V2EX - 技术 |
- Nodejs 终于刷到了版本 16(LTS)
- Android 项目多个 Jar 包有命名空间冲突,有办法解决吗?
- 使用 vue-cli 创建的项目删掉 node_modules 之后再 npm i 会提示找不到 Python ,为什么 vue create 的时候不会有问题
- android studio build 报错,貌似是 gradle 版本问题,网上搜了方法没解决,有大佬帮看看吗?
- 请问,自己独立的使用 Springboot+Mybatis+vue 写个博客网站,能找到 Java 开发的工作不. 害怕被面试官乱杀
- 家人们, Python 在爬 https 的时候会出现一个少见的问题,是本地环境的问题吗?
- 微信 Go SDK(支付、公众号、小程序)
- 如何模拟微信浏览器阅读文章
- 如何从一个图片上找到指定文字的位置
- �� Go 轻量级开发通用库 ������
- M1 芯片通过 PD 安装 CentOS ARM 问题求助
- 不太明白 writer.write() 和 writer.write() await writer.drain()有什么区别
- 大家在学新东西的时候状态是怎样的,最近感觉自己忘的也太快了点
- github 上 android 项目,有 CI 工具可以自动编译 apk 并上传到 release 里面么
- github codespaces 有没人试过?
- Java on Visual Studio Code 的更新 – 2021 年 3 月
- InfluxDB (InfluxQL) 中如何按 tag 计算总和?
- 求 mac vscode svn 插件推荐?
- Redux 源码专精视频课 [免费完整版]
- SpringSecurity 的无权访问异常理器 AccessDeniedHandler 与统一异常处理器 DefaultHandlerExceptionResolver 冲突
- 一键管理你的 Linux 环境
- 如何能检测 Nginx 实际配置变更和配置变更备注的等价性?
- 适合学习的 Go 语言开源项目、书籍(附学习路线图)
- 上次发得为 PHP 写 FFI 库添加了性能测试
- tinymce 格式刷
- 全球首款消费级 Linux 平板 JingPad A1 视频已发布
- Magisk 如何对单个 apk 文件内部的文件进行替换?
- 谈谈 Java 线程池
- 关于 Python 中 os 模块怎么获取环境变量的问题
- [提问]如何在一个包内一次性加载模块
- js 里的正则怎么像 Python 的 re 用()保留需要的字段?
- 求助,关于 spring 源码环境搭建。
- Nginx 在同一 vhost 的同一 server 内,想代理完全相同的 url 的后端盖怎么做?
| Posted: 21 Apr 2021 04:00 AM PDT 终于比 java 的版本号还高了。 | ||||||||||||||||||||||||||
| Android 项目多个 Jar 包有命名空间冲突,有办法解决吗? Posted: 21 Apr 2021 02:56 AM PDT 简单来说,同一个芯片的 SDK 被两个硬件组装厂家做了封装,我们的项目添加两个 Module 分别引用两个厂家封装后的 SDK(jar 、so),然后他们引用的芯片 SDK 就出现命名空间冲突了,而且他们用的芯片 SDK 版本还不一样,让厂家修改也不现实。 | ||||||||||||||||||||||||||
| 使用 vue-cli 创建的项目删掉 node_modules 之后再 npm i 会提示找不到 Python ,为什么 vue create 的时候不会有问题 Posted: 21 Apr 2021 02:56 AM PDT dart-sass 会用到 python | ||||||||||||||||||||||||||
