V2EX - 技术 |
- 极客时间虚假举办活动、随意更改规则
- 求助 Python 可不可以识别图片中的人体部分?比如手,头,肩膀,腰部等等这种?
- 有什么像 golang 一样低内存占用, 但是语法更偏向 Java /c++/js 的语言吗?
- mysql 四百万左右数据 count(*) 49 秒才响应,求助大佬怎么优化?
- 真诚求问,鸿蒙 2 对应哪个安卓版本
- 从哪一刻开始,你觉得大厂的程序员真的很强/很弱
- 可否使用内网穿透(frp 或其他),给内网 bt 下载加速
- MySQL 主键用自增好还是 UUID、雪花算法 ID 好?用自增+UUID 会不会好一点?
- 阿里的 druid 怎么样, 包是不是有点太大了
- sequelize、mysql 问题求解答!一张表多个关联关系问题。
- 关于前后端分离项目部署到阿里云 OSS API 接口问题
- 标签功能不能集成进文件浏览器根本没意义吧。
- 撸了个在线工具箱,各位有什么建议吗?
- 现在还有能用的命令行版 V2EX 咩?
- 学习 react hooks,请问有哪些可以学习并且很有教学意义的开源项目呢
- ipados ios git 推送到 github
- 请问 Django 并发条件下,生成雪花 ID 为什么会重复?
- 求构建: Java 单例 double-check volatile 关键字的反例。
- 如何对业务代码中进行抽象和提取公有逻辑呢?
- 最近用 Java14 的 Records 重构了一下几个项目
- 想了解下国内有哪些大厂允许员工利用工作 PC 在外网博客上发表技术文章的?
- CloudQuery 首次开放 API, v1.4.1 将开放「部门导入」和「用户导入」
- idea 里这个类的颜色有点淡, 为什么? 我猜跟 git 相关
- 我看懵逼了。。哪位大佬指导一下正确的脚手架的技术栈到底是怎么样的?
- 共享一个终端上的字典
- Arthas 和 GC 的那点事:动态日志,强制 GC
- Python 有支持 ppt 的库么,目前只找到支持 pptx 的
- 大厂的 app 是怎么渲染页面的
- 求 Java 入门教程视频
- MongoDB 按题型保持一定比例抽题
| Posted: 30 Jul 2021 03:48 AM PDT 极客时间最近举办了一个攒学分的活动 、活动日期 2021 年 7 月 24 日 00:00:00 - 2021 年 7 月 30 日 23:59:59 具体链接如下: 极客时间 7 月任务赛 具体规则如下:
但是之后竟然变更了规则????
之前的规则是 [邀请好友购买课程] ,现在改成年卡用户专享........而且是在活动快结束的时候更改规则。 这种大家该如何解决?,原本我的排名是第一。一下搞得我没有名次了....... 之后极客时间打电话 说是要扣除我的分数,并表示让我理解他们? 并表示要给我一定的补偿,补偿我 100 元极客充值卡,我拒绝了。所以来这里发个帖子。感觉我也不在乎 100 块钱。 其实发这个帖子 也毫无卵用,毕竟最终解释权在人家手里,我来这里只是想吐槽一下......缓解我的不公平待遇。 也希望,其他参与用户可以看到这个帖子。我反正是站出来了。枪打出头鸟......希望我的极客时间账号不会被他们给黑掉吧。毕竟我也算是一个忠实用户了..... | |||||||||||||||||||||||||||||||||||||||||||||
| 求助 Python 可不可以识别图片中的人体部分?比如手,头,肩膀,腰部等等这种? Posted: 30 Jul 2021 03:41 AM PDT 这样能够识别人体部分的 python 脚本有吗? | |||||||||||||||||||||||||||||||||||||||||||||
