回去,然后返回拷贝完成的尾部迭代器,最后在删除之前的。 删除指定位置的元素就是实际就是将指定位置后面的所有元素向前移动, 最后析构掉最后一个元素。 insert 插入元素vector 的插入元素具体来说呢,又分三种情况: 1 、如果备用空间足够且插入点的现有元素多于新增元素; 2 、如果备用空间足够且插入点的现有元素小于新增元素; 3 、如果备用空间不够; 我们一个一个来分析。
如果备用空间不足
这里呢,要注意一个坑,就是所谓的迭代器失效问题。 通过图解我们就明白了,所谓的迭代器失效问题是由于元素空间重新配置导致之前的迭代器访问的元素不在了,总结来说有两种:
前面提到的一些全局函数,这里总结一下:
vector 总结到这里呢,vector 分析的就差不多了,最后提醒需要注意的是:vector 的成员函数都不做边界检查 (at 方法会抛异常),使用者要自己确保迭代器和索引值的合法性。 我们来总结一下 vector 的优缺点。 优点
缺点
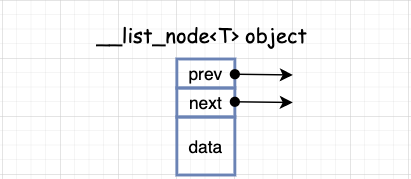
vector 的缺点也很明显, 在频率较高的插入和删除时效率就太低了 list好了,下面我们来看一下 list,list 是一种双向链表。 list 的设计更加复杂一点,好处是每次插入或删除一个元素,就配置或释放一个元素,list 对于空间的运用有绝对的精准,一点也不浪费。而且对于任何位置的元素插入或删除,list 永远是常数空间。 注意:list 源码里其实分了两个部分,一个部分是 list 结构,另一部分是 list 节点的结构。 那这里不妨思考一下,为什么 list 节点分为了两个部分,而不是在一个结构体里面呢? 也就是说为什么指针变量和数据变量分开定义呢? 如果看了后面的源码就晓得了,这里是为了给迭代器做铺垫,因为迭代器遍历的时候不需要数据成员的,只需要前后指针就可以遍历该 list 。
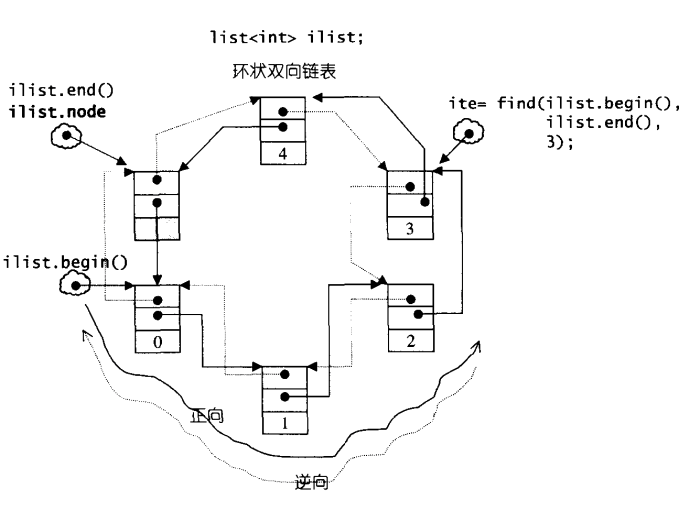
list 数据结构-节点__list_node 用来实现节点,数据结构中就储存前后指针和属性。 来瞅一瞅,list 的节点长啥样,因为 list 是一种双向链表,所以基本结构就是下面这个样子: 基本类型 构造函数 重载 list 结构list 自己定义了嵌套类型满足 traits 编程,list 迭代器是 bidirectional_iterator_tag 类型,并不是一个普通指针。
list 在定义 node 节点时, 定义的不是一个指针。这里要注意。 list 构造和析构函数实现构造函数前期准备: 每个构造函数都会创造一个空的 node 节点,为了保证我们在执行任何操作都不会修改迭代器。 list 默认使用 alloc 作为空间配置器,并根据这个另外定义了一个 list_node_allocator,目的是更加方便以节点大小来配置单元。 其中,list_node_allocator(n)表示配置 n 个节点空间。以下四个函数,分别用来配置,释放,构造,销毁一个节点。 基本属性获取list 的头插和尾插因为 list 是一个循环的双链表, 所以 push 和 pop 就必须实现是在头插入, 删除还是在尾插入和删除。 在 list 中,push 操作都调用 insert 函数, pop 操作都调用 erase 函数。 上面的两个插入函数内部调用的 insert 函数。 这里需要注意的是