| android studio build 报错,貌似是 gradle 版本问题,网上搜了方法没解决,有大佬帮看看吗? Posted: 21 Apr 2021 02:31 AM PDT
Deprecated Gradle features were used in this build, making it incompatible with Gradle 7.0. Use '--warning-mode all' to show the individual deprecation warnings. See https://docs.gradle.org/6.5/userguide/command_line_interface.html#sec:command_line_warnings BUILD SUCCESSFUL in 16s | ||||||||||||||||||||||||||
| 请问,自己独立的使用 Springboot+Mybatis+vue 写个博客网站,能找到 Java 开发的工作不. 害怕被面试官乱杀 Posted: 21 Apr 2021 02:22 AM PDT | ||||||||||||||||||||||||||
| 家人们, Python 在爬 https 的时候会出现一个少见的问题,是本地环境的问题吗? Posted: 21 Apr 2021 02:05 AM PDT Exception has occurred: URLError <urlopen error unknown url type: https> File "D:\pachong\pachong.py", line 2, in <module> urllib.request.urlopen('https://baidu.com') 报错代码如上 在爬取 http 的网站是没有这个问题的,一到 https 就会报错。 谷歌了很多,说需要配置这些:SSL 库也是有的(但是无法导入),openssl 库。 无果。 大家怎么看? | ||||||||||||||||||||||||||
| Posted: 21 Apr 2021 01:37 AM PDT gochat
微信 Go SDK (支付、公众号、小程序)
获取文档说明
Enjoy 😊 | ||||||||||||||||||||||||||
| Posted: 21 Apr 2021 01:32 AM PDT 不是简单模拟微信浏览器,这个设置一下 UA 就可以了,而是很多网站通过微信会员收费,只有通过微信公众号入口进入访问才能显示正确内容,请问一下这个技术实现细节?如何能够欺骗网站? 我想到的: 1 )微信 UA,这个容易模仿 2 ) http header:refer 网站,这个也可以吧 3 )获取订阅者 openid,这个假如我知道 openid,能否欺骗? | ||||||||||||||||||||||||||
| Posted: 21 Apr 2021 12:57 AM PDT 请教下大家,我之前处理过,加载图片,然后 OCR 识别出图片指定位置的文字,现在的情况不太一样,图片上文字的位置不固定,但是我知道上面文字的内容,当然也有其他文字,现在我想找到指定文字的位置,不知道可行否? | ||||||||||||||||||||||||||
| Posted: 21 Apr 2021 12:44 AM PDT yiigo
Go 轻量级开发通用库 Features
Requirements
InstallationUsageConfig