| 有什么像 golang 一样低内存占用, 但是语法更偏向 Java /c++/js 的语言吗? Posted: 30 Jul 2021 03:27 AM PDT | |||||||||||||||||||||||||||||||||||||||||||||
| mysql 四百万左右数据 count(*) 49 秒才响应,求助大佬怎么优化? Posted: 30 Jul 2021 03:20 AM PDT
大佬们,像这种怎么优化字段提升查询速度。 执行一次 49s 就很离谱 | |||||||||||||||||||||||||||||||||||||||||||||
| Posted: 30 Jul 2021 03:15 AM PDT 问用户系统版本是什么,一大堆的鸿蒙 2.0,所以鸿蒙 2.0 对应哪个安卓版本,会存在多安卓版本的情况吗?客户端怎么查问题? | |||||||||||||||||||||||||||||||||||||||||||||
| Posted: 30 Jul 2021 03:13 AM PDT 楼主没有进大厂,我从大厂的技术开源看,一开始真的很 low,比如 nacos 1.0 的版本,没有用到分布式一致性算法,而是操作本地文件。。2.0 后我发现好了很多。 每次看美团的技术文章,我觉得哇,架构的落地真的好厉害,从开发,到运维,到测试方方面面都是我理想中的样子,好想了解一下内部具体实现的细节。可惜没有开源。 然后去 github 和 gitee 上找开源,我发现一个天一个地,gitee 上的开源的代码很好理解,但是缺少了高可用和性能等问题,GitHub 成熟项目非常不错,但是一时半会儿看不懂。 | |||||||||||||||||||||||||||||||||||||||||||||
| Posted: 30 Jul 2021 03:04 AM PDT 宽带是移动大内网 bt 下载速度很慢,目前有个服务器带宽够用,可否使用内网穿透把内网暴露在公网上。 | |||||||||||||||||||||||||||||||||||||||||||||
| MySQL 主键用自增好还是 UUID、雪花算法 ID 好?用自增+UUID 会不会好一点? Posted: 30 Jul 2021 02:54 AM PDT 我想的是一个表有两个基本字段 id 和 primary_key,id 是自增,且为主键; primary_key 为 UUID,是逻辑主键,表与表之间通过 primary_key 来关联,对前端也只暴露 primary_key 。 | |||||||||||||||||||||||||||||||||||||||||||||
| Posted: 30 Jul 2021 02:54 AM PDT 一个数据源, jar 包 3.5M, 真有这么多功能吗 | |||||||||||||||||||||||||||||||||||||||||||||
| sequelize、mysql 问题求解答!一张表多个关联关系问题。 Posted: 30 Jul 2021 02:43 AM PDT
上面是我的数据表关系。
业务简化逻辑: 员工、员工任务。员工甲委派任务给员工乙, 现在要通过,worker_task 表查询出,worker_id 和 other_workerid 对应的信息。下边是我的 sequelize 查询语句。 求助 sequelize 语句或者原始 mysql 语句。或者换其他可行的思路也是 ok 的,提前谢谢大家! | |||||||||||||||||||||||||||||||||||||||||||||
| Posted: 30 Jul 2021 02:39 AM PDT 我有一个完全前后端分离的项目 vue 打包后将 dist 全部上传到 OSS 并且配置了 CDN 页面可以正常访问,OSS 跨域也设置过了。但是所有的 Get 接口提示 404,Post 接口提示 405 大家有遇到过类似的情况吗?怎么解决 | |||||||||||||||||||||||||||||||||||||||||||||