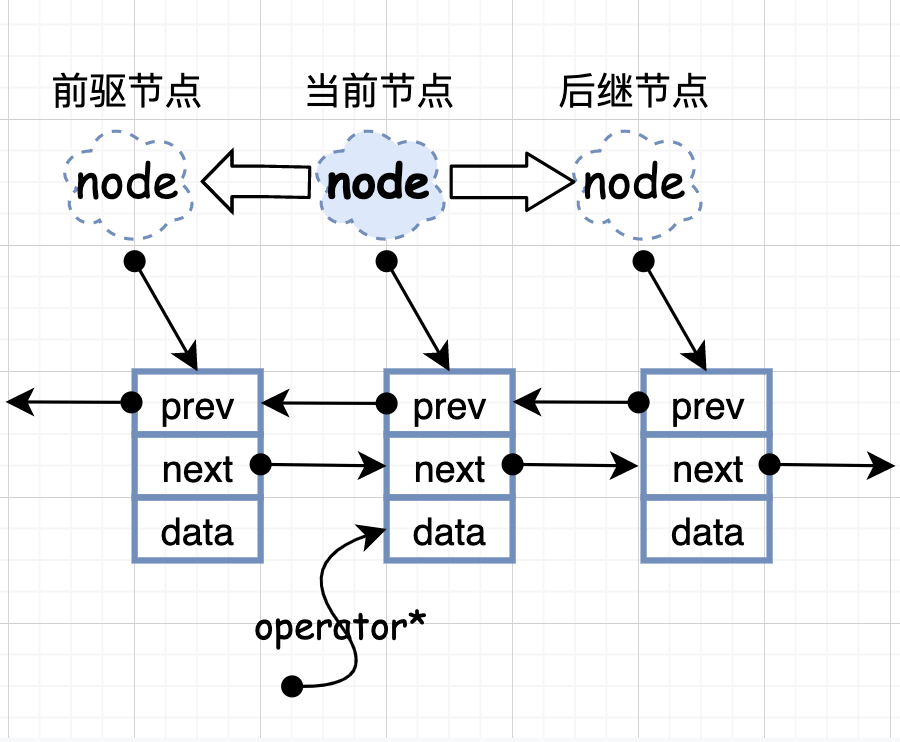
删除操作删除元素的操作大都是由 erase 函数来实现的, 其他的所有函数都是直接或间接调用 erase 。 list 是链表, 所以链表怎么实现删除, list 就在怎么操作:很简单,先保留前驱和后继节点, 再调整指针位置即可。 由于它是双向环状链表,只要把边界条件处理好,那么在头部或者尾部插入元素操作几乎是一样的,同样的道理,在头部或者尾部删除元素也是一样的。 list 内部提供一种所谓的迁移操作(transfer):将某连续范围的元素迁移到某个特定位置之前,技术上实现其实不难,就是节点之间的指针移动,只要明白了这个函数的原理,后面的 splice,sort,merge 函数也就一一知晓了,我们来看一下 transfer 的源码: 上面代码的七行分别对应下图的七个步骤,看明白应该不难吧。
另外 list 的其它的一些成员函数这里限于篇幅,就不贴出源码了,简单说一些注意点。 splice 函数: 将两个链表进行合并:内部就是调用的 transfer 函数。 merge 函数: 将传入的 list 链表 x 与原链表按从小到大合并到原链表中(前提是两个链表都是已经从小到大排序了). 这里 merge 的核心就是 transfer 函数。 reverse 函数: 实现将链表翻转的功能:主要是 list 的迭代器基本不会改变的特点, 将每一个元素一个个插入到 begin 之前。 sort 函数: list 这个容器居然还自己实现一个排序,看一眼源码就发现其实内部调用的 merge 函数,用了一个数组链表用来存储 2^i 个元素, 当上一个元素存储满了之后继续往下一个链表存储, 最后将所有的链表进行 merge 归并(合并), 从而实现了链表的排序。 赋值操作: 需要考虑两个链表的实际大小不一样时的操作
resize 操作: 重新修改 list 的大小。
clear 操作: 清除所有节点
remove 操作: 清除指定值的元素
unique 操作: 清除数值相同的连续元素,注意只有"连续而相同的元素",才会被移除剩一个。
感兴趣的读者可以自行去阅读体会。 好啦,list 的内容到这里就结束了。 list 总结我们来总结一下。 list 是一种双向链表。每个结点都包含一个数据域、一个前驱指针 prev 和一个后驱指针 next 。 由于其链表特性,实现同样的操作,相对于 STL 中的通用算法,list 的成员函数通常有更高的效率,内部仅需做一些指针的操作,因此尽可能选择 list 成员函数。 优点
缺点
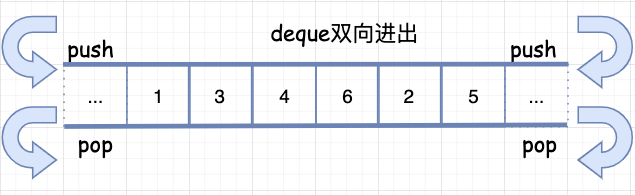