MySQLORM(ent)MongoDBRedisHTTPLoggerSQL Builder
DocumentationEnjoy 😊 | ||||||||||||||||||||||||||
| Posted: 21 Apr 2021 12:42 AM PDT 求各位老大指导一下,尝试了一下用 M1 芯片的 PD 安装 CentOS ARM 的时候,总是安装不上,也没有任何提示,返回跳转安装界面,不知道是咋回事儿,有了解的大佬求指导,谢谢! | ||||||||||||||||||||||||||
| 不太明白 writer.write() 和 writer.write() await writer.drain()有什么区别 Posted: 21 Apr 2021 12:06 AM PDT 文档: https://docs.python.org/zh-tw/3/library/asyncio-stream.html#streamwriter 不明白为什么要这么写, stream.write(data) await stream.drain() 个人理解 stream.write(data)本来就是非阻塞的,或者是什么场景下用 await stream.drain()呢 | ||||||||||||||||||||||||||
| 大家在学新东西的时候状态是怎样的,最近感觉自己忘的也太快了点 Posted: 21 Apr 2021 12:05 AM PDT 最近在学一些 JavaScrip Es6 的知识,主要是看阮一峰的文档。在看的时候基本上内容还是能搞懂的,但是有时候因为别的事隔了一天没看接着往下看的时候感觉之前的内容就已经忘了不少了。 在看 Promise 、generator 和 iterator 那几部分的时候尤为明显,有些概念交叉的时候经常得往回重新看看,仿佛和没看过似的。。。头疼 | ||||||||||||||||||||||||||
| github 上 android 项目,有 CI 工具可以自动编译 apk 并上传到 release 里面么 Posted: 21 Apr 2021 12:03 AM PDT 自己的一个小安卓项目,想在 github 上集成 ci 并在 commit 时自动编译并发布 apk 。有什么可靠的方法么? 在 github marketplace 上搜到了一些,但是不知道哪个坑比较少。有人做过类似的么? | ||||||||||||||||||||||||||
| Posted: 21 Apr 2021 12:00 AM PDT 我申请了试用好久都没通过, 想着有时候需要在 github 上直接编辑一些简单修改,但 github 网页修改一次只能一个文件就很坑, 这个 github codespaces 看起来应该能很好的做到在线修改多文件然后提交了吧, | ||||||||||||||||||||||||||
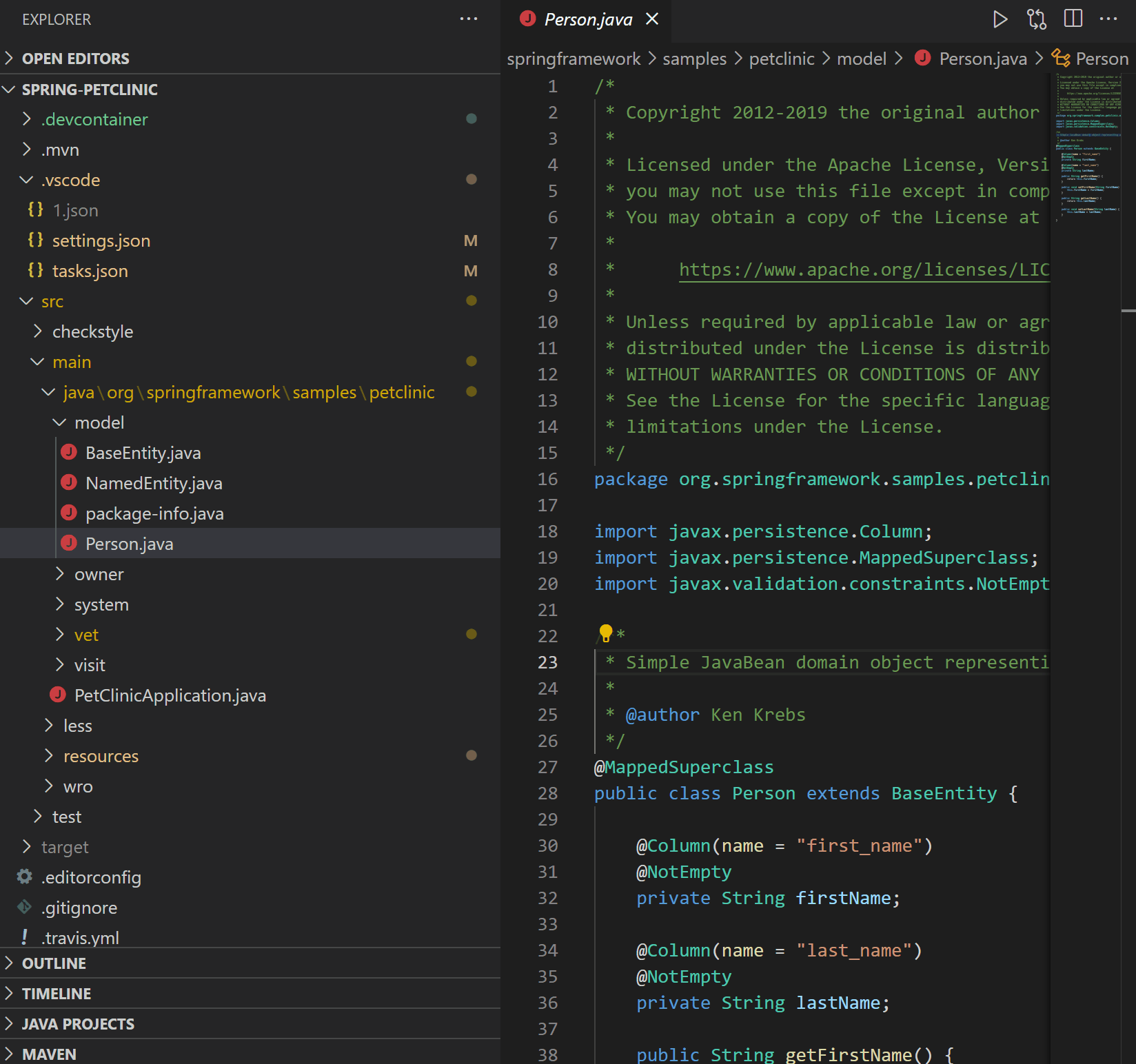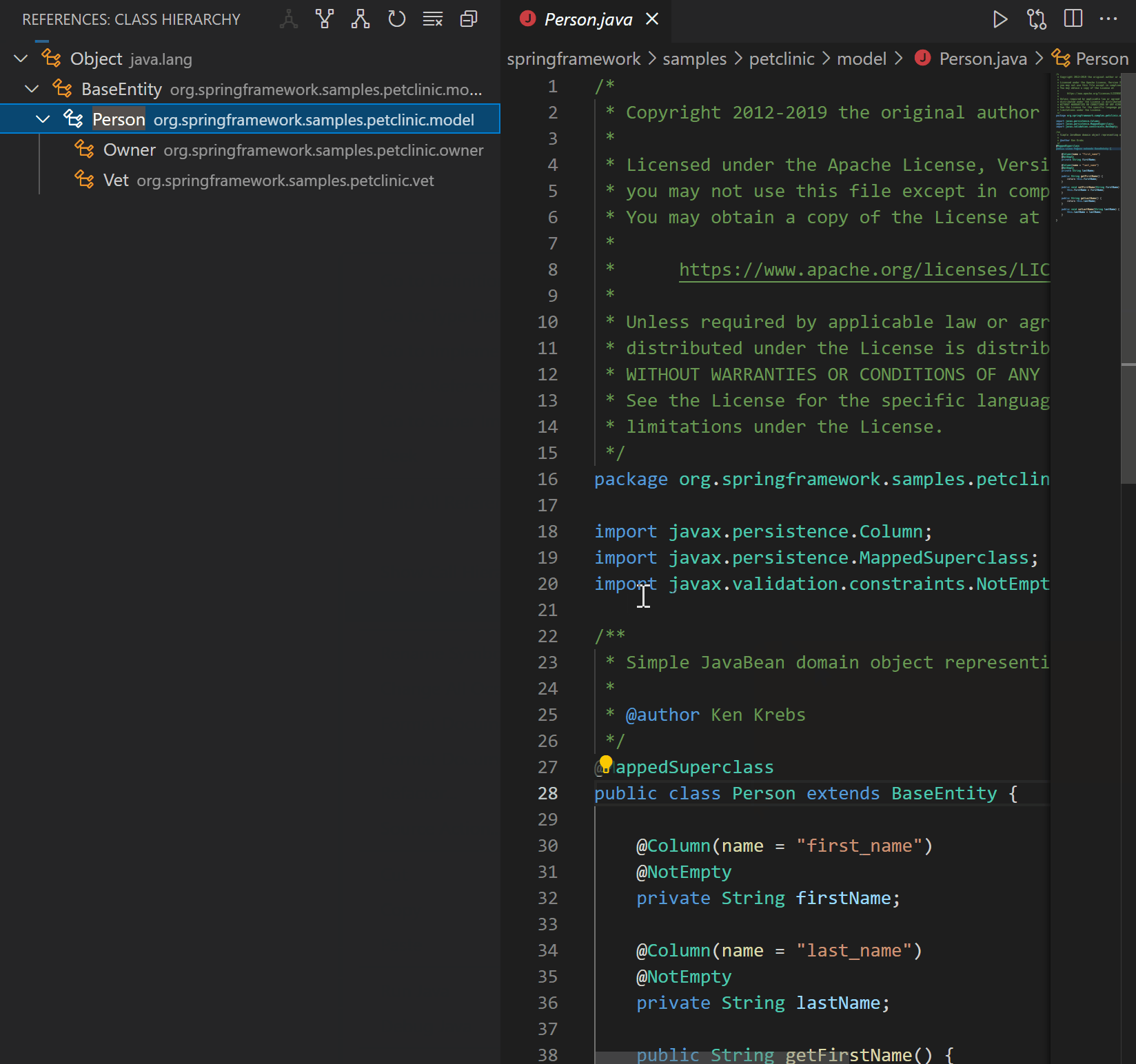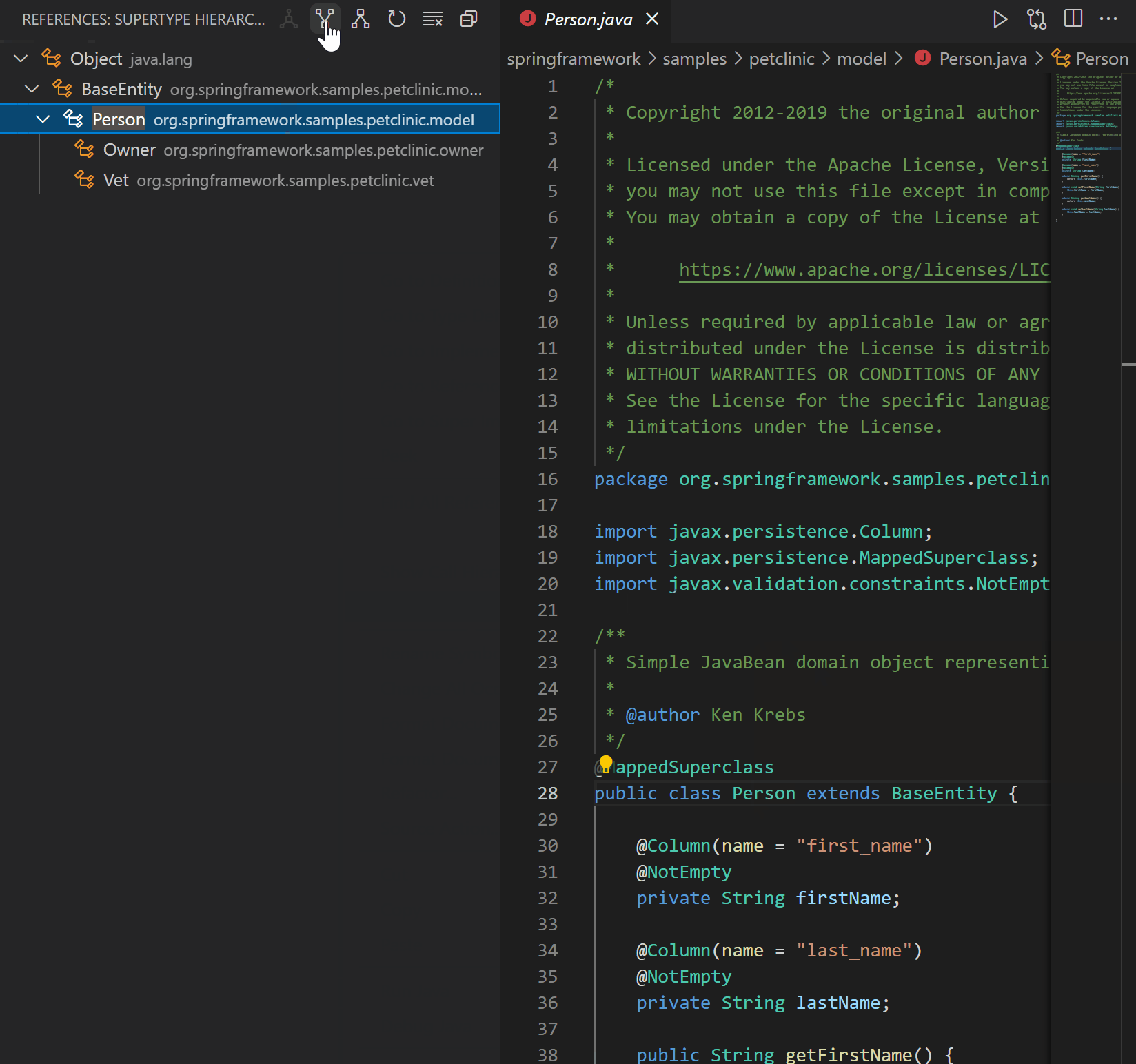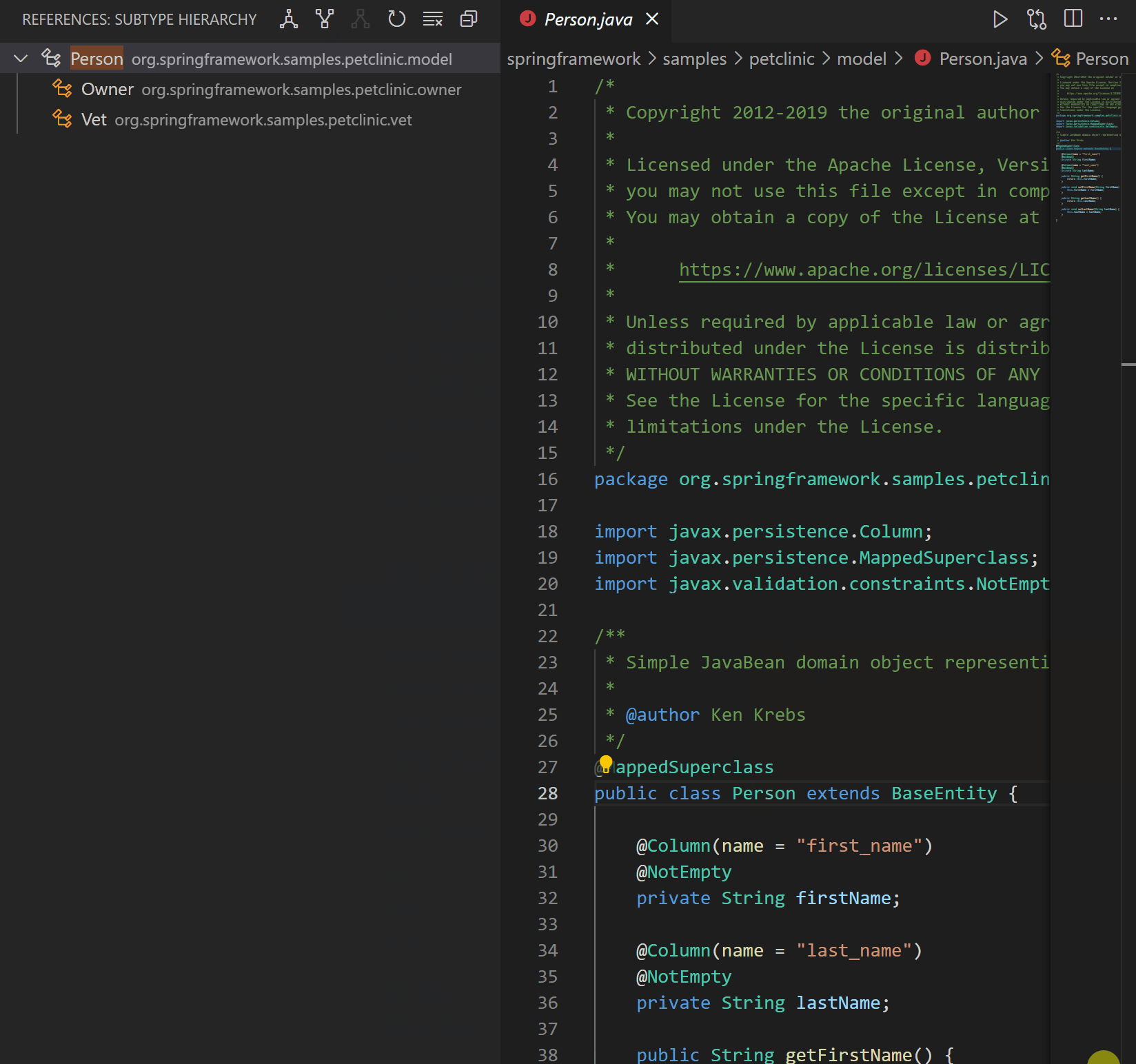
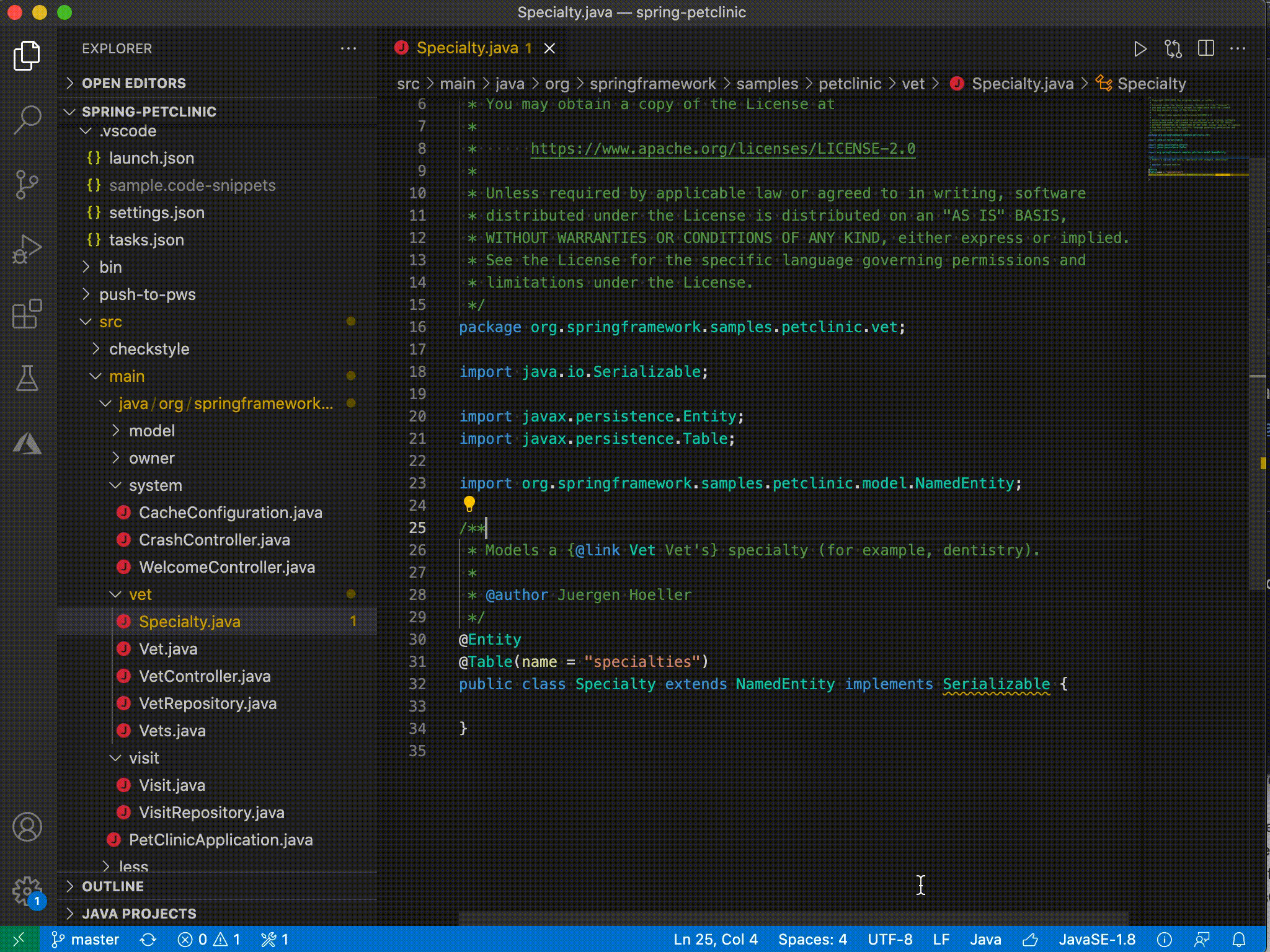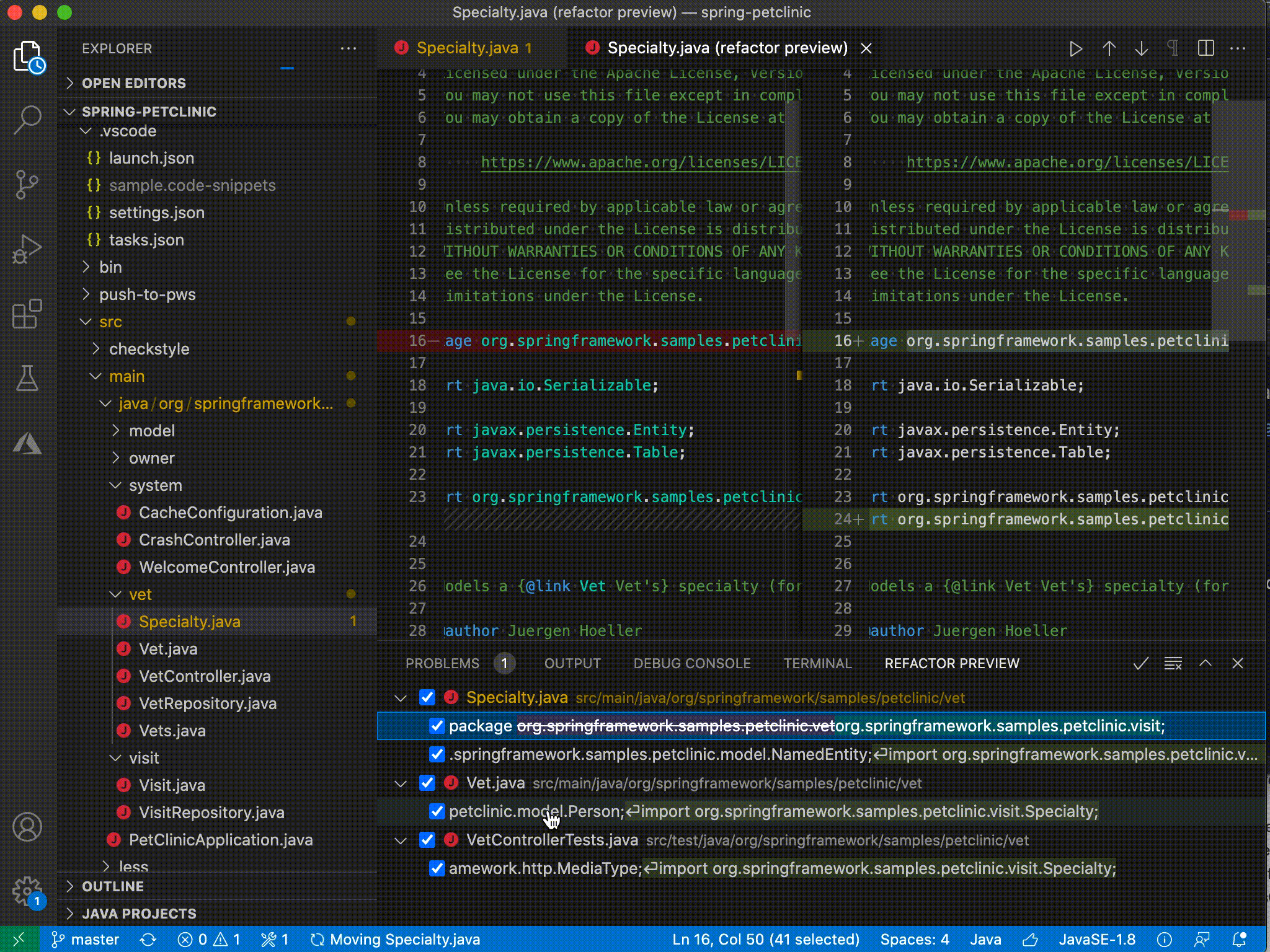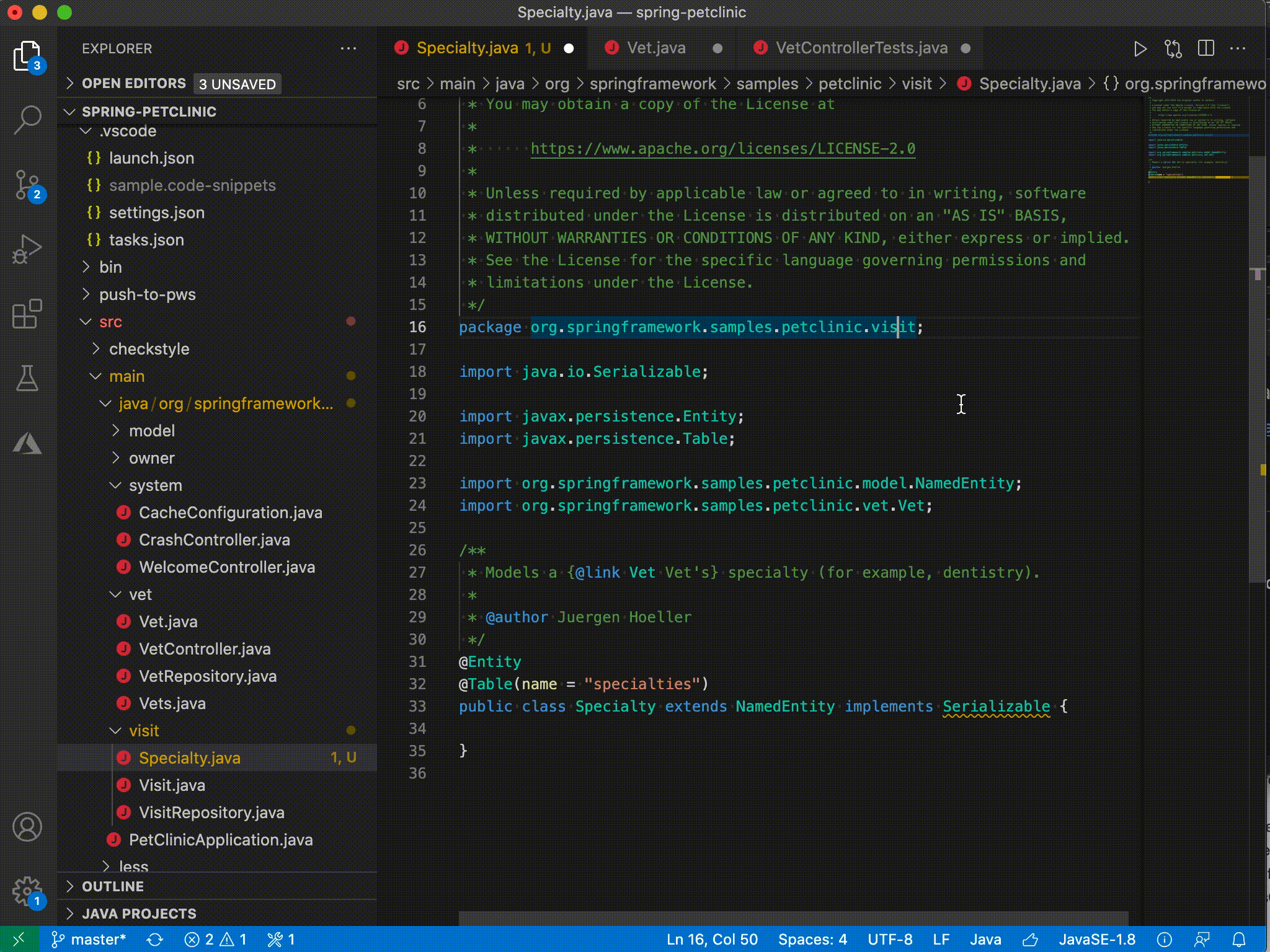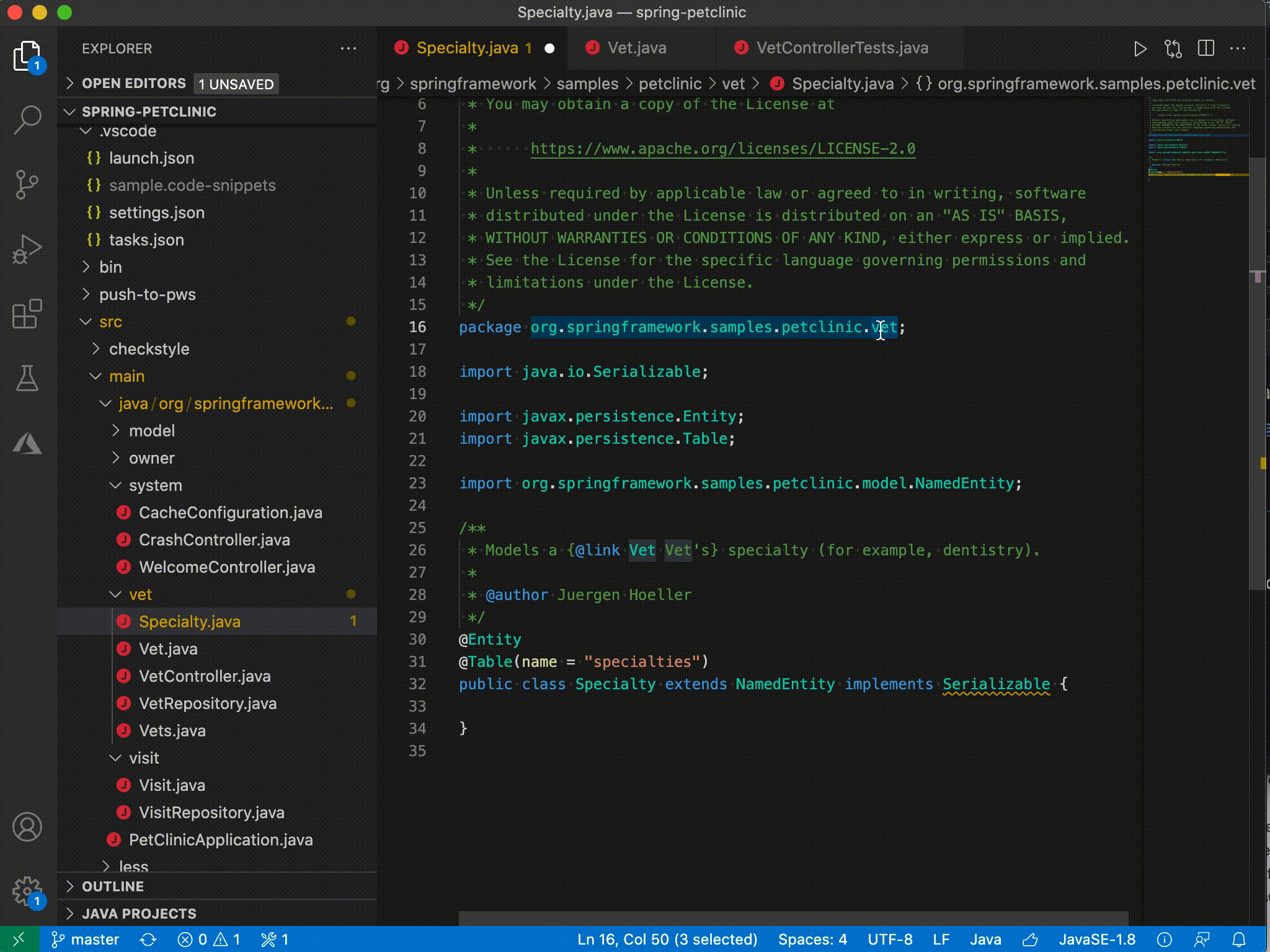