| Posted: 30 Jul 2021 02:36 AM PDT 个人感觉,Everything 比所有的标签管理工具都要能打。。。要么记住文件名,如果记不住那么就在目录中手动找到,如果都不能那是你组件文件的能力问题,标签也救不了。。因为很大可能是你忘记打标签了。。 一个真正需要标签的场景应该是下边图里这样:
目前按「创建时间」分组实现了。。然而略蛋疼。。 | |||||||||||||||||||||||||||||||||||||||||||||
| Posted: 30 Jul 2021 02:11 AM PDT 日常有些需求会用到各种在线工具,但是有些在线工具实在比较古老,所以自己撸了几个,各位有什么比较常用的需求吗?征集一下。 工具箱地址: https://tools.yuanfen.net/ 目前上线的工具:
| |||||||||||||||||||||||||||||||||||||||||||||
| Posted: 30 Jul 2021 01:41 AM PDT
试了两个都挂了,现在还有能用的咩? | |||||||||||||||||||||||||||||||||||||||||||||
| 学习 react hooks,请问有哪些可以学习并且很有教学意义的开源项目呢 Posted: 30 Jul 2021 01:22 AM PDT 看到幕课网上有教程,在想是买课程获取课程和配套的项目,还是看优秀的 hooks 的开源项目。 | |||||||||||||||||||||||||||||||||||||||||||||
| Posted: 30 Jul 2021 12:56 AM PDT 突发奇想,苹果的平板和手机能不能编辑好文件推到 github ? 貌似得找支持各个系统的 git 安装包? | |||||||||||||||||||||||||||||||||||||||||||||
| 请问 Django 并发条件下,生成雪花 ID 为什么会重复? Posted: 30 Jul 2021 12:44 AM PDT 我用的是别人写好的模块,如下
我首先自己跑单线程测了一下,完全不会有重复,多线程在加线程锁的情况下也完全没有发生重复。 但是我在实际项目中生成的时候,大概 10 条线提交总共 1600 条数据,每次都会产生大概几十条重复 我打印过 ID,这个雪花生成器实例并没有被初始化多个,请问如何排查? 大致代码如下: | |||||||||||||||||||||||||||||||||||||||||||||
| 求构建: Java 单例 double-check volatile 关键字的反例。 Posted: 30 Jul 2021 12:18 AM PDT 单例模式中 Lazy 模式中,使用 double-check 必须使用 volatile 关键字。 ❓能否构建一个不使用 volatile 出错的例子?
PS: 本人已知 volatile 关键字的特性:
| |||||||||||||||||||||||||||||||||||||||||||||
| Posted: 29 Jul 2021 10:35 PM PDT 之前写的代码可能比较随意,没有考虑过这个问题。现在遇到的问题是两个接口代码相似度可能超过 80%。 1.对相同的代码封装为函数,不同的代码用接口去实现。(只是这么一个想法,但具体没啥实现思路 2.将两个接口合为一个接口。这样的问题是可能会多了许多 if/else 。 真心向各位请教一下,有什么比较好的做法。 | |||||||||||||||||||||||||||||||||||||||||||||