deque下面到了最硬核的内容了,接下来我们学习一下双端队列 deque 。 deque 的功能很强大。 首先来一张图吧。
上面就是 deque 的示例图,deque 和 vector 的最大差异一在于 deque 允许常数时间内对头端或尾端进行元素的插入或移除操作。 二在于 deque 没有所谓的容量概念,因为它是动态地以分段连续空间组合而成随时可以增加一块新的空间并拼接起来。 虽然 deque 也提供 随机访问的迭代器,但它的迭代器和前面两种容器的都不一样,其设计相当复杂度和精妙,因此,会对各种运算产生一定影响,除非必要,尽可能的选择使用 vector 而非 deque 。一一来探究下吧。 由于文字限制,后续内容大家可以点击这个链接: https://mp.weixin.qq.com/s/NcrnwsB2gjq9h7W2hIZ6PQ 最后,来自实践生产环境的一个体会:上面所列的所有容器的一个原则:为了避免拷贝开销,不要直接把大的对象直接往里塞,而是使用指针。 好了,本期的内容就到这里了,我们下期再见。 PS:看有多少人点赞,下期不定期更新关联式容器哦,先买个关子,下期有个硬核的内容带大家手撕红黑树源码,红黑树的应用可以说很广了,像 Java 集合中的 TreeSet 和 TreeMap 、STL 中的 set 和 map 、Linux 虚拟内存的管理都用到了哦。 参考 1 、《 STL 源码剖析》 2 、https://github.com/FunctionDou/STL 推荐阅读: 5 千字长文+ 30 张图解 | 陪你手撕 STL 空间配置器源码 万字长文炸裂!手撕 STL 迭代器源码与 traits 编程技法 更多精彩🔭 宇宙中心五道口狗厂程序员,爱生活,好读书 🌱 热爱分享: 公众号『 herongwei 』 🤔 个人博客:herongwei.com 📫 微信:icoredump
后台回复 [大礼包] 即可获取白嫖后端技术知识+算法电子书~ |
| [硬核 | 万字长文炸裂!手撕 STL 迭代器源码与 traits 编程技法] Posted: 16 Apr 2021 11:59 PM PDT 迭代器与 traits 编程技法
前言这一篇文章,我们来学习下 C++ STL 迭代器以及背后的 traits 编程技法。
在 STL 编程中,容器和算法是独立设计的,容器里面存的是数据,而算法则是提供了对数据的操作,在算法操作数据的过程中,要用到迭代器,迭代器可以看做是容器和算法中间的桥梁。
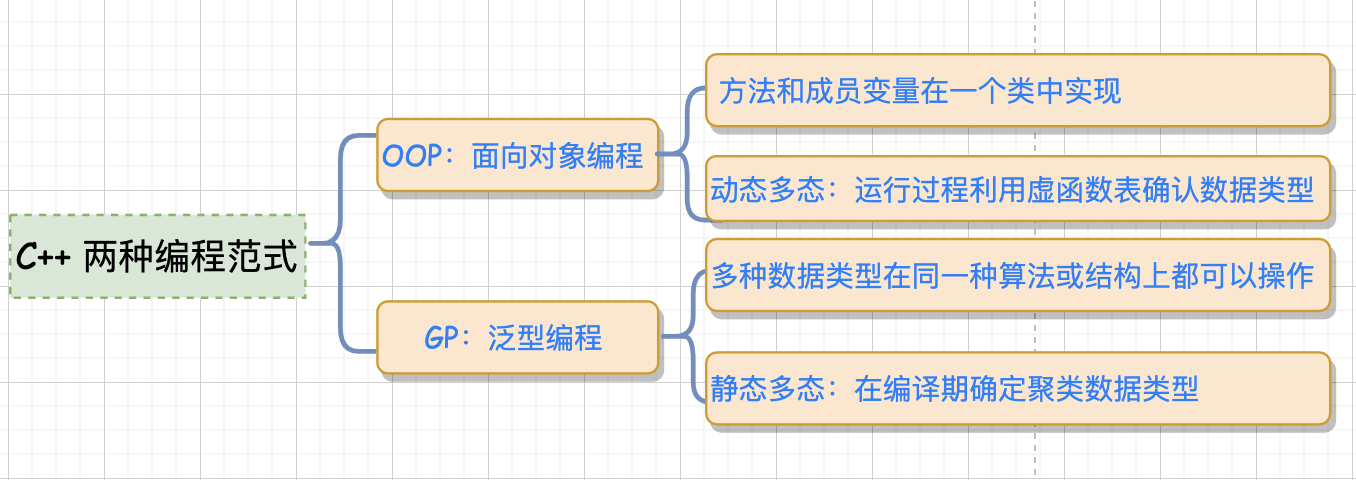
1 、迭代器设计模式为何说迭代器的时候,还谈到了设计模式?这个迭代器和设计模式又有什么关系呢? 其实,在《设计模式:可复用面向对象软件的基础》( GOF )这本经典书中,谈到了 23 种设计模式,其中就有 iterator 迭代模式,且篇幅颇大。 碰巧,笔者在研究 STL 源码的时候,同样的发现有 iterator 迭代器,而且还占据了一章的篇幅。 在设计模式中,关于 iterator 的描述如下:一种能够顺序访问容器中每个元素的方法,使用该方法不能暴露容器内部的表达方式。