| Java on Visual Studio Code 的更新 – 2021 年 3 月 Posted: 20 Apr 2021 11:47 PM PDT 欢迎来到 Java 的 VS Code 更新。在过去的几个月中,我们的工程师一直在专注于一些非常重要的工作。现在,是时候揭开面纱了,开始吧。 类型层次结构(Type hierarchy)VS Code 已经支持 Java 的调用层次结构(Call Hierarchy),那么类型层次结构呢?我们与 Red Hat 一起非常高兴地宣布,由 Red Hat 发布的最新版本的Java 语言支持扩展已经支持浏览类型层次结构。 该功能使您可以在类,超类型或子类型视图中查看类型层次结构。
移动文件时的包重构我们知道很多开发人员都在等待此功能,当.java 文件从一个文件夹移动到另一个文件夹时,VS Code 可以自动更新包声明和导入语句。Red Hat 发布的最新版本的Java 语言支持扩展现在支持此功能。除了自动更新之外,该功能还允许您预览和撤消包更改。
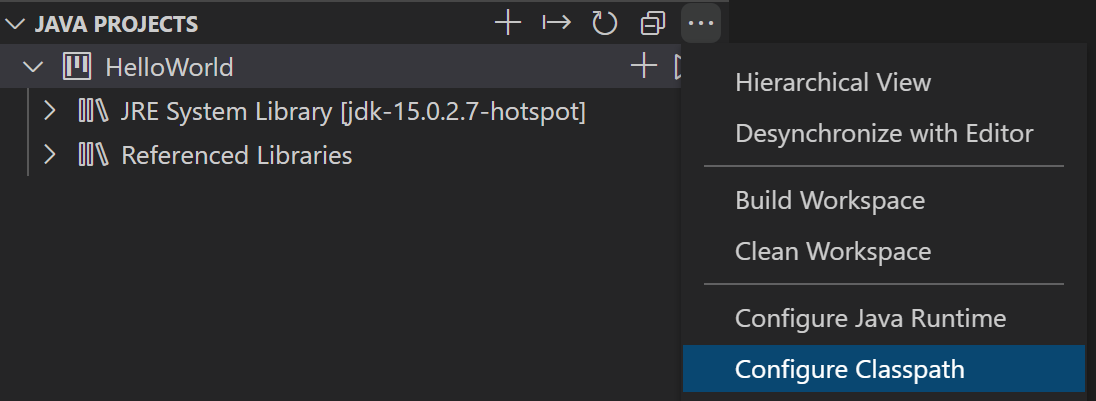
类路径配置(Classpath configuration)管理源代码,输出,运行时和库的路径是一项重要的项目管理任务,几乎每个 Java 开发人员都会执行。对于使用诸如 Maven 或 Gradle 之类的构建工具的人,这些工具允许通过其配置文件管理这些路径。但是,对于那些不使用构建工具的人,尤其是像学生,他们需要依赖 IDE /编辑器工具进行管理。为满足此需求,我们发布了类路径配置功能。 启动配置向导您可以从" JAVA PROJECTS"资源管理器中启动配置向导,也可以单击 Ctrl+Shift+P 打开命令选项板,然后在选项板上键入" configure classpath"。
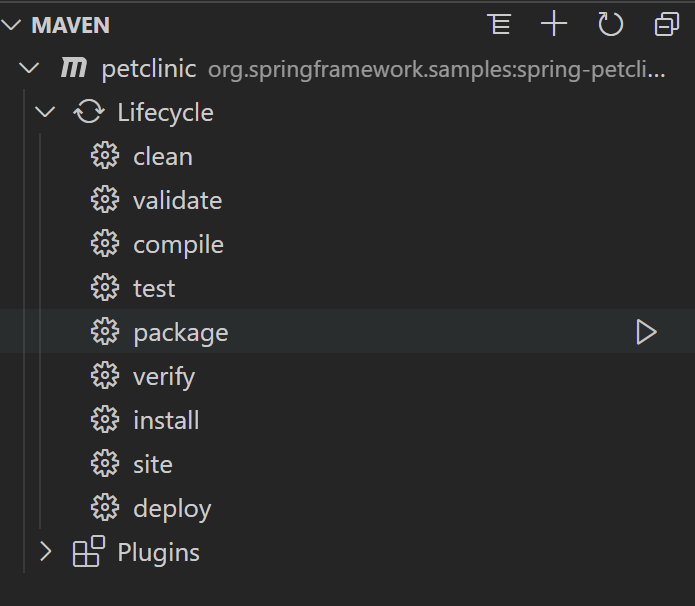
此功能作为Java Extension Pack的一部分发布, 请确保您已经安装了最新版本。 Maven 生命周期支持(Maven lifecycle)最新的Maven for Java 扩展支持 Maven 生命周期。现在,您可以通过单击阶段(phase)旁边的运行图标,直接从 Maven 资源管理器视图中执行常见的生命周期阶段。 [ 更多信息请不要犹豫,尝试一下!您的反馈和建议对我们非常重要,将有助于将来塑造我们的产品。
| ||||||||||||||||||||||||||
| InfluxDB (InfluxQL) 中如何按 tag 计算总和? Posted: 20 Apr 2021 11:42 PM PDT 假定有一个用于统计流量的表 traffic,格式如下 原始数据每秒提交一次,tx rx 是网络连接的累计字节数。目前已经实现了降采样和历史数据清理 现在想要统计每个用户的总字节数,累加后写入到另一个 device_traffic 表,请问要如何用 continuous query 实现呢? | ||||||||||||||||||||||||||
| Posted: 20 Apr 2021 11:34 PM PDT 目前没找到好用的 vscode 插件来管理 svn,只能切到 Cornerstone 进行操作。有 vscode 插件推荐吗? | ||||||||||||||||||||||||||
| Posted: 20 Apr 2021 11:18 PM PDT 我之前不是写过《面试官叫我手写 Redux 》系列文章嘛,现在我已将其录制成了视频课程! 课程名为《 Redux 源码专精》( 17 集完整版),现在全部免费观看! 目录