| 最近用 Java14 的 Records 重构了一下几个项目 Posted: 29 Jul 2021 09:55 PM PDT 用下来相关生态对 Records 支持得很好了,比如 Jackson 、Spring 全家桶等常用的库、框架,都给出了对应的支持,用下来体验很好 现阶段建议可以入手了 | |||||||||||||||||||||||||||||||||||||||||||||
| 想了解下国内有哪些大厂允许员工利用工作 PC 在外网博客上发表技术文章的? Posted: 29 Jul 2021 09:37 PM PDT 如题,工作中遇到好多问题都通过搜索引擎解决了,所以想将自己踩的坑也发出来,但是当前所在的 H*对信息安全管控极其严格,不允许外发博客。像这种一味地汲取外部知识,又不允许将自己的知识反馈回去,让我感觉非常封闭。所以想了解一下其他大厂也是这样子的吗? | |||||||||||||||||||||||||||||||||||||||||||||
| CloudQuery 首次开放 API, v1.4.1 将开放「部门导入」和「用户导入」 Posted: 29 Jul 2021 08:57 PM PDT 「 API 具有功能丰富、发展迅速且公共可用的特点,极大地推动了以 API 为中心的业务增长。原因有很多,比如 API 随处可用的特性、高效的开发和部署平台,以及摆脱资金密集型需求的金融模型。」 ——《 Evolution of the API economy 》 随着企业对客户体验关注度的增加,越来越多企业期望以低成本、无摩擦的方式融入成熟的生态系统,由此引出「 OpenAPI 」的概念。API 以其高度的灵活性、友好性来面对众多前来调用的开发者,成功在各分布式应用之间进行接口调用与数据互通,构造一座无形的数据桥梁。 OpenAPI 描述语言也被称为接口描述语言( IDL )。描述语言通常以结构化的方式形成文档,因为同一工具生成的所有文档都遵循相同的格式约定,所以比自由形式的文档更具有可读性。此外,描述语言通常足够精确,可以自动生成各种软件类库,方便以各种语言来接入、调用 API 。 CloudQuery 开放 API 的意义:从社区中来,到社区中去CloudQuery 是一款出生于社区,生长于社区的产品,各位社区用户见证着我们的成长,但在我们自身功能还未完善的时候, 之前很多用户提到的内部 OA 、组织架构对接功能就显得格外力不从心。自 CloudQuery 诞生的那一天起,我们就赋予了它基本的价值观:「开放、包容、互助、共赢」。所以我们产品逐渐趋于稳定的今天,也终于可以实现当初「开放」的承诺。 在 1.4.1 版本中我们将开放首个用户模块的 API,后续也会逐步开放审计、权限模块 API 。我们来自于社区,最终也会回归社区,希望最后是我们和社区内的用户一起来把 CloudQuery 做成一款广受欢迎、贴合数据操作人员使用场景的数据库工具。 技术实现前文已经提到各种新兴行业趋势和技术已经导致 API 激增,当前应用程序组件不再是单个进程中在一台机器上彼此通信的内部对象,而是通过网络相互通信的 API 。网络的信息交互页增加了被攻击的风险,甚至 OWASP 已经推出了针对 API 攻击的十大漏洞列表,API 在今年成为了网络安全的重中之重。 CloudQuery 作为数据管控平台,数据安全管控对其的重要性不言而喻,所以在设计整个 OpenAPI 模块时我们在确保请求安全性、可靠性方面着重进行了多重加固。 发起请求时,服务端会以请求头中的 API 密钥来进行用户鉴权,鉴权成功后会给客户端颁发 token,token 具有时效性,在进行时效性校验的同时避免了重复信息反复查询数据库和对比等操作,也提高了服务器响应速度。如果仍然担心在输入密码时被网络抓包的方式窃取,则可以通过配置 HTTPS 的方式来进行传输加密,具体配置方式可以参考《 CloudQuery 安全系列(一):Http 与 Https 》。 在请求过程中,身份认证无疑是最重要的环节。