而类型萃取技术就是为了要解决和 iterator 有关的问题的。 有了上面这个基础,我们就知道了迭代器本身也是一种设计模式,其设计思想值得我们仔细体会。 那么 C++ STL 实现 iterator 和 GOF 介绍的迭代器实现方法什么区别呢? 那首先我们需要了解 C++ 中的两个编程范式的概念,OOP (面向对象编程)和 GP (泛型编程)。 在 C++ 语言里面,我们可用以下方式来简单区分一下 OOP 和 GP:
OOP:将 methods 和 datas 关联到一起 (通俗点就是方法和成员变量放到一个类中实现),通过继承的方式,利用虚函数表( virtual )来实现运行时类型的判定,也叫"动态多态",由于运行过程中需根据类型去检索虚函数表,因此效率相对较低。 GP:泛型编程,也被称为"静态多态",多种数据类型在同一种算法或者结构上皆可操作,其效率与针对某特定数据类型而设计的算法或者结构相同, 具体数据类型在编译期确定,编译器承担更多,代码执行效率高。在 STL 中利用 GP 将 methods 和 datas 实现了分而治之。 而 C++ STL 库的整个实现采用的就是 GP ( Generic Programming ),而不是 OOP ( Object Oriented Programming )。而 GOF 设计模式采用的就是继承关系实现的,因此,相对来讲,C++ STL 的实现效率会相对较高,而且也更有利于维护。 在 STL 编程结构里面,迭代器其实也是一种模板 这样看来,迭代器似乎依附在容器之下,那么,有没有独立而适用于所有容器的泛化的迭代器呢?这个问题先留着,在后面我们会看到,在 STL 编程结构里面,它是如何把迭代器运用的炉火纯青。 2 、智能指针STL 是泛型编程思想的产物,是以泛型编程为指导而产生的。具体来说,STL 中的迭代器将范型算法 稍微看过 STL 迭代器源码的,就明白迭代器其实也是一种智能指针,因此,它也就拥有了一般指针的所有特点—— 能够对其进行 但是在遍历容器的时候,不可避免的要对遍历的容器内部有所了解,所以,干脆把迭代器的开发工作交给容器的设计者,如此以来,所有实现细节反而得以封装起来不被使用者看到,这也正是为什么每一种 STL 容器都提供有专属迭代器的缘故。 比如笔者自己实现的
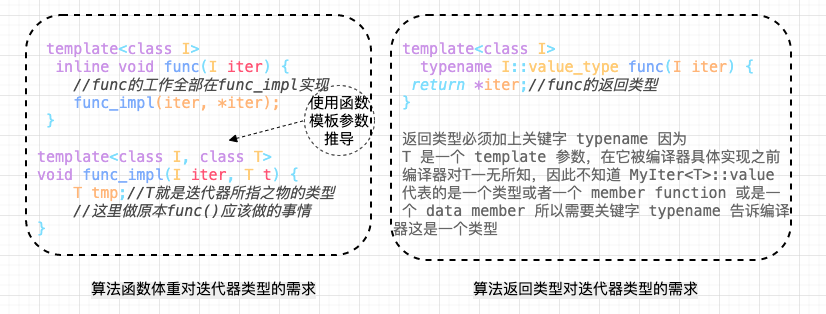
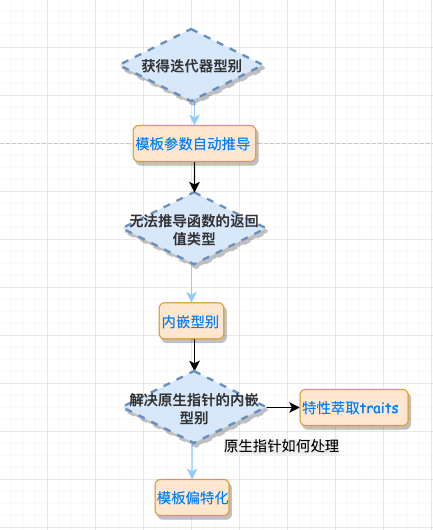
3 、template 参数推导参数推导能帮我们解决什么问题呢? 在算法中,你可能会定义一个简单的中间变量或者设定算法的返回变量类型,这时候,你可能会遇到这样的问题,假如你需要知道迭代器所指元素的类型是什么,进而获取这个迭代器操作的算法的返回类型,但是问题是 注意是类型,不是迭代器的值,虽然
例如: 如果 通过模板的推导机制,就能轻而易举的获得指针所指向的对象的类型。
这就引出了下面的内嵌型别。 4 、声明内嵌型别上述所说的 迭代器所指对象的型别,称之为迭代器的 尽管在 如果在参数推导机制上加上内嵌型别