在哪里看?https://www.bilibili.com/video/BV1254y1L7UP 制作不易,只求一键三连! 看了有什么收获没什么很大的收获,也就是在面试的时候可以装装 X,问 Redux/redux-thunk/redux-promise 的时候直接说「我自己写过一个」。 | ||||||||||||||||||||||||||
| SpringSecurity 的无权访问异常理器 AccessDeniedHandler 与统一异常处理器 DefaultHandlerExceptionResolver 冲突 Posted: 20 Apr 2021 10:57 PM PDT 项目使用 SpringSecurity 进行 API 权限控制,在项目中实现了 AccessDeniedHandler 接口用于被拒绝时的异常处理: 并且在 WebSecurityConfigurerAdapter 的 http 配置中配置了异常处理: 项目中还是用了统一异常处理器 DefaultHandlerExceptionResolver: 问题来了,当无权访问时,并不是执行 MyAccessDeniedHandler (尽管它已经在 SpringSecurity 中已经注册异常处理器),这个异常始终会在 MyGlobalExceptionHandler 中处理,打印了堆栈信息和异常日志: 如何让无权访问的异常被 MyAccessDeniedHandler 捕获处理,而不是让统一异常处理器来处理 SpringSecurity 的无权访问异常呢? | ||||||||||||||||||||||||||
| Posted: 20 Apr 2021 09:51 PM PDT https://github.com/wenshunbiao/docker 好用给个 star 哦! 该项目主要是为了让你更加方便的使用 docker 服务,目前本人在开发环境,生产环境都在使用中,使用该服务,将使你避免重复搭建环境的烦恼,以及带来集中式,结构式管理目录的便捷。 刚开始可以使用虚拟机尝试体验。 | ||||||||||||||||||||||||||
| 如何能检测 Nginx 实际配置变更和配置变更备注的等价性? Posted: 20 Apr 2021 09:34 PM PDT 我们的 nginx 变更平台当前阶段最多通过 ansible 把 nginx.conf 拷贝到目标机器的临时文件夹上,然后用 nginx -t 验证一下配置,这样可以解决配置语法的问题。但是如果比如变更备注写的减少某个 upstream 的参与负载机器,结果有个兄弟不小心把配置文件该 upstream 机器全都注释掉了,就变成了 0 台机器了。但是这样可以通过 nginx 的语法检查。类似的这种例子还很多,比如 server_name 域名少打一位等等。我们现在 nginx 配置变更就相当于直接修改 http 块的配置,整个 http 里面的内容都直接编辑,然后通过模板渲染一些固定参数后推送,并没有把 nginx 的所有配置表单化,而且变更备注也没有做成表单化,这样带来的问题是,没法验证实际变更和备注里面的逻辑的等价性。但是把 nginx 配置完全表单化难度也不小,因为 nginx 配置文件里面也可以写 lua 脚本什么的,变更备注表单话也是比较复杂的,因为能变更的种类真的太多太多。但是如果不表单化想检查逻辑可能就要用 NLP 等技术去解析语义了,有点弄复杂了。大家这块有啥好的方法没? | ||||||||||||||||||||||||||
| Posted: 20 Apr 2021 07:57 PM PDT | ||||||||||||||||||||||||||
| Posted: 20 Apr 2021 07:43 PM PDT 目前只加了一个项目。 大佬们看看有没有什么问题,或者要补充啥得。 https://github.com/TianLiangZhou/ffi-pinyin | ||||||||||||||||||||||||||