OpenAPI 规范中我们可以使用自定义对象和属性,针对每个 api 接口进行扩展,在定义 api 模块时我们都会定义 api 自身的安全方案、应用级别,例如在定义用户模块的应用级别时就可以定义它的支持范围,防止其他恶意用户进行越权调用。 使用方法CloudQuery 对外开放的接口接受「 GET 」和「 POST 」两种调用方式,字符编码统一使用「 UTF-8 」编码。对于所有的「 POST 」调用方式接口,提交的数据格式统一为「 JSON(application/json)」格式。 接口调用前需管理员在 CloudQuery 进行「开发者授权」申请接口调用的身份信息。平台会自动生成 appId,secret 信息,在代码调用接口中使用。 本次 v1.4.1 版本,CloudQuery 开放了「组织架构」模块『部门导入』和『用户导入』的 API 。具体的《 OpenAPI 开发者文档》可在官网文档站查看,地址为: https://cloudquery.club/docs/。 我们以「用户导入」为例来说明使用方法。 输入参数:
请求示例: 成功实例: 返回结果一览:
在当前企业内部应用复杂的场景下,OpenAPI 正在逐步取代之前数据直接交换的方式进行应用间数据互通,开放 api 并不意味着将内部数据完全暴露,反而是以更加安全的方式来实现信息交互。随着 CloudQuery 的不断迭代,我们也会在未来更加注重企业内部生态连接,铸造更友好的一体化平台。 官网地址: https://cloudquery.club/ | |||||||||||||||||||||||||||||||||||||||||||||
| idea 里这个类的颜色有点淡, 为什么? 我猜跟 git 相关 Posted: 29 Jul 2021 08:49 PM PDT | |||||||||||||||||||||||||||||||||||||||||||||
| 我看懵逼了。。哪位大佬指导一下正确的脚手架的技术栈到底是怎么样的? Posted: 29 Jul 2021 08:43 PM PDT 说一下我为什么懵逼把 我看 start.spring.io 的源码,我看了一天,spring initializr 的逻辑把生成的数据放在配置文件里面,然后用代码和常量生成加逻辑生成,我怎么瞅都觉得,这有比模板引擎来的方便吗? 就是哪种 say msg {{a}} ! if a = "hello world" => say msg hello world ! 来的方便? 能说说这个 spring initializr 生成项目的方式到底好在哪里吗? 我左思右想就是纯粹的自己实现了一套自己的生成方式而已 我等会再去看看 vue-cli 生成方式 有没有主流的脚手架模板生成技术栈? | |||||||||||||||||||||||||||||||||||||||||||||
| Posted: 29 Jul 2021 08:29 PM PDT 终端开发必备工具,支持 Linux/MacOS(M1/X86)。 Go: https://github.com/vonnyfly/dict 学了点 rust,也发一下: Rust: https://github.com/vonnyfly/dict-rs | |||||||||||||||||||||||||||||||||||||||||||||
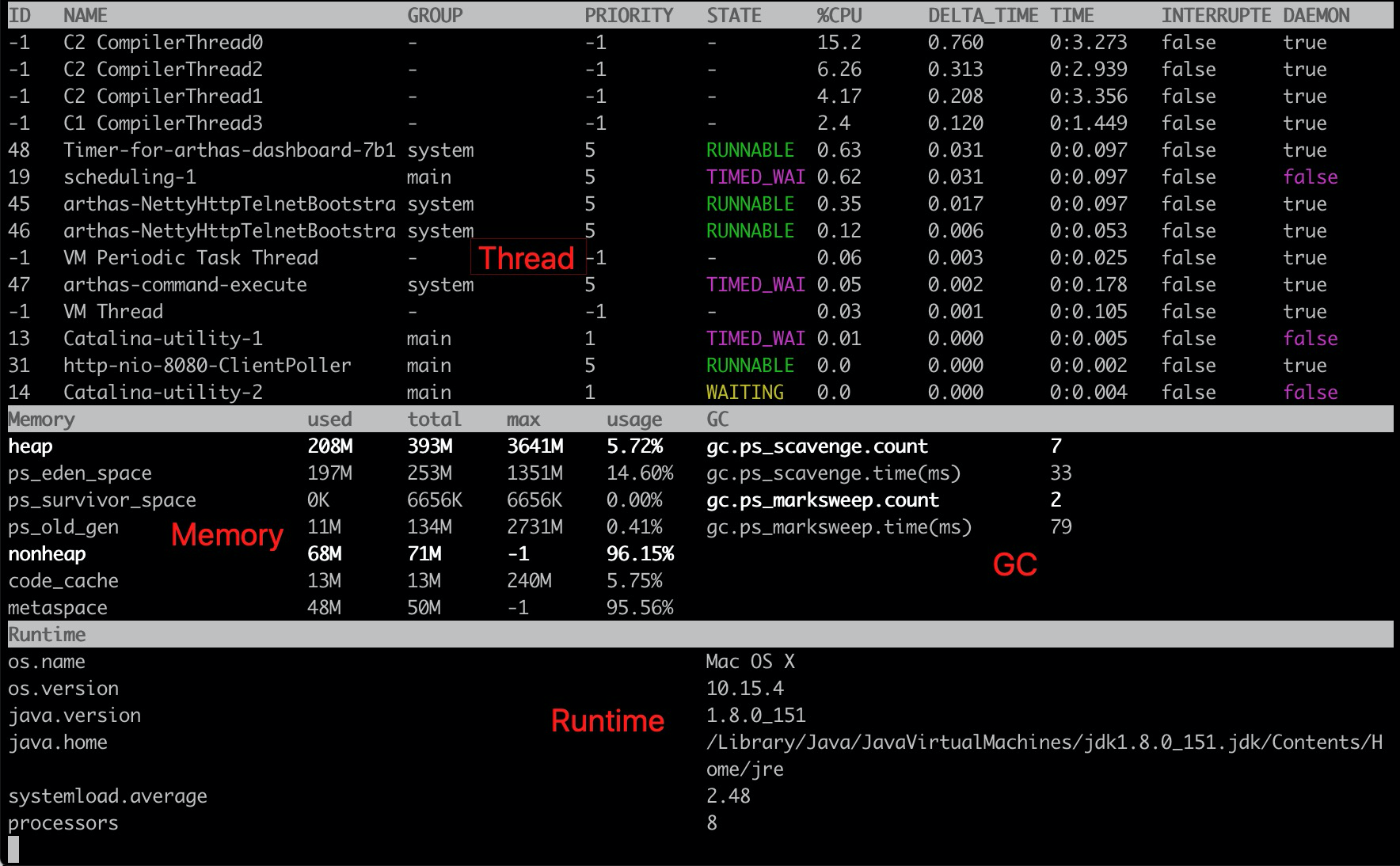
| Posted: 29 Jul 2021 07:51 PM PDT
一、线上应用怎么动态打印 GC 日志?小白正在上班摸鱼,突然运维告警,线上应用突发 GC 问题,GC 时间变长,响应变慢。 火速登陆机器,想检查 GC 日志,忽然发现,线上应用 JVM 参数没有打印 GC 信息😂。 如果增加 JVM 参数,那么要重启应用,现场就没有了,怎么办? Arthas 可以解决这个问题! 二、使用 dashboard 命令查看 GC 信息在 dashboard 命令里可以直接看到 GC 的数据,次数和时间:
三、使用 vmoption 命令动态打开 GC 日志打开上面两个选项之后,当应用发生 GC 时,就会在标准输出里打印 GC 日志。 四、使用 vmtool 强制 GC然后查看应用的标准输出,可以发现有 GC 日志: 五、更多 GC 开关5.1 打印 GC ID则 GC 日志里会有 5.2 打印 GC 时间戳则 GC 日志会带上时间: 则 GC 日志会带上应用启动时间: 5.3 在 GC 前后,执行 heapdump在排查 GC 问题时,我们有时需要对比 GC 前后,生成 heapdump 文件,然后再做对比。
再使用 再使用其它堆分析软件,对比两个 heapdump 文件,就可以知道 GC 到底回收了哪些对象。 5.4 在 GC 前后,打印类直方图排查 GC 问题时,我们有时需要统计每个类加载的数量和占用内存大小。
再使用 六、总结
招聘最后打个广告,我们正在寻找小伙伴,特别是深圳的同学,欢迎大家加入。 | |||||||||||||||||||||||||||||||||||||||||||||
| Python 有支持 ppt 的库么,目前只找到支持 pptx 的 Posted: 29 Jul 2021 07:31 PM PDT python 有支持 ppt 的库么,目前只找到支持 pptx 的,如题;最好有文档说明 | |||||||||||||||||||||||||||||||||||||||||||||
| Posted: 29 Jul 2021 03:10 PM PDT 是一次性从后端拿到组装完整的数据再渲染,还是分模块去调不同的业务接口(或者是其他方式?),也就是数据是前端自己组装的还是后端组装的。如果是前端组装的话,怎么动态去改变页面布局,一定要等到发版或者跨平台技术?如果是后端组装的话,怎么样保证数据还没到前端的时候的用户体验。 脑洞 1: 后端数据组装完成后,用 http stream 先传 metadata,主要是一些模块的元数据,前端先把框架渲染出来,渲染过程中后面的模块数据也接收到了,再渲染具体模块。app 前端只针对模块类型写渲染逻辑和将 metadata 解析成页面的逻辑,不写具体的页面。 脑洞 2:把这些模块再抽象一层,是不是就成了类似 html 的东西了。像 flutter 这种技术,是不是就是新时代的 js 和 html ? | |||||||||||||||||||||||||||||||||||||||||||||
| Posted: 29 Jul 2021 08:51 AM PDT 看了一些视频,都是针对零基础的,学习速度太慢了,各位大佬有没有 Java 教程视频推荐,针对有多年工作经验的程序员的视频 | |||||||||||||||||||||||||||||||||||||||||||||
| Posted: 29 Jul 2021 08:49 AM PDT 后端技术栈用的 Node.js + Mongoose + MongoDB,数据库中的每道题目分属不同的题型(单选 /多选 /判断),现在需要实现的抽题功能如下:
以上两点需求,该如何实现呢?谢谢先。 |






{kind=link}
| You are subscribed to email updates from V2EX - 技术. To stop receiving these emails, you may unsubscribe now. | Email delivery powered by Google |
| Google, 1600 Amphitheatre Parkway, Mountain View, CA 94043, United States | |
No comments:
Post a Comment