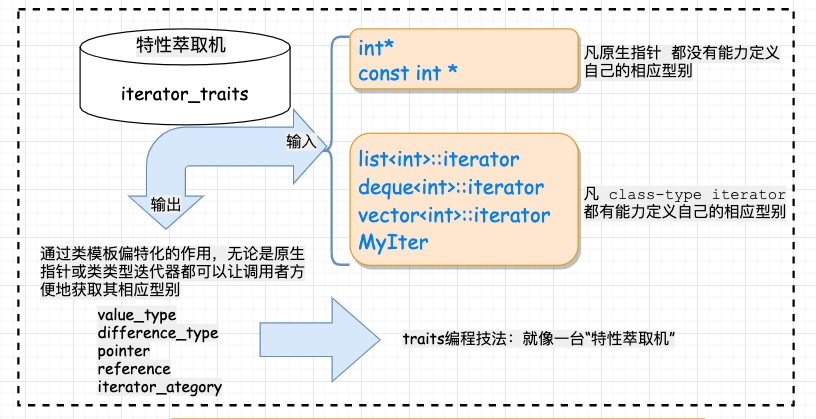
上面的解决方案看着可行,但其实呢,实际上还是有问题,这里有一个隐晦的陷阱:实际上并不是所有的迭代器都是
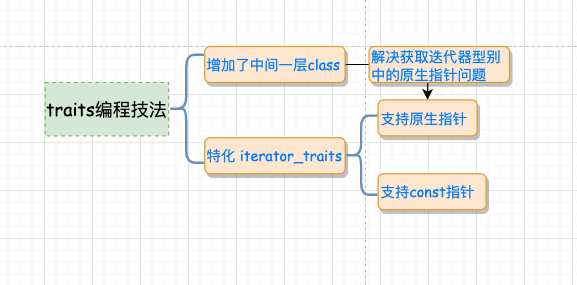
因为 要解决这个问题, 5 、Partial specialization (模板偏特化)所谓偏特化是指如果一个 所谓特化,就是特殊情况特殊处理,第一个类为泛化版本, 5.1 、原生指针怎么办?——特性 "萃取" traits还记得前面说过的参数推导机制+内嵌型别机制获取型别有什么问题吗?问题就在于原生指针虽然是迭代器但不是 有了上面的认识,我们再看看
加入萃取机前后的变化: 看到这里也许你会问了,这个萃取前和萃取后的 回想萃取之前的版本有什么缺陷:不支持原生指针。而通过萃取机的封装,我们可以通过类模板的特化来支持原生指针的版本!如此一来,无论是智能指针,还是原生指针,iterator_traits::value_type 都能起作用,这就解决了前面的问题。 看到这里,我们不得不佩服的 STL 的设计者们,真·秒啊!我们用下面这张图来总结一下前面的流程:
5.2 、const 偏特化通过偏特化添加一层中间转换的 traits 模板 class,能实现对原生指针和迭代器的支持,有的读者可能会继续追问:对于指向常数对象的指针又该怎么处理呢?比如下面的例子: const 变量只能初始化,而不能赋值(这两个概念必须区分清楚)。这将带来下面的问题: 那该如何是好呢?答案还是偏特化,来看实现: 6 、traits 编程技法总结通过上面几节的介绍,我们知道,所谓的 traits 编程技法无非 **就是增加一层中间的模板
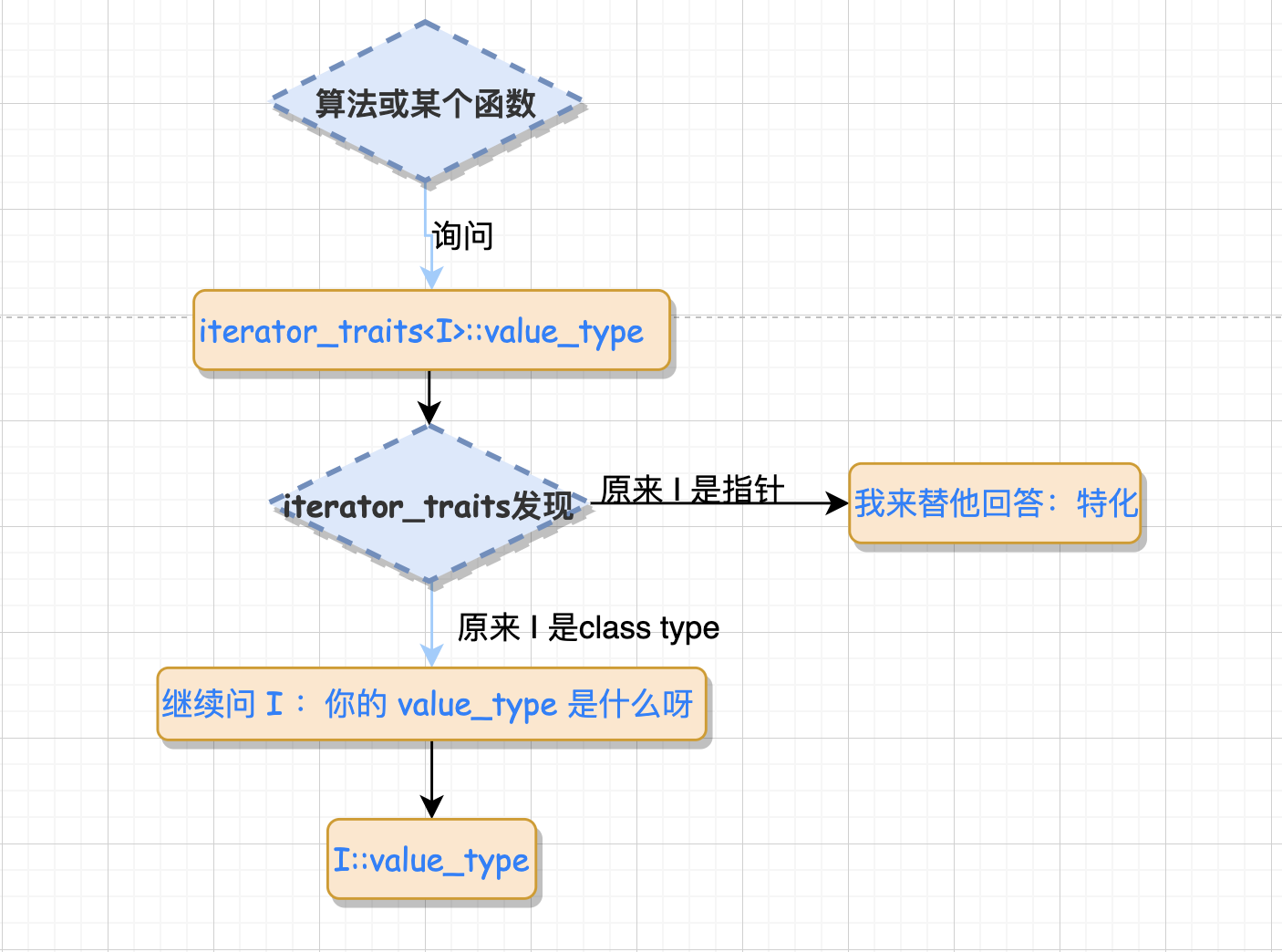
上述的过程是首先询问 通俗的解释可以参照下图:
总结:核心知识点在于 模板参数推导机制+内嵌类型定义机制, 为了能处理原生指针这种特殊的迭代器,引入了偏特化机制。 这种偏特化是针对可调用函数
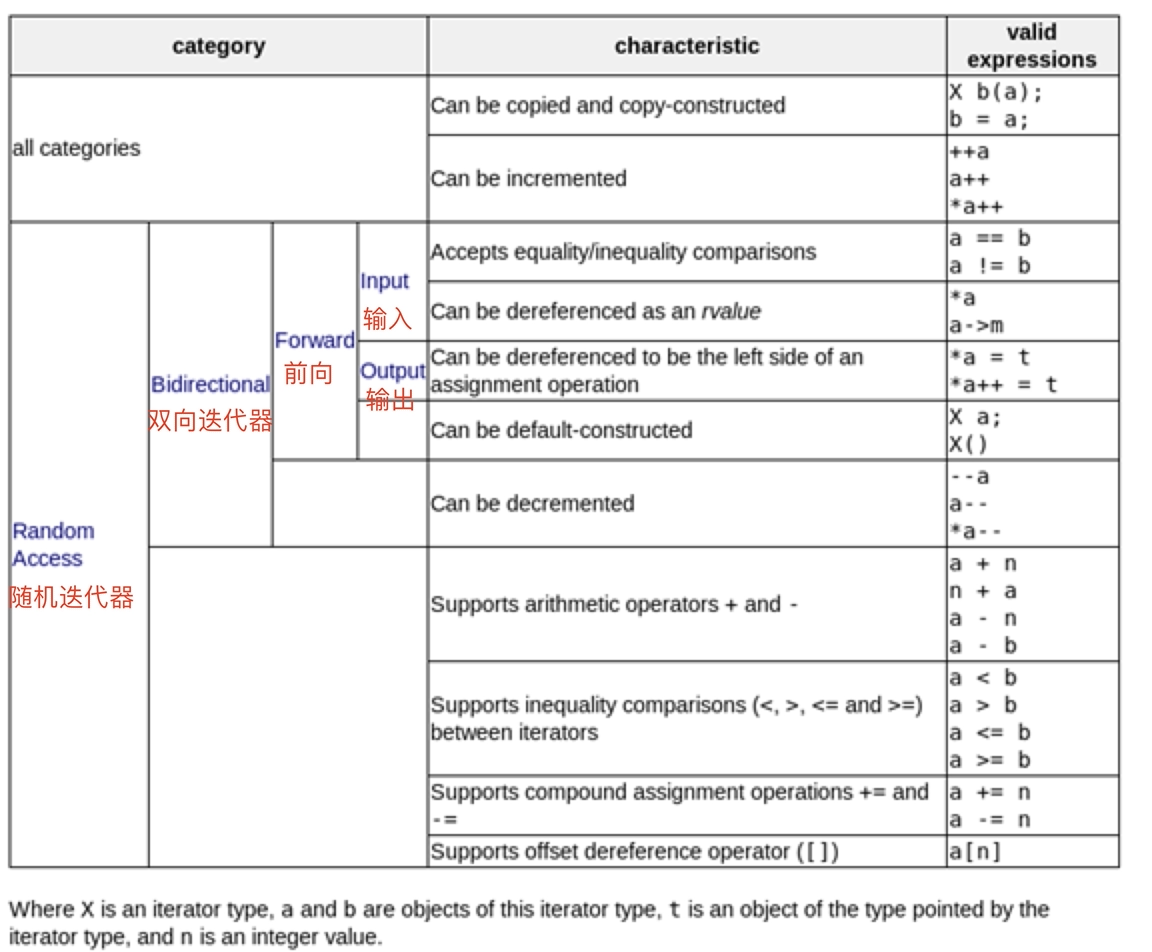
7 、迭代器的型别和种类7.1 迭代器的型别我们再来看看迭代器的型别,常见迭代器相应型别有 5 种:
iterator class 不包含任何成员变量,只有类型的定义,因此不会增加额外的负担。由于后面三个类型都有默认值,在继承它的时候,只需要提供前两个参数就可以了。这个类主要是用来继承的,在实现具体的迭代器时,可以继承上面的类,这样子就不会漏掉上面的 5 个型别了。 对应的迭代器萃取机设计如下: 7.2 、迭代器的分类最后,我们来看看,迭代器型别