| Posted: 20 Apr 2021 06:42 PM PDT 哪位大佬有 tinymce5 格式刷插件啊?不胜感激 | ||||||||||||||||||||||||||
| 全球首款消费级 Linux 平板 JingPad A1 视频已发布 Posted: 20 Apr 2021 02:28 PM PDT | ||||||||||||||||||||||||||
| Posted: 20 Apr 2021 02:22 PM PDT 根据网上的一些制作 magisk 模块的模板, 制作一个模块如果要对 apk 进行修改则只能用修改后的 apk 文件整体替换原文件. 一个 apk 文件可能会达到几十 MB, 但实际需要修改的可能只有几百 KB. 而且整体替换会因系统版本更新导致有几率变砖. | ||||||||||||||||||||||||||
| Posted: 20 Apr 2021 11:02 AM PDT 摘要
1. 线程池任务执行机制作为一个开发初始化线程池通常会使用 Executors 类,然后调用 newFixedThreadPool 或者其他方法来初始化一个线程池,方法如下: Executors 中其实最终是初始了 ThreadPoolExecutor 类,上一篇Java 线程池前传已经讲了 ThreadPoolExecutor 线程池的一些关键属性。 ThreadPoolExecutor 的构造方法中需要指定一些参数,并且这些参数会被线程池的一些属性所使用,这些我们会在后续的剖析线程池中都会提到。 1.1 任务调度任务调度是整个线程池的入口,当客户端提交了一个任务以后便进入整个阶段,整个任务的调度过程由 execute 方法完成,如下: 上述代码的执行过程大致如下:
其中 workerCountOf(recheck) == 0 这一步也很关键,这一步主要是为了确保线程池中至少有一个线程去执行任务。 在上述流程中我们提到了阻塞任务队列(用于任务缓冲)、addWorker 方法(任务申请)、以及 reject 方法(任务拒绝策略),下面我们再来分析一下这三个关键点。 1.2 任务缓冲线程池的本质是对线程和任务的管理,为了做到这一点必须要将线程和任务解耦,不再直接关联,通过缓冲队列恰好可以解决这一点。线程池中的缓冲队列类似于生产者消费者模式,客户端线程往缓冲队列里提交任务,线程池中的线程则从缓冲队列中获得任务去执行。 目前 Java 线程中的默认缓冲队列是阻塞队列模式,主要有以下几种,这些缓冲队列必须要实现 BlockingQueue 接口:
1.3 任务拒绝当工作线程数( workerCount )大于等于最大线程数( maximumPoolSize ),并且阻塞任务队列已满,线程池会执行具体的 RejectedExecutionHandler 策略。目前 Java 默认的拒绝策略主要有以下几种:
1.4 任务申请在工作线程池数未达到最大线程数并且阻塞队列未满时,我们可以将任务提交至线程池(有可能是开启新的线程,也有可能是将任务提交至阻塞队列)等待执行。其中 addWorker 方法便是开启新的线程执行任务。下面我们来看一下 addWorker 方法: 上述代码的核心逻辑就是根据线程池当前状态来决定是否开启新的线程来执行任务,线程具体的实现方式是采用一个 Worker 类来进行封装。 2. Worker 线程管理Worker 实现了 Runnable 接口,并继承了 AbstractQueuedSynchronizer ( AQS )。 不熟悉 AQS 的读者可以戳这里 2.1 Worker 线程的基本属性Worker 中存储了真实的线程( Thread )、该线程需要执行的第一个任务( firstTask )以及线程执行的任务数( completedTasks )。 2.2 Worker 线程为什么要采用 AQS 实现Worker 线程采用 AQS 实现,使用 AQS 的独占锁功能,通过其 tryAcquire 方法可以看出 Worker 线程是不允许重入的,Worker 线程有以下特点:
构造方法中为什么要执行 setState(-1)方法 ? setState 是 AQS 中的方法,默认值为 0,tryAcquire 方法是根据 state 是否是 0 来判断的,所以将 state 设置为-1 是为了禁止在执行任务前对线程进行中断,不明白的读者可以看一下 AQS 的 acquire(int arg)方法,如下: 构造方法中的 getThreadFactory().newThread(this)作用是什么? ThreadFactory 是在我们构造 ThreadPoolExecutor 时传入的,通过 ThreadFactory 我们可以设置线程的分组、线程的名字、线程的优先级、以及线程是否是 daemon 线程等相关信息。 2.3 Worker 线程工作Worker 线程获取任务工作是通过调用 ThreadPoolExecutor 中的 runWorker 方法,该方法的参数是 Worker 本身,下面我们看一下 Worker 线程的具体工作原理。 线程工作的大致流程是:
这里的 beforeExecute 方法和 afterExecute 方法在 ThreadPoolExecutor 类中是空的,留给子类来实现。 completedAbruptly 变量来表示在执行任务过程中是否出现了异常,在 processWorkerExit 方法中会对该变量的值进行判断。 此部分代码的流程图如下: 2.4 Worker 线程获取任务(getTask 方法)这里重要的地方是第二个 if 判断,目的是控制线程池的有效线程数量。由上文中的分析可以知道,在执行 execute 方法时,如果当前线程池的线程数量超过了 corePoolSize 且小于 maximumPoolSize,并且 workQueue 已满时,则可以增加工作线程,但这时如果超时没有获取到任务,也就是 timedOut 为 true 的情况,说明 workQueue 已经为空了,也就说明了当前线程池中不需要那么多线程来执行任务了,可以把多于 corePoolSize 数量的线程销毁掉,保持线程数量在 corePoolSize 即可。 什么时候会销毁? runWorker 方法执行完之后,也就是 Worker 中的 run 方法执行完,由 JVM 自动回收。 getTask 方法返回 null 时,在 runWorker 方法中会跳出 while 循环,然后会执行 processWorkerExit 方法。 获取任务的流程图如下: 2.5 Worker 退出(processWorkerExit 方法)3. 线程池关闭(shutdown)在 runWorker 方法中,执行任务时对 Worker 对象 w 进行了 lock 操作,为什么要在执行任务的时候对每个工作线程都加锁(lock)呢?
由上可知,shutdown 方法与 getTask 方法(从队列中获取任务时)存在竞态条件;
所以 Worker 继承自 AQS,在工作线程处理任务时会进行 lock,interruptIdleWorkers 在进行中断时会使用 tryLock 来判断该工作线程是否正在处理任务,如果 tryLock 返回 true,说明该工作线程当前未执行任务,这时才可以被中断。 | ||||||||||||||||||||||||||