那么,这里,小贺想问大家,为什么我们要对迭代器进行分类呢?迭代器在具体的容器里是到底如何运用的呢?这个问题就放到下一节在讲。 最最后,我们再来回顾一下六大组件的关系: 这六大组件的交互关系:container (容器) 通过 allocator (配置器) 取得数据储存空间,algorithm (算法)通过 iterator (迭代器)存取 container (容器) 内容,functor (仿函数) 可以协助 algorithm (算法) 完成不同的策略变化,adapter (配接器) 可以修饰或套接 functor (仿函数)。 参考文章: 《 STL 源码剖析-侯捷》 https://zhuanlan.zhihu.com/p/85809752 https://wendeng.github.io/2019/05/15/c++%E5%9F%BA%E7%A1%80/%E3%80%8ASTL%E6%BA%90%E7%A0%81%E5%89%96%E6%9E%90%E3%80%8B%E7%AC%AC3%E7%AB%A0%20%E8%BF%AD%E4%BB%A3%E5%99%A8%E4%B8%8Etraits%E7%BC%96%E7%A8%8B%E6%8A%80%E6%B3%95/ 作者简介🔭 宇宙中心五道口狗厂程序员,爱生活,好读书 🌱 热爱分享: 公众号『 herongwei 』 🤔 个人博客:herongwei.com 📫 微信:icoredump 😄 有问题欢迎知乎 @herongwei
|
| 异步 MySQL 库 databases 的 Table 结构怎么从经典模式转成 ORM? Posted: 16 Apr 2021 11:47 PM PDT 翻了很多例子都是使用的经典模式,实在不习惯: 请问怎么转成这种 ORM 模式,进行数据库操作呢? |
| Posted: 16 Apr 2021 11:17 PM PDT http-proxy 是 IOS 模型七层的代理么? node 如何实现四层的转发呢? |
| Posted: 16 Apr 2021 11:02 PM PDT 我想做一个 python 自动打卡 已知 只允许从 app 签到;登录时 app 会根据 token 设置 cookie JSESSIONID,签到的时候 header 会带着 cookie 我已经伪装了 UA,也通过得到的动态 SESSIONID 设置好了 cookie 但是返回 320 重定向到了登录页面 请问各位大佬这是怎么回事?谢谢! |
| 没学过 Java 和 Spring Boot 该怎样学习 Nest.js 框架? Posted: 16 Apr 2021 10:46 PM PDT 楼主之前只用过 express,现在想找一个完整的 node 后端框架学学,很多人都在推荐 Nest.js ,但我发现这玩意的设计理念是模仿 Spring Boot 的,直接看 Nest.js 文档,有很多地方还是看不太懂。 有没有人能推荐几篇讲解 Nest.js 设计理念的文章?或者分享一下学习 Nest.js 框架的经验? |
| Posted: 16 Apr 2021 08:39 PM PDT 需求是这样的,一个 web 应用,用来做工程上设备端口占用的申请之类的,我想了想应该至少有这么几块: 原始端口数据录入(至少得有手工填写和表格导入) 简单的端口信息展示(工程啊,设备名称,端口信息,占用者的信息。。。少不了搜索功能) 占用申请(估计类似工单系统,需要做账号和权限之类的) 导出(端口表,各种口径的统计表之类的) 这样的需求有没有什么简单易学的框架来实现啊(手动捂脸) (完全不会 web 。。。平时靠 google 写点儿工作上的 python 脚本,被安排这活儿顿时头大了。。。) |
| Posted: 16 Apr 2021 08:35 PM PDT 用着还不错,挺清爽,速度还可以 play.google.com/store/apps/details?id=com.microsoft.emmx.canary |
| Posted: 16 Apr 2021 06:12 PM PDT kubectl\kubeproxy\containerd|podman\ingress\schedule 如 containerd,运行容器,同时有 pull&push image 的能力吗? |
| 大家有没有 Kubernetes Operator 教程推荐? Posted: 16 Apr 2021 01:42 PM PDT 最好是可以快速入门的。收费的也可以。 |
| Posted: 16 Apr 2021 12:42 PM PDT 如题,项目中使用 vue + vuetify + tailwind 。第一次使用 tailwind,没想到遇到这种问题。 具体表现为,使用 npm run serve 运行开发服务器,显示界面如同代码预期,一切正常。而使用 npm run build 编译项目后使用后端提供服务,则部分样式出现了错误。如同下图
补充 1 、整个项目完全由前端构建,全部为静态文件,不涉及任何后端 api 2 、图中可见,页面使用了两个 vuetify 组件,分别是 header 和两个按钮,这些组件都出现了变形。而使用 tailwind 构建的样式则完全没问题。 3 、经测试 vue 的 js 代码可以正常运行,输出结果正确 4 、我测试了一下编译后的 index.html 中加载的样式和脚本文件,全部都可以正常访问,不是由于某个文件无法加载造成的错误。 5 、图中可以看到,materialdesignicons 的图标是可以正常显示的,说明图标文件加载没问题 有没有大佬能说下可能是啥原因导致的? |
| Posted: 16 Apr 2021 12:35 PM PDT 最近有个需求,做一个简单的比喻,比方说有一片海域养殖生蚝,海域里有上千个养殖点,每个养殖点有一串生蚝养殖基,每个生蚝有每个生蚝的一些信息字段,这样大概有四张表:海域表 /养殖点表 /养殖基表 /生蚝表,数据量大概会有千万级以上,业务场景需要读的场景比较多,写的话压力不大也可以用中间件分批写入,如果用 mysql 这类关系型数据库,感觉有点扛不住,V 友们有这方面的经验吗?或者有别的 DB 可以推荐的,感谢了~ |