| Posted: 20 Apr 2021 09:56 AM PDT 如上所示, 如果我在终端中使用 sudo python3 执行上面代码, 获取到的就是系统的环境变量. 我的有一个脚本是使用 root 权限启动的, 导致我获取到的环境变量是系统级别的环境变量, 那么我这边有没有什么 python 方法在 root 用户运行脚本的时候获取到这个"hello"的用户级别的环境变量呢, 各位大佬有方法么? | ||||||||||||||||||||||||||
| Posted: 20 Apr 2021 09:20 AM PDT 小白提问,不知道怎么搜索,求轻喷。 比如经常要用 我目前想到的是,在 感觉自己一直对 import 还有命名空间这一套东西比较迷惑,有比较好的解答文章也恳请赐教一个链接之类的~ | ||||||||||||||||||||||||||
| js 里的正则怎么像 Python 的 re 用()保留需要的字段? Posted: 20 Apr 2021 09:00 AM PDT 在 python 里我用 re.findall(r"\d+,\d+,-1,'(.*?)',(\d+),(\d+),'(\d+)-(\d+)'",xxx) 直接可以拿到列表 [ [元组] [元组] ] 和()里的可用元素 在 js 里我用, res.match(/\d+,\d+,-1,'(.*?)',(\d+),(\d+),'(\d+)-(\d+)'/); 不光括号里的拿到, 括号外的也拿到了,而且用 res[0][0]得不到一个元素,只能得到一个字符,怎么像 python 里 re.findall 那样方便的用在 js 里呢? 哪里有这样的教程呢? 菜鸟里面的 js 正则教程啥都没写 | ||||||||||||||||||||||||||
| Posted: 20 Apr 2021 08:23 AM PDT 从 github 下载的 spring 源码后,执行.\gradlew build 并去除 aspect 模块导入到 idea 里面后,新建自定义 moudles 无法导入 spring 组件。(环境) gradle-6.8.3,jdk-8.0.282,idea 2019.2.4 | ||||||||||||||||||||||||||
| Nginx 在同一 vhost 的同一 server 内,想代理完全相同的 url 的后端盖怎么做? Posted: 20 Apr 2021 08:09 AM PDT 比如配置一个 server,监听了 443 端口,代理了 3 个 url 完全相同的后端(比如代理了 3 个 grafana:a 、b 、c ),因此我们想在访问 nginx 时 url 加上一个特别文根区分它们,比如 https://172.16.103.14/a/代表访问后端 a 的 grafana,以此类推。但是我们发现当我们加上这个标识后,比如请求 grafana 的 a 服务器会返回个重定向到 https://172.16.103.14/login,但是我们的 nginx 不能配上 /login 这个文根,因为三个后端是相同的,无论我访问 /a 、/b 还是 /c 都会重定向到 login,这样就没法区分到底应该访问哪个后端了。大家有啥办法吗? |





| You are subscribed to email updates from V2EX - 技术. To stop receiving these emails, you may unsubscribe now. | Email delivery powered by Google |
| Google, 1600 Amphitheatre Parkway, Mountain View, CA 94043, United States | |
No comments:
Post a Comment