| 请教各位关于 requests timeout 的问题,有小伙伴设置了 timeout,但是还是导致卡死的情况吗?其根源问题到底是什么?求大佬帮忙 Posted: 16 Apr 2021 10:57 AM PDT 很久之前遇到了一个问题,在香港的阿里云服务器上,通过 requests 调用第三方 url 的某个方法, 虽然设置了 timeout,但是还是有卡死的情况,后来就找到了这篇文章 https://www.jianshu.com/p/331fa39bc251 请问这篇文章的根据是什么呀???其底层到底是怎么回事??怎么可以复现这种问题? (虽然现在很久没搞爬虫了,也很久没碰到这样的问题了,但还是很想知道原因) |
| Posted: 16 Apr 2021 08:42 AM PDT 最近闲了没事自己做了个小 app,记笔记用的。打包 release 后大小 2.1mb ,我如何让它更小? 2.1mb 继续压缩到 500kb 可以实现吗? app 项目链接: https://quick.geshkii.xyz 各位有什么指导或意见尽管跟我说,我洗耳恭听。 谢谢! |
| Posted: 16 Apr 2021 08:31 AM PDT curl 8000 会转换为 curl 0.0.31.64 ,后面的 IP 就是把 8000 转为二进制高位补 0,然后再从高位到低位 8 个数字一切割转为十进制。不太明白 curl 为啥这么设计? |
| Posted: 16 Apr 2021 04:14 AM PDT MySQL 数据库编码是 latin1,在 unix 命令行指定 latin1 编码 dump 了数据文件,想迁移至 windows 下 utf8 编码的 MySQL 中,请问直接修改文件中建表语句的字符集可以吗?谢谢。 |





 太长了,又看懵逼了吧,没关系,请看下图。
太长了,又看懵逼了吧,没关系,请看下图。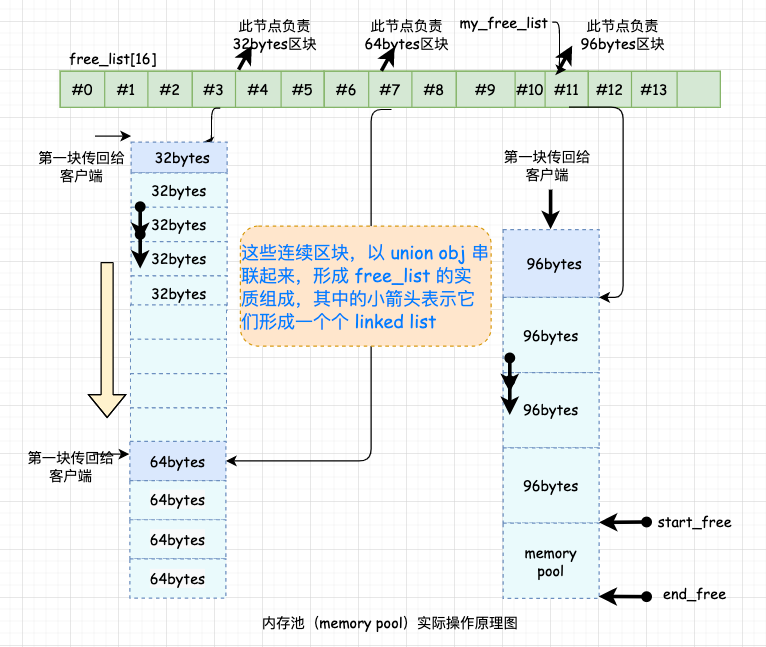



 在上面这张图里,可以看到,push_back 这个函数里面又判断了一次 finish != end_of_storage 这是因为啥呢?原来这是因为 insert_aux 函数可能还被其他函数调用哦。
在上面这张图里,可以看到,push_back 这个函数里面又判断了一次 finish != end_of_storage 这是因为啥呢?原来这是因为 insert_aux 函数可能还被其他函数调用哦。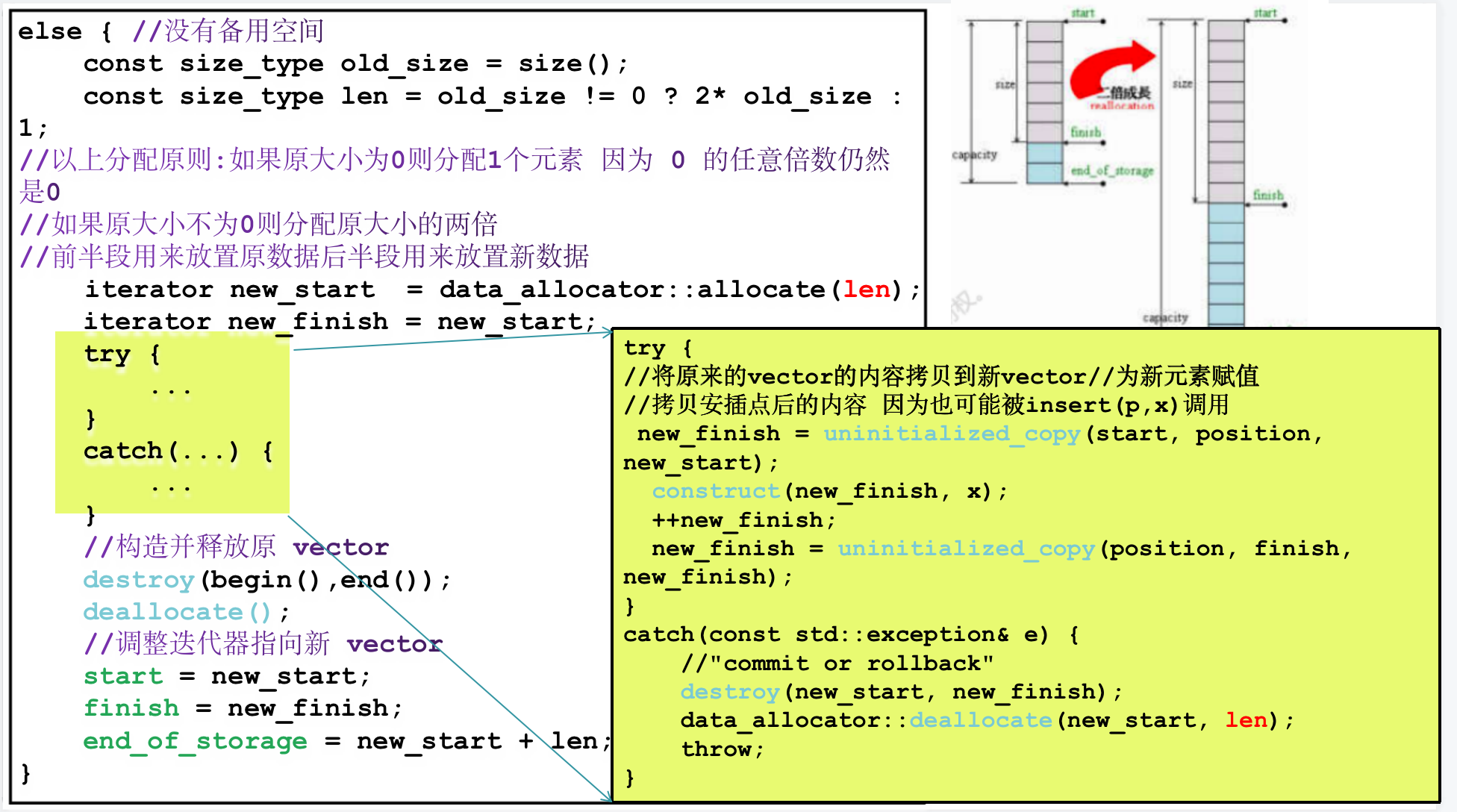



 上面的做法呢,通过多层的迭代,很巧妙地导出了
上面的做法呢,通过多层的迭代,很巧妙地导出了 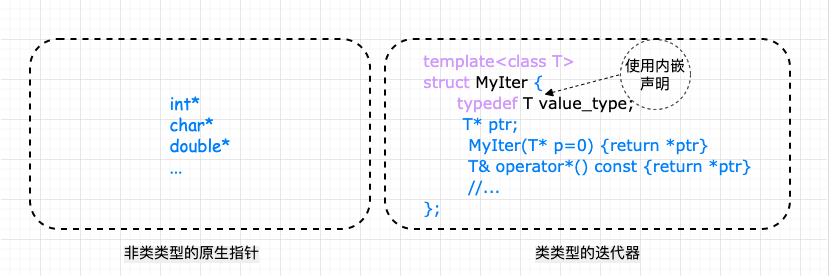

| You are subscribed to email updates from V2EX - 技术. To stop receiving these emails, you may unsubscribe now. | Email delivery powered by Google |
| Google, 1600 Amphitheatre Parkway, Mountain View, CA 94043, United States | |
No comments:
Post